How to Write Streaming Data into Azure Databricks Data Table
Azure Databricks is the modern way of doing Big Data Processing in Azure. The platform allows you to create Apache spark cluster and process Big Data including live streams. In this article, I am going to explain you, how to write stream data into Data Bricks Table.
If you are new to Azure Databricks you can follow the link to learn about Azure Databricks. If you like to get started with Azure Databricks please follow the TechNet Wiki articles on,
How to Create an Azure Databricks Workspace
Azure Databricks: How to Create Cluster
Azure Databricks: How to Get Started to Work with Data
I tried to ingest data from Twitter and using Azure Cognitive Services to pass raw twitter feeds and get the sentiment of it. I followed the same steps in this MSDN document, Sentiment analysis on streaming data using Azure Databricks, which is pretty much straight forward and really hard to get things wrong here.
I’ll explain this as a continuation of the tutorial on how to write streaming data into the Databricks SQL Table. In general, you can Read-Write data in Batch wise or streaming. You can have a detailed understanding of it if you are looking into the Azure Databricksdocumentation. In this article, I'm only focused on Stream Writes. In the original documentation, it explains extract the sentiment and display in Databricks console. Please find the below code for write data into Parquet format and later into the Databricks Table.
Parquet is a columnar format that is supported by many other data processing systems including Apache Spark.
// Prepare a dataframe with Content and Sentiment columns
val streamingDataFrame = incomingStream.selectExpr("cast (body as string) AS Content").withColumn("Sentiment", toSentiment($"Content"))
// Display the streaming data with the sentiment
//streamingDataFrame.writeStream.outputMode("append").format("console").option("truncate", false).start().awaitTermination()
// Write streaming data into Parquet File format
import org.apache.spark.sql.streaming.Trigger.ProcessingTime
val result =
streamingDataFrame
.writeStream
.format("parquet")
.option("path", "/mnt/TwitterSentiment")
.option("checkpointLocation", "/mnt/temp/check")
.start()
// Read data from Parquet files
val sentimentdata = spark.read.parquet("/mnt/TwitterSentiment")
display(sentimentdata)
// Write Parquet data as a Data Table in Databricks
spark.read.parquet("/mnt/TwitterSentiment").write.mode(SaveMode.Overwrite) saveAsTable("twitter_sentiment")
In this code block, first I'm writing live twitter streams to parquet format. Actually, you can browse the DBFS Databricks File System and see it.
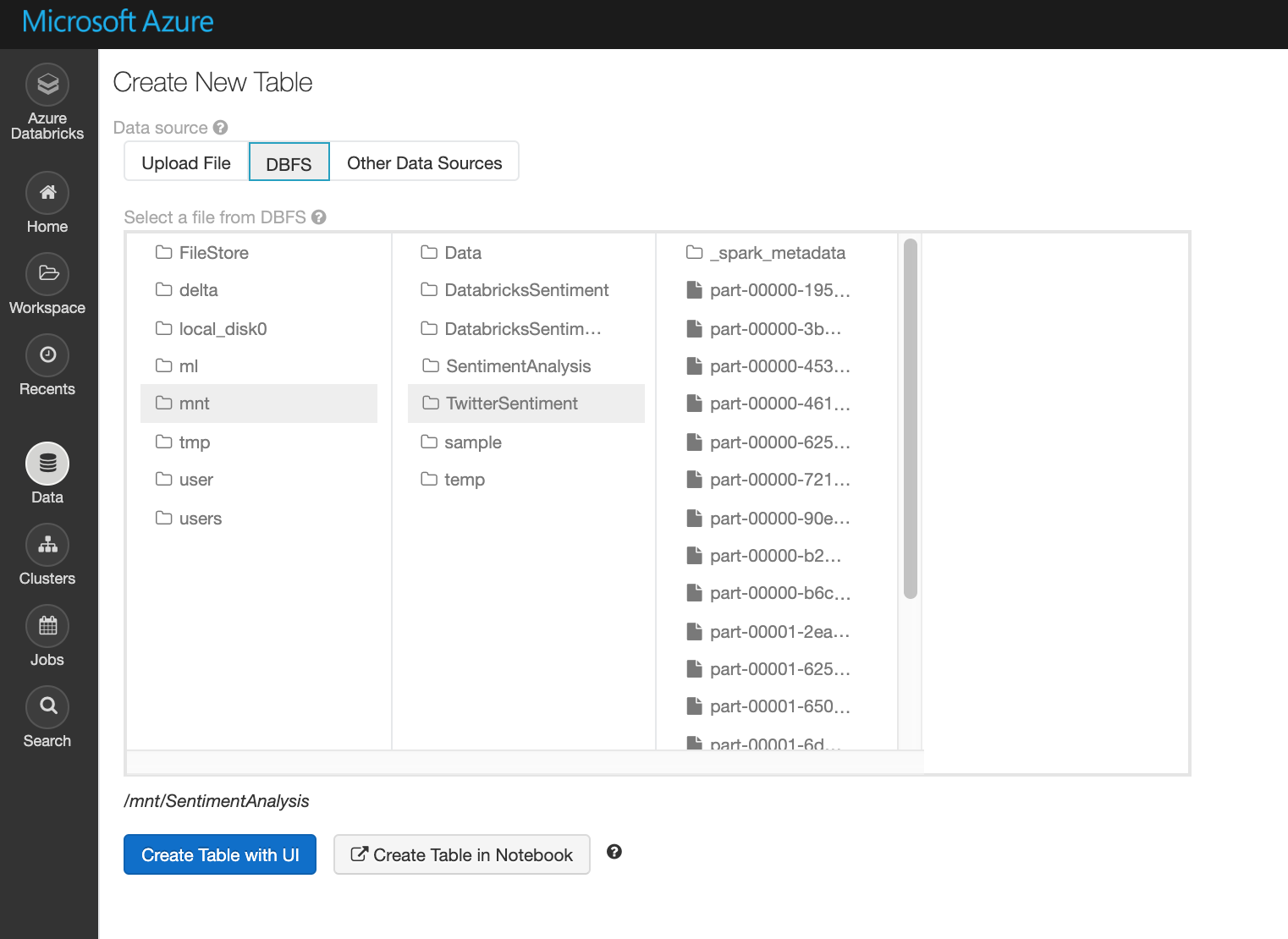
In the last like I've done read parquet files in the location mnt/TwitterSentiment and write into a SQL Table called Twitter_Sentiment.
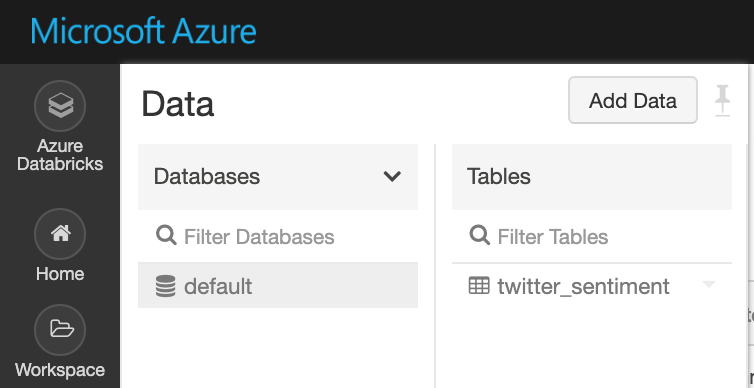
You can see the table is created by going to Data tab and browse the Database.
By double click the table you can view the data on it.
[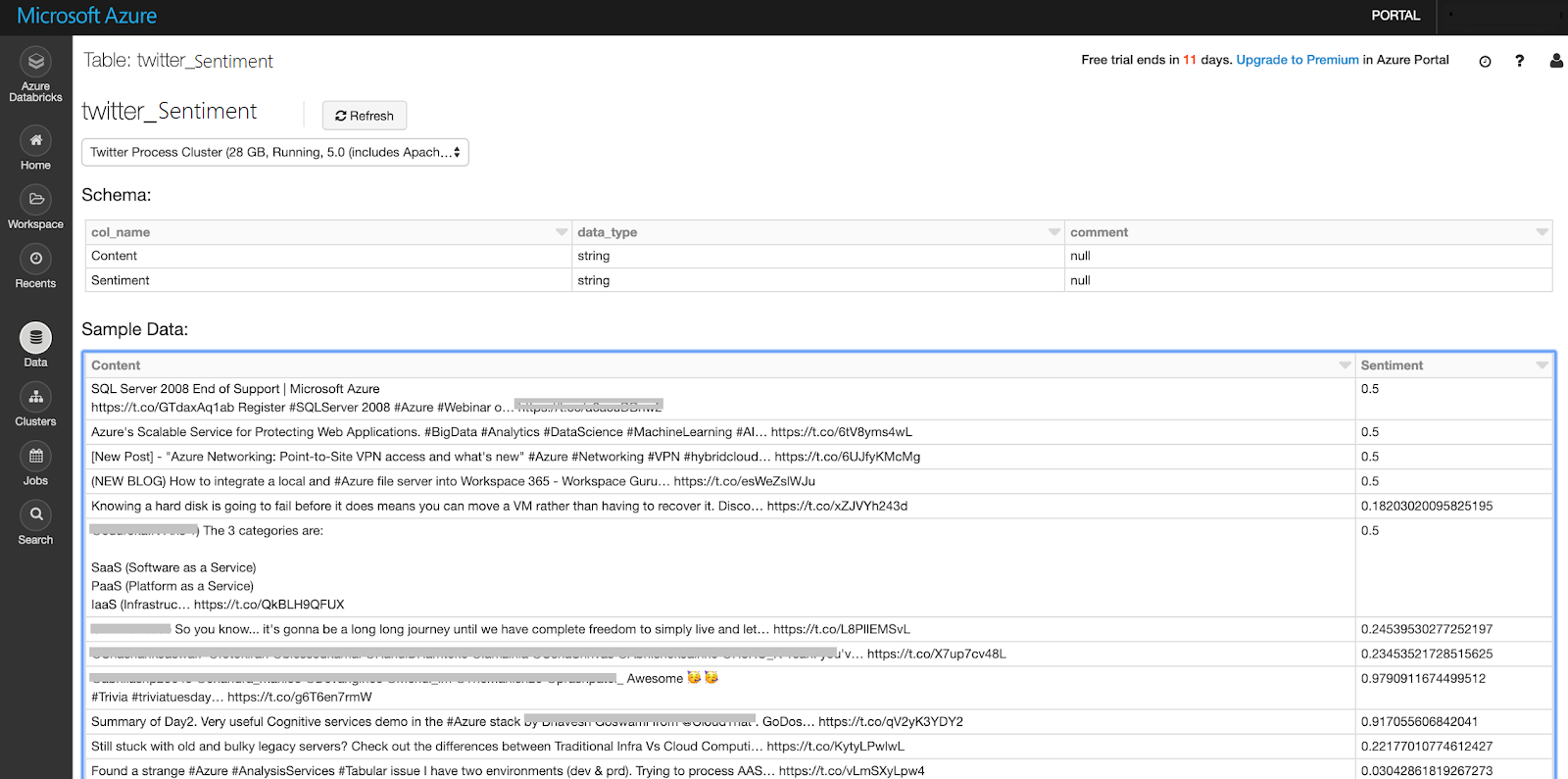
](resources/0412.Write-Table.png)Summary
I hope you learn how to write stream data frame into a table in Azure Databricks. This enables you to do advanced analysis and visualization on it.
References
https://docs.databricks.com/delta/delta-streaming.html
https://spark.apache.org/docs/latest/sql-data-sources-parquet.html