SQL Server: Real Time Data Streaming Using Apache Kafka
Introduction
The inspiration for this post comes from the fact that in recent times the need for real time data streaming from SQL Server RDBMS has been an important aspect for many projects. There are multiple ways to do this.
This article deals with one of the popular ways in which this requirement can be achieved.
Scenario
The scenario on hand requires data from an application database hosted in SQLServer to be streamed in real time so that it can be used for scenarios like synchronizing between multiple systems, operational reporting requirements etc.
Apache Kafka is a popular streaming tool which can be used for this type of requirements. The SQLServer data will be streamed using a topic created in Apache Kafka.
Illustration
For illustrating the above scenario, the below setup would be used
- SQL Server 2017 instance hosted on Ubuntu Linux server
- An Apache Kafka instance for creating a streaming topic
- An Apache Kafka connect instance for connecting to database instance
For the ease of setting up the above environment, dockerized containers are used.
The first part of this article series deals with how SQLServer sample instance can be setup using Linux based docker
Setting up SQLServer Instance on Linux
Dockerized containers can be installed through docker environment and it will have all the necessary configurations and the environment setup for the software to work.
The official docker image for SQLServer can be found in the below link
https://hub.docker.com/_/microsoft-mssql-server
For the sake of this illustration the SQL 2017 docker image is selected
The steps to create the docker are explained clearly in the above link. This being SQL Server instance setup in Linux server, the connection can be checked using command line tool SQLCMD
One thing to be careful while creating the image using docker run statement is the port to be configured for the SQLServer instance.
The port is set using –p switch and is of the form host port:container port so if its 1433:1433 it means port 1433 of the host machine is mapped to 1433 port of the docker which is the standard SQLServer port. This is fine for the illustration purpose but in actual case it makes sense to use a non-standard port in the host machine to map to standard sqlserver port to avoid any possible injection attacks.
In order to check on the status of the instance, the docker container needs to be first identified using docker ps command

From the above screenshot it can be seen that the container for the above illustration is named as flamboyant_varahamihira.
This is not always constant and has to be checked each time a docker image is setup.
The password for SA account can be check from within docker container using below commands
docker exec -it <container_id|container_name> bash
This will enter the bash terminal for docker image
Then use the below
echo $SA_PASSWORD
And the SA password will get displayed
Use it to login to the instance and ensure its up and in running state
The password should be used in the below command to check on the status of the SQLServer instance
/opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P <your_password>
And assuming the connection was successful, the sqlcmd prompt will appear as shown below
Just type any sql command on the prompt and add a GO to get it executed
As an example, get version information like this
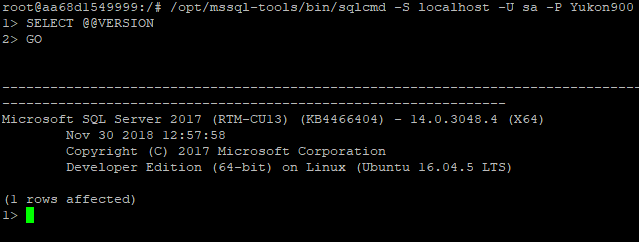
The image given in the link also includes an initiation script (entrypoint.sh) which creates a sample database named DemoData and creates a table Products within it.
The DockerFile which builds the docker image will call this shell script at the end of the build to execute commands written inside It.
The contents of the shell script can be checked by using the below command
cat /usr/src/app/entrypoint.sh
On Analysis, the entrypoint.sh file can be found to contain the below code

The import-data.sh file would contain the script to create the sample database and table and populates the data within it. Based on the requirement more parts can be added to the script.
The import-data.sh includes scripts to create a sample database, a table called Products inside it and populate it with some sample data
The script looks like below

The first command waits for the SqlServer service to come up
The next command uses SQLCMD to login to the instance and execute the setup.sql script which looks like below to create the sample database
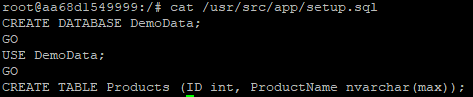
Finally, it executes the bcp utility to populate the table Products with some sample data from the included csv file within the docker
Now that instance is up with the database and table setup with some sample data, the next attempt is to try connecting to the instance using a client tool like SQL Management Studio (SSMS)
For this purpose a windows based laptop with SSMS installed was used
Launch SSMS and give IP or name of the server to connect. Ensure TCP/IP is selected as the protocol
The instance will get connected and the object explorer will show the demo database with the list of objects created in the database.
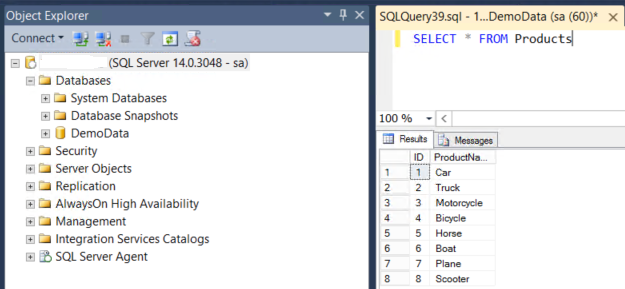
The above screenshot shows the object created along with the data populated using the shell script executed from docker
Setting up Apache Kafka
The next step is to set up the Kafka server which can be used to stream the SQLServer data.
Kafka can be used to stream data in real time from heterogenous sources like MySQL, SQLServer etc. Kafka creates topics based on objects from source to stream the real time data. This data can then be used to populate any destination system or to visualize using any visualization tools.
For the sake of this illustration, the docker container for kafka and kafka connect from below project are used
https://github.com/confluentinc/demo-scene/tree/master/no-more-silos
Once the dockers are up and running, the status can be checked using below script
docker ps
And the below result will get displayed

Kafka is used for creating the topics for live streaming of RDBMS data. Kafka connect provides the required connector extensions to connect to the list of sources from which data needs to be streamed and also destinations to which data needs to be stored
The flow diagram for the entire setup looks like this
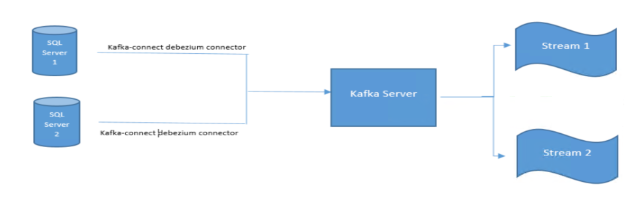
The Kafka connect server makes use of Debezium based connectors to connect to the source databases in the given illustration. Changes within each SQLServer source table will be published as a topic inside Kafka.
There are two general ways of capturing data changes from RDBMS systems.
- Query based CDC
- Log based CDC
JDBC based connector is available for SQLServer to capture query based CDC. For utilizing log based CDC, Debezium has released a set of connectors for various RDBMS including SQLServer. For the sake of illustration, Debezium based connectors are used to avoid direct impact on the transactional tables.
Debezium makes use of the CDC feature for picking up the changes happening at source. For this reason, CDC feature has to be enabled at server instance and table level for Debezium connectors to work.
The below document give detailed information on how CDC can be enabled at instance and table level in SQLServer
CDC feature requires SqlAgent service to be up and running within the SQLServer instance.
In Linux based servers, the below approach can be used to enable SQLAgent service within the SQLServer instance.
/en-us/sql/linux/sql-server-linux-setup-sql-agent?view=sql-server-ver15
Streaming SQLServer Data
Now that the setup is done, the next stage is to get data streamed from the SQLServer instance based on the DML changes happening.
Since Debezium relies upon CDC data from SQLServer, the connector has to be setup prior to populating any data to the table. So assuming the instructions in the first part of this article is followed; the table has to be cleared and data needs to be populated again after CDC is enabled and the Debezium connector is being setup so as to allow the capture instance (CT table) to pick up the changes and the connector to stream them through the created Kafka topic.
The steps below outline how the setup that has to be done prior to capturing the data changes
- Enable CDC at the SQLServer instance database level using sys.sp_cdc_enable_db system procedure
- Create the required table and enable CDC at the table level using sys.sp_cdc_enable_table system procedure
- Create a topic for holding history info inside Kafka server ( sshist_Products)
- Setup the Debezium based connector for streaming the data changes captured through CDC capture instance
- The connector can be setup using the below code executed from Linux terminal
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/sqlserver-product-test/config -d '{"connector.class":"io.debezium.connector.sqlserver.SqlServerConnector","database.user":"sa","database.dbname":"DemoData","transforms.unwrap.delete.handling.mode":"rewrite","database.history.kafka.bootstrap.servers":"kafka:29092","database.history.kafka.topic":"sshist_Products","transforms":"unwrap,route","database.server.name":"sstest","database.port":"1433","table.whitelist":"dbo.Products","transforms.route.type":"org.apache.kafka.connect.transforms.RegexRouter","transforms.route.regex":"([^.]+)\\.([^.]+)\\.([^.]+)","database.hostname":"<IP Address>","database.password":"<Password>","transforms.unwrap.drop.tombstones":"false","transforms.unwrap.type":"io.debezium.transforms.UnwrapFromEnvelope","transforms.route.replacement":"sqlserv_$3"}'
Once created the connector status can be checked using below command
curl -s "http://localhost:8083/connectors"| jq '.[]'| xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
Result would be displayed as per below screenshot

Which indicates that the connector as well as its associated task is running fine
- Populate the table with some data
The below script populates the table Products with some test data
USE [DemoData]
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (1, N'Car')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (2, N'Truck')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (3, N'Motorcycle')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (4, N'Bicycle')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (5, N'Horse')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (6, N'Boat')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (7, N'Plane')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (8, N'Scooter')
GO
INSERT [dbo].[Products] ([ID], [ProductName]) VALUES (10, N'Test Product 25 Jan')
GO
- Check in kafka server for the associated topic and ensure it contains the DML changes applied so far
This can be done using below command
docker exec -it no-more-silos_kafka_1 kafka-console-consumer --bootstrap-server kafka:29092 --topic sqlserv_Products --from-beginning
The result will be displayed as below
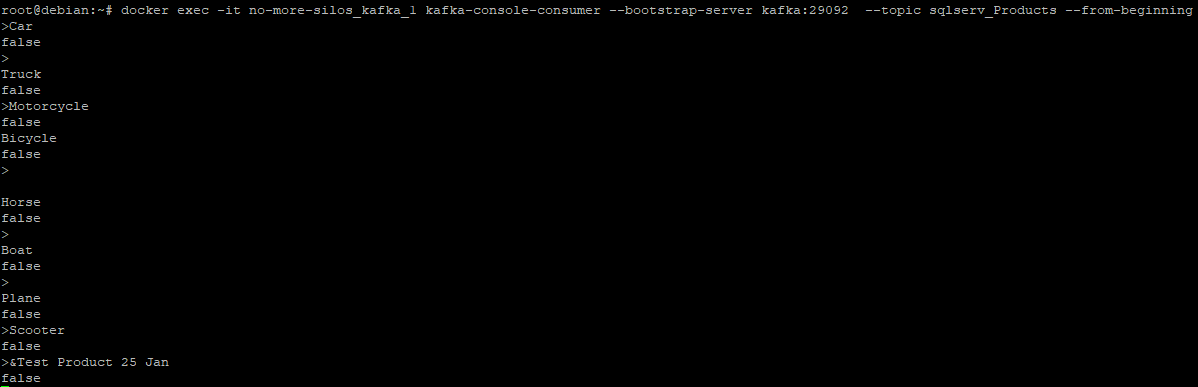
This indicates that Kafka topic is created based on the data from the specified table and it keeps transmitting the DML operations happening on the table as a continuous stream by means of the CDC feature enabled in SQLServer.
To illustrate the continuous close to real time streaming of data, some DMLs shall be applied to the source table whilst monitoring the stream.
A data modification DML is applied at first to see how stream captures it
UPDATE [dbo].[Products]
SET ProductName = 'Hovercraft'
WHERE ID = 10
Recheck the topic and notice that the new DML change has been picked up by the stream
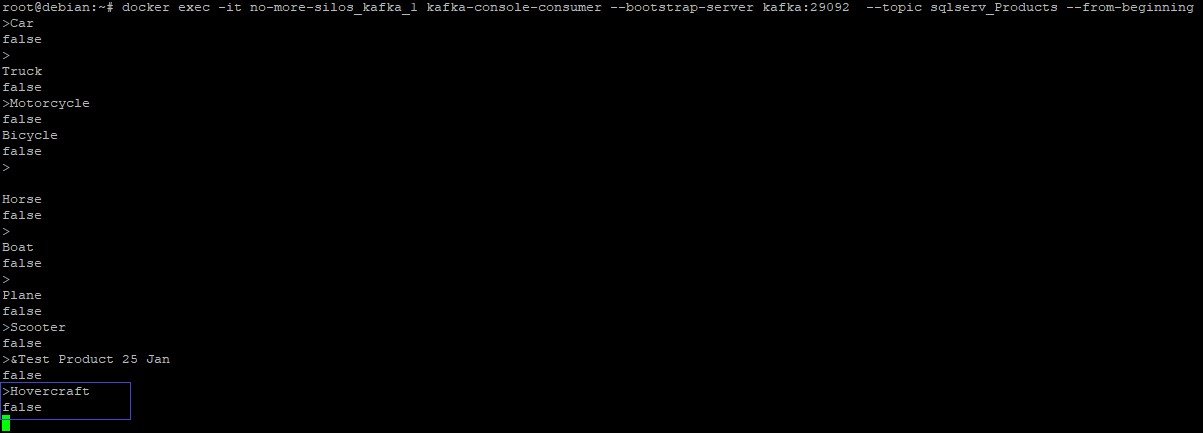
Similarly data deletion can be done and see how the topic picks up the change
DELETE FROM [dbo].[Products] WHERE ID = 4 ;
DELETE FROM [dbo].[Products] WHERE ID = 5 ;
And this time result can be checked from another platform, K-SQL server, which is part of the project. KSQL helps to build streams and tables over Kafka topics and will integrate with Kafka to ingest topics as objects within it.
The topic can be reviewed using PRINT command in K-SQL
SET 'auto.offset.reset' = 'earliest'; PRINT 'sqlserv_Products' FROM BEGINNING;
The first command ensures it always starts displaying from start of the stream
The result would be displayed as below
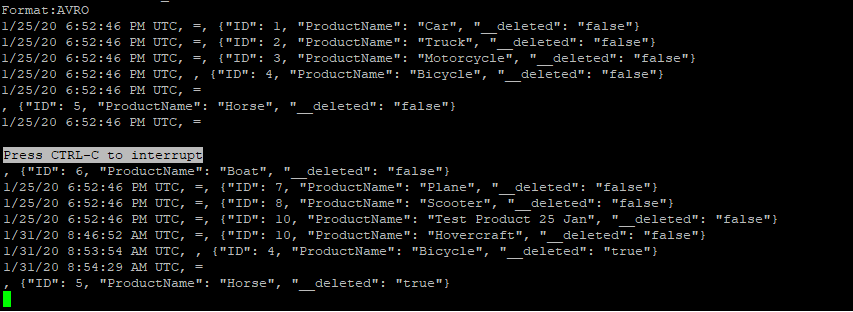
The result in this case would be in JSON format and will show details of columns and their values as Key Value pairs. A boolean key __deleted in the end indicates whether the entry was a deletion entry. For each modification stream includes a new JSON entry by virtue of SQL Server’s CDC feature.
The format used for serializing values would be AVRO format which includes the schema definition as well as the actual values. The first two fields are system generated (ROWTIME and ROWKEY) which identifies each message within the stream corresponding to each of the row affected by the DML changes
Conclusion
As per the above illustration we have seen the below
- Setting up SQL Server instance through a dockerized container in Linux environment
- Integrating SQL Server to Apache Kafka streaming platform using Debezium connectors and Kafka Connect through SQL Server’s CDC feature
- Publishing SQL Server table DML changes through a Kafka topic close to real time
- Monitoring Kafka topic stream data using Kafka’s command line and K-SQL server options
This article should provide an end to end solution for the use cases requiring close to real time data synchronization or visualization of SQL Server table data by capturing the various DML changes happening on the table.