Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Overview
String columns in columnstore indexes in general work quite well. You get the benefit of column-based format and compression, which is excellent for string columns with small numbers of distinct values. String filtering can be done in batch mode, which normally performs quite fast. There are some performance issues associated with joining on strings and with filtering on strings. These are discussed separately below.
Performance Issues Related to Joining on String Columns
The biggest performance limitation with string columns in columnstores in SQL Server 2012 tends to be seen when you join on them.
For example, consider a database with a 101 million row table dbo.Purchase which has a columnstore index on it. This table records information about movie ticket sales. One of the columns is PriceRetailCurrency, which is of type nvarchar(50). This column has only 8 distinct values. Suppose that a business analyst creates a “study group” of currencies for investigation, and puts it into a table like this:
create table CurrencyStudyGroup(Currency nvarchar(50));
insert into CurrencyStudyGroup values(N'Euro');
insert into CurrencyStudyGroup values(N'British Pound');
Given the sub-second response time we usually see when querying dbo.Purchase with a columnstore index on it, the following query doesn’t perform as well as expected, requiring 7 seconds to run on a 4-core processor:
-- Query Q1
select p.PriceRetailCurrency, count(*)
from dbo.Purchase p, CurrencyStudyGroup c
where p.PriceRetailCurrency = c.Currency
group by p.PriceRetailCurrency;
Interestingly, the query plan for the above query does almost all its work in batch mode. The plan is as follows (click to expand):

There are a couple of reasons this plan doesn’t run as fast as expected. One is that the join filter does not get pushed down into the columnstore scan, so every row of the Purchase table must be streamed out and passed through the join. The second is that the internal handling of the join comparisons on strings is not as efficient as it is for integer join columns.
You can work around this issue in at least two ways. The first and most recommended approach is to simply remove string columns from your fact tables by normalizing the strings out into dimension tables, or completely encoding them into integers. For example, you could create a dimension table DimCurrency as follows:
create table DimCurrency(CurrencyId int not null, Currency nvarchar(50) not null);
Then you would add rows to this table for each currency.
You would also replace the PriceRetailCurrency column of Purchase with a column PriceRetailCurrencyId of type int. You would then modify the CurrencyStudyGroup table to include not just the currency names, but also their IDs. We can call this table CurrencyStudyGroup2. We could create it like this, for example:
select *
into dbo.CurrencyStudyGroup2
from dbo.DimCurrency d
where d.Currency in (N'British Pound', N'Euro');
Now, to create a query equivalent to the query Q1 above, you could do the following:
select d.Currency, count(*)
from dbo.Purchase p, dbo.CurrencyStudyGroup2 d
where p.PriceRetailCurrencyId = d.CurrencyId
group by d.Currency
This query runs almost completely in batch mode and is very efficient. It will run in subsecond time.
A second way to limit the performance drawbacks of filtering and joining on strings in columnstore indexed tables is to change your application to encode the string information completely into an integer. This might be feasible, for example, if you had a string column ZipPlus4 of the form ‘DDDDD-DDDD’. You could instead encode it as a 9-digit int column and just know that by convention, the first 5 digits are before the hyphen and the last 4 digits are after the hyphen. Similarly, if you have a string column with phone numbers encoded like ‘(DDD) DDD-DDDD’ then you could instead encode that as a 10-digit bigint column.
This strategy may work depending on the type of data you have, but it’s not always applicable. If it doesn’t apply then consider the approach of adding a special dimension table instead, and replace the strings with an integer surrogate key.
Performance Issues Related to String Filters
String filters on a columnstore indexed table, where you apply a filter containing string literals directly to a string column that is contained in the index, do not get pushed down into the columnstore index scan operator in the storage engine. Usually this is not a problem. The string filter operations still can work in batch mode and are typically quite fast.
As an example, consider this query:
select d.YearNum, d.MonthNumOfYear, m.Category,
SUM(p.PriceRetail) as PriceRetail, COUNT(*) as [Count]
from dbo.Purchase p, dbo.Date d, dbo.Media m
where p.MediaId = m.MediaId
and d.DateId = p.Date
and m.Category in ('Horror', 'Action', 'Comedy')
and p.PriceRetailCurrency in ( N'British Pound', N'Euro')
group by d.YearNum, d.MonthNumOfYear, m.Category
order by m.Category, d.YearNum, d.MonthNumOfYear
The query plan for this query has a section like the following:
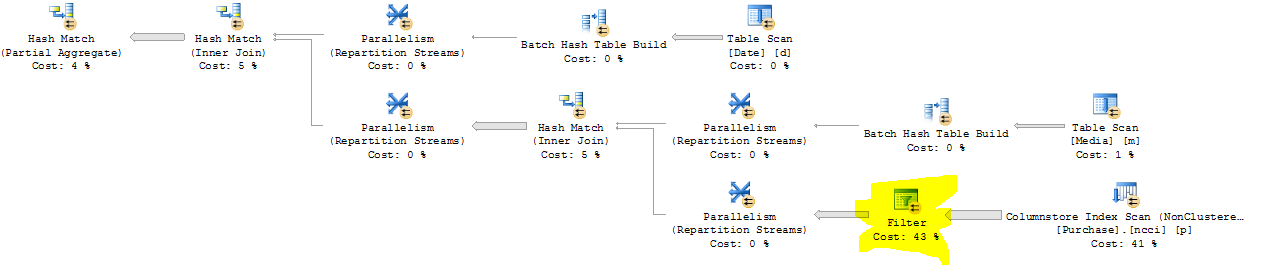
The highlighted operator is a filter to evaluate p.PriceRetailCurrency in ( N'British Pound', N'Euro'). It runs in batch mode but is not used to eliminate data early during the scan. Nevertheless, data is eliminated early during the scan for the join condition with the Media table. Overall, this is a good plan and is not a cause for concern. The plan only takes a quarter of a second to run.
But if the data volume is very large, you may notice that performance is not ideal. The cost of moving data out of the storage engine, even in batch mode, may be significant. In addition, segment elimination will not be performed for filters on strings. Segment elimination is discussed in a separate topic. Just as described above in the discussion of performance issues when joining on strings, you can work around string filter performance issues by normalizing the strings into dimension tables and replacing them with integer surrogate keys, or you can encode the information contained in the string directly into an integer.
Single-Table Queries and String Filters
Sometimes you need to filter on string columns of a large table that has a columnstore index, because it may not always be possible or convenient to factor the strings out into a separate dimension table. In this case, a helpful trick can be to group on the string column first, then filter after the grouping. GROUP BY on string columns is normally extremely fast. Filter operations on strings involving string functions such as LIKE and CHARINDEX can be somewhat slow, even when they run in batch mode. Provided that the string column is low cardinality (i.e. has a relatively low number of discrete values), you may benefit from grouping first and filtering second. For example, consider the following query:
select PriceWholesaleCurrency, count(*)
from dbo.Purchase
where PriceWholesaleCurrency like 'E%'
group by PriceWholesaleCurrency
This query take 3 seconds to run. The following equivalent query takes only 0.08 seconds.
select T.*
from (select PriceWholesaleCurrency, count(*) c
from dbo.Purchase
group by PriceWholesaleCurrency) as T
where T.PriceWholesaleCurrency like 'E%'
The reason the second query is so much faster is that GROUP BY on strings is a lot faster than LIKE, and after the GROUP BY, only a few rows are left to which to apply the LIKE filter. The first of the two queries above has to perform the LIKE computation on every row. This rewrite follows the principal established in other examples -- reduce the number of rows as much as possible before resorting to expensive operations (such as row mode processing, or in this case, evaluation of an expensive string expression).
Simple string filters that use equality checks are usually quite fast, so you don't need to worry about query rewrites like this. For example, this query runs in 0.07 seconds:
select PriceWholesaleCurrency, count(*)
from dbo.Purchase
where PriceWholesaleCurrency = 'USD' or PriceRetailCurrency = 'EUR'
group by PriceWholesaleCurrency