Cosmos Graph database –Big Data processing with Azure Data Factory, Functions and Azure Event Grid
Introduction
Azure Cosmos database is multi-model, globally distributed database from Microsoft. With Apache Tinkerpop and Gremlin support, CosmosDB provides robust infrastructure for building graph structures within enterprises and helps to get real value and insights from existing data.
With wide variety of use cases, graph databases solve various day-to-day problems like organisation social connects, fraud detection, document management etc. This exercise is the first part of a series to create social connects within an organisation using CosmosDB Gremlin API.

Azure Cosmos database is multi-model, globally distributed database from Microsoft. With Apache Tinkerpop and Gremlin support, CosmosDB provides robust infrastructure for building graph structures within enterprises and helps to get real value and insights from existing data.
With wide variety of use cases, graph databases solve various day-to-day problems like organisation social connects, fraud detection, document management etc. This exercise is the first part of a series to create social connects within an organisation using CosmosDB Gremlin API.

Create Cosmos Graph Database Instance within Azure Subscription
The first step of this exercise is to create Cosmos partitioned graph database instance in Azure subscription. The step by step guide is available on Microsoft documentation at /en-us/azure/cosmos-db/create-graph-gremlin-console
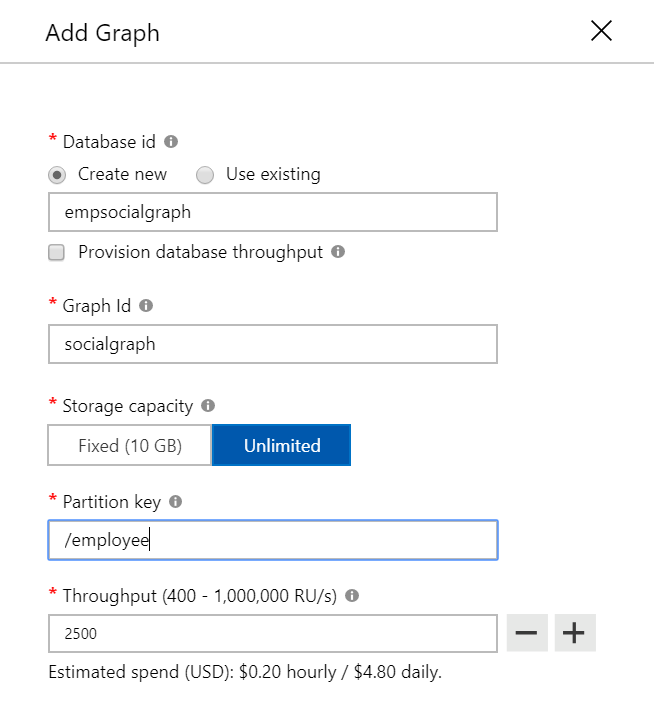
As we are working across multiple environment and subscription and one of the requirement is to automate DevOps process for Cosmos Db graph instance. We have used Visual Studio project with resource manager template and configured the CI/CD pipeline within DevOps portal. For reference we have outlined the sample ARM template which can be reused within the DevOps process.

Sample Azure Resource Manager Template for Cosmos Graph Database
resources": [
{
"type": "Microsoft.DocumentDB/databaseAccounts",
"kind": "GlobalDocumentDB",
"name": "[parameters('cosmosgraphname')]",
"apiVersion": "2015-04-08",
"location": "[parameters('location')]",
"properties": {
"ipRangeFilter": "",
"enableAutomaticFailover": false,
"enableMultipleWriteLocations": false,
"isVirtualNetworkFilterEnabled": false,
"virtualNetworkRules": [],
"databaseAccountOfferType": "Standard",
"consistencyPolicy": {
"defaultConsistencyLevel": "Session",
"maxIntervalInSeconds": 5,
"maxStalenessPrefix": 100
},
"locations": [
{
"locationName": "[parameters('location')]",
"failoverPriority": 0
}
],
"capabilities": [
{
"name": "EnableGremlin"
}
]
}
}
]
The next step is to create graph database collection with specified partition key (ex-employee). Once creation of graph collection the process is completed we have executed sample gremlin query against the graph database through Data Explorer to test the actual JSON format of the vertices and edges
The list of gremlin query to create vertices and edges within the partitioned graph is listed below.

Create Vertices
g.addV('user').property('id', 'u001').property('firstName', 'John').property('lastname', 'S').property('age', 44).property(employee,'0001')
g.addV('user').property('id', 'u002').property('firstName', 'Tim').property('lastname', 'Kho').property('age', 22).property(employee,'0002')
g.addV('user').property('id', 'u003').property('firstName', 'Abhishek').property('lastname', 'Kumar').property('age', 32).property(employee,'0003')
Create Edge
g.V('u001').addE('knows').to(g.V('u002'))
g.V('u003').addE('works').to(g.V('u001'))
Get Microsoft Dynamic CRM Entity Data with Data Factory
For bulk extract from Microsoft Dynamics CRM entity we have connected Dynamics CRM instance and blob storage through dynamics 365 connector and blob connector available within data factory. The basic architecture flow is shown in below.
Note: Connecting to dynamics CRM instance use the domain account which is having at least read permission on the specified entity.

If you do not have existing Data Factory V2 instance then create V2 version of data factory within Azure subscription. One of the important consideration here is to keep cosmos, blob storage and data factory within same subscription and tenant.

Once you are done with data factory instance creation and data factory up and running, click on author and monitor blade which will open data factory author and monitor portal. Create a Copy pipeline process and specify source as Microsoft Dynamics CRM and sink as blob storage (both connectors are available within the Data Factory) .

While populating dynamics CRM connection, you can either select key vault to get the connection properties or domain credentials for your organisation. The preferred option here is to use key vault so that you secure environment access through secrets stored into key vault.
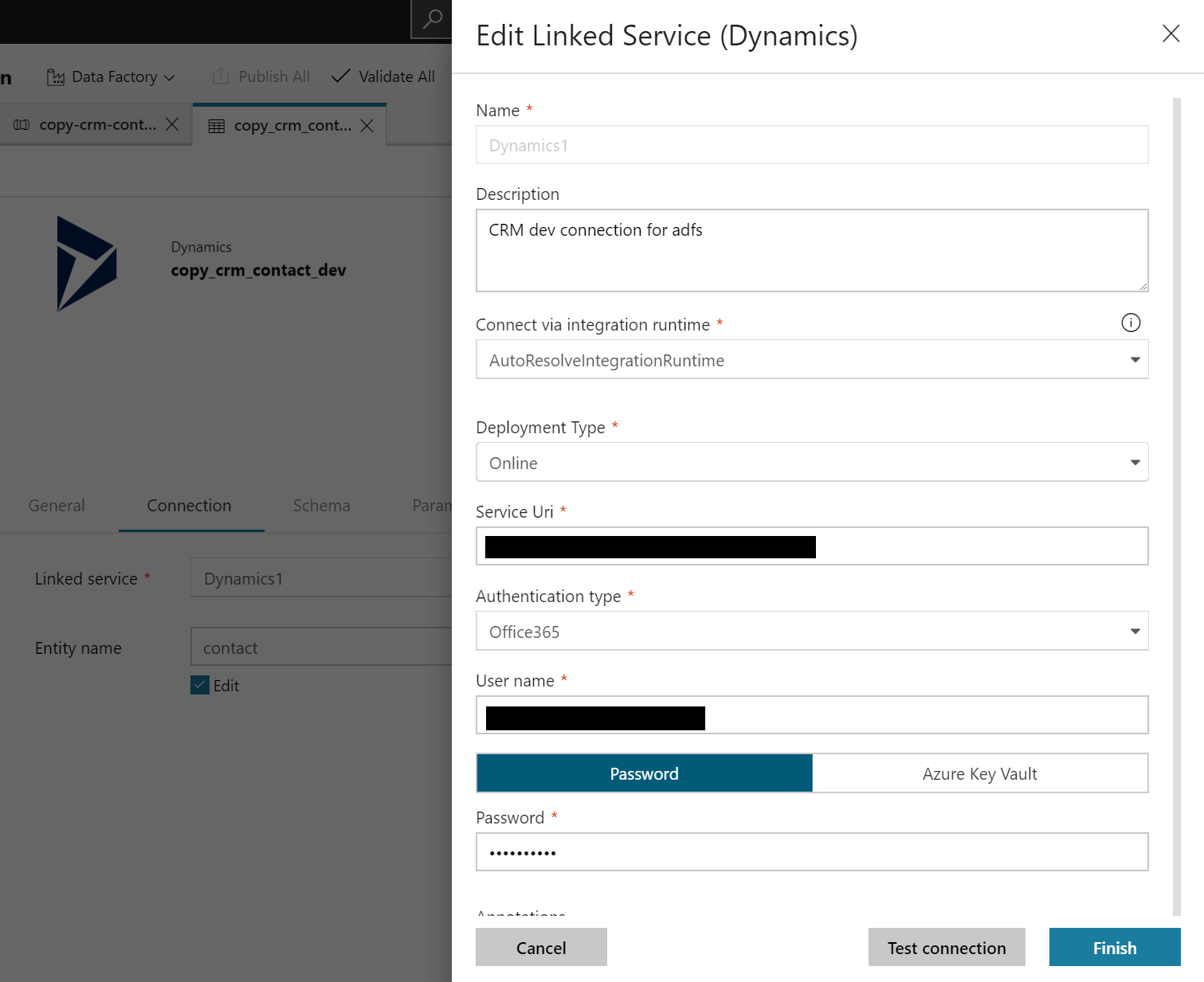
Before you click on the Finish blade test your connection to verify you have right set of access on the Dynamics CRM instance. Once connection is successfully tested
click on Finish blade and publish the connection properties within data factory.

Now coming back to bulk extract execution, in most of the cases you will be required to filter the columns instead of taking all columns records from the required data source. In data factory you can do this by navigating to the schema section and selecting right set of columns which is required for graph vertices (as properties to graph node).
There are real benefits of doing this, it will control the request payload and ultimately the RU unit required for read and write operation. Another benefit is, it will simplify your transformation from raw JSON format to internal graph structure .You can also perform a preview action on the dataset once you have filtered the columns selection within the data factory pipeline
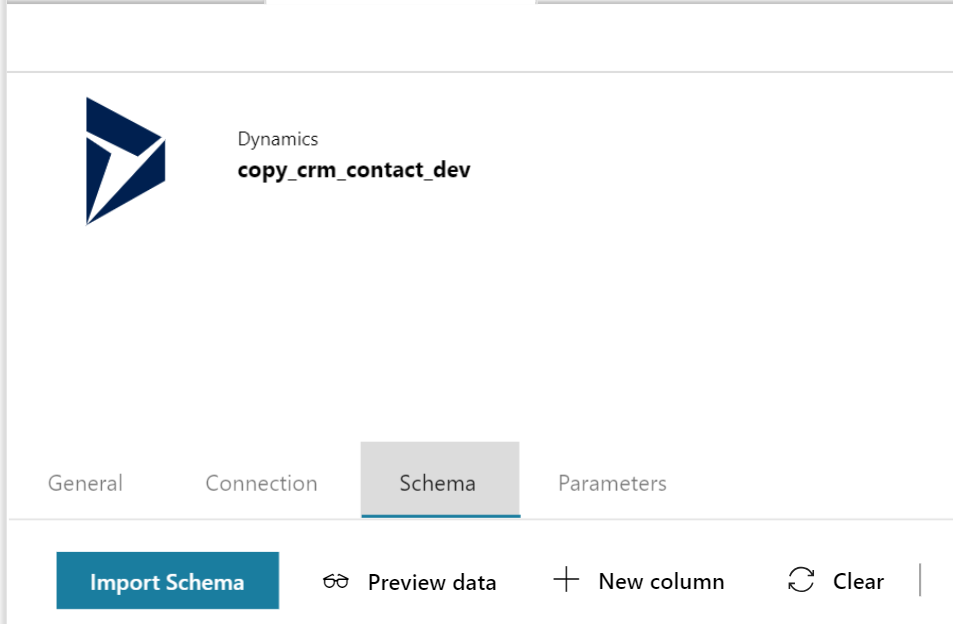
Next is to define the sink connection properties within the copy activity. The sink stage will copy CRM entity record within blob storage for transformation action. To do this in copy activity within sink section select existing blob storage or create new one if you do not have any within your resource group.

Do note here that you need to change the output file format from default, change the file format ad JSON and file pattern as Array of objects instead of set of objects. This will simply the output into array of JSON string which will be easy for serialization and deserialization.
The first stage to copy the file from CRM to blob storage is completed now, next section is to create function within function App and listen to blob creation event through event grid (this function will listen be triggered once CRM-Blob copy activity is completed) and perform a bulk data transformation.
Azure Functions –Read blob Event and Transform Entity Record
In this part we have created http listener azure functions which will listen to blob created event from storage account and perform necessary transformation on raw CRM data and update graph compliance JSON structure in sync blob storage container .C# code for sample function definition is shown below.

Sample Code to listen for blob creation event
using System;
using System.Linq;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.EventGrid;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.Azure.WebJobs.Host;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using Microsoft.Azure.EventGrid.Models;
using System.Collections.Generic;
using nzte.graph.methods;
namespace nzte.graph.functions
{
public static class eventgridgetblobevents
{
[FunctionName("eventgridgetblobevents")]
public static async Task<HttpResponseMessage> Run([HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)]HttpRequestMessage req, TraceWriter log)
{
string requestContent = await req.Content.ReadAsStringAsync();
EventGridSubscriber eventGridSubscriber = new EventGridSubscriber();
EventGridEvent[] eventGridEvents = eventGridSubscriber.DeserializeEventGridEvents(requestContent);
foreach (EventGridEvent eventGridEvent in eventGridEvents)
{
if (eventGridEvent.Data is SubscriptionValidationEventData)
{
var eventData = (SubscriptionValidationEventData)eventGridEvent.Data;
var responseData = new SubscriptionValidationResponse()
{
ValidationResponse = eventData.ValidationCode
};
return req.CreateResponse(HttpStatusCode.OK, responseData);
}
else
{
new System.Threading.Tasks.Task(async () =>
{
if ((eventGridEvent.EventType is "Microsoft.Storage.BlobCreated") && (eventGridEvent.Subject.ToString().Contains("crmcontact")))
{
Syncblob bloboperation = new Syncblob();
string bloboperationresponse = await bloboperation.GetBlobContactAsync();
}
}).Start();
return req.CreateResponse(HttpStatusCode.OK);
}
}
return req.CreateResponse(HttpStatusCode.Accepted);
}
}
}
As you can verify from the function definition the IF condition will check the registration of a new subscription event from event grid, and once subscription validation passes, each new blob creation event will call the GetBlobContactAsync method. The basic logic here is to read the CRM raw JSON array from blob storage and transform it into Tinkerpop and graph compliance JSON string.
using System;
using System.Collections.Generic;
using System.Configuration;
using System.Linq;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure;
using Microsoft.Azure.KeyVault;
using Microsoft.Azure.Services.AppAuthentication;
using Microsoft.WindowsAzure.Storage;
using Microsoft.WindowsAzure.Storage.Blob;
using Newtonsoft.Json;
using nzte.graph.datacontract;
namespace nzte.graph.methods
{
public class Syncblob
{
private static HttpClient client = new HttpClient();
public async Task <string> GetBlobContactAsync ()
{
var azureServiceTokenProvider = new AzureServiceTokenProvider();
var kvClient = new KeyVaultClient(new KeyVaultClient.AuthenticationCallback(azureServiceTokenProvider.KeyVaultTokenCallback), client);
string blobconnectionstring = (await kvClient.GetSecretAsync(Environment.GetEnvironmentVariable("blobSecretId"))).Value;
CloudStorageAccount storageAccount = CloudStorageAccount.Parse(blobconnectionstring.ToString());
CloudBlobClient blobClient = storageAccount.CreateCloudBlobClient();
CloudBlobContainer container = blobClient.GetContainerReference("crmcontact");
container.CreateIfNotExists();
CloudBlockBlob blockBlob = container.GetBlockBlobReference("contact.json");
UserTransformation obj = new UserTransformation();
var list = new List<dynamic>();
string contact = await blockBlob.DownloadTextAsync();
byte[] bytes = Encoding.ASCII.GetBytes(contact);
string someString = Encoding.ASCII.GetString(bytes);
string str = someString.Replace("?", "");
var ObjOrderList = new List<RootObject>();
if (str != " ")
{
ObjOrderList = JsonConvert.DeserializeObject<List<RootObject>>(str);
foreach (var item in ObjOrderList)
{
string dd = JsonConvert.SerializeObject(item);
string s = await obj.TransformUserRecord(dd);
object sample = JsonConvert.DeserializeObject(s);
list.Add(sample);
}
}
string obj1= JsonConvert.SerializeObject(list);
CloudBlobContainer syncontainer = blobClient.GetContainerReference("synctransformedrecord");
syncontainer.CreateIfNotExists();
CloudBlockBlob blockBlob1 = syncontainer.GetBlockBlobReference("crmcontact01.json");
blockBlob1.Properties.ContentType = "application/json";
await blockBlob1.UploadTextAsync(obj1);
return "ok";
}
}
}
To register Azure function endpoint as webhook for the storage events (blob create, blob delete) navigate to your storage account and, on the events blade, register functions endpoint as web hook.
To read more about Graph backend structure go through the article posted on GitHub at https://github.com/LuisBosquez/azure-cosmos-db-graph-working-guides/blob/master/graph-backend-json.md
Based on the above article the function has transformed all the CRM record into appropriate Tinkerpop and graph compliance JSON structure and the sample structure is listed below
{{
"label": "Contact",
"id": "sample user",
"Emailaddress1": [{
"_value": "test_zyy8283@163.com",
"id": "60d78938-70cd-451c-8de6-a5be0ac421a6"
}
],
"Lastname": [{
"_value": "user",
"id": "21082bbc-4661-4818-94de-d3e9e5238a0f"
}
],
"Nickname": [{
"_value": "sampleuser",
"id": "7bb5d793-d7a0-4e90-97b8-3ba36cb0440e"
}
],
"Fullname": [{
"_value": "sample user",
"id": "7ee327d2-553b-471c-9586-844ab2b97294"
}
],
"Yomifullname": [{
"_value": "sample user",
"id": "46cbf987-2644-4cef-8f69-602dee255642"
}
],
"Telephone1": [{
"_value": "+86 (21) 878339",
"id": "ca8e0770-6a92-49b3-a07d-e00d613552c3"
}
],
"Mobilephone": [{
"_value": "+86 (0) 702924565",
"id": "829be998-5a71-4336-993b-a2fb9388d6a0"
}
],
"Firstname": [{
"_value": "Sample",
"id": "5bf96ec2-eedb-408f-855d-1bbde6de397b"
}
],
"Salutation": [{
"_value": “MR”
"id": "f97c5733-dfec-4260-845e-757955f8a436"
}
]
}
}
Copy Transformed JSON array into Cosmos Graph DB
This is the final stage in which we have read the graph compliance JSON structure from Sync blob storage and written the vertices into Cosmos Graph.
This process is also event driven and get initiated by event raised from Sync blob creation (transformed data) which then calls copy pipeline activity within Data Factory. In this pipeline were source is Sync Blob storage which holds the transformed data and sink will be Cosmos graph collection. The overall process is described in below diagram.

When you create copy pipeline activity for cosmos Db sync process always keep in consideration of the sync batch size a small size can give you better performance and it will also saves hitting the database throughput limit. If you look into below screenshot, we have set the batch size to 5 when doing the sink operation through blob storage.
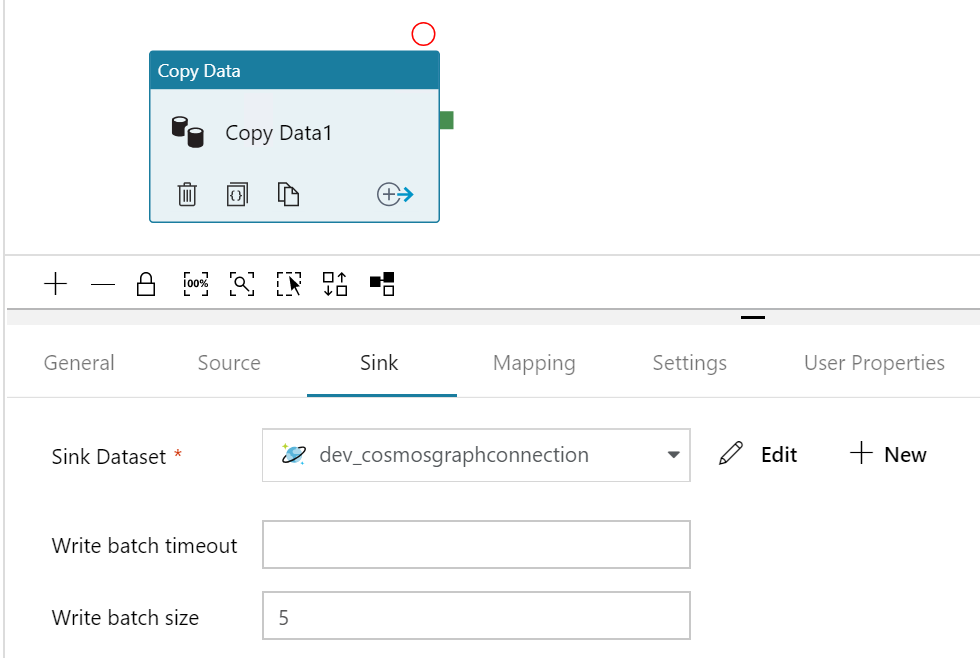
In Data factory, you have option to create trigger based on event .In this case we have registered sync blob event (transformed message) as trigger for Copy pipeline.
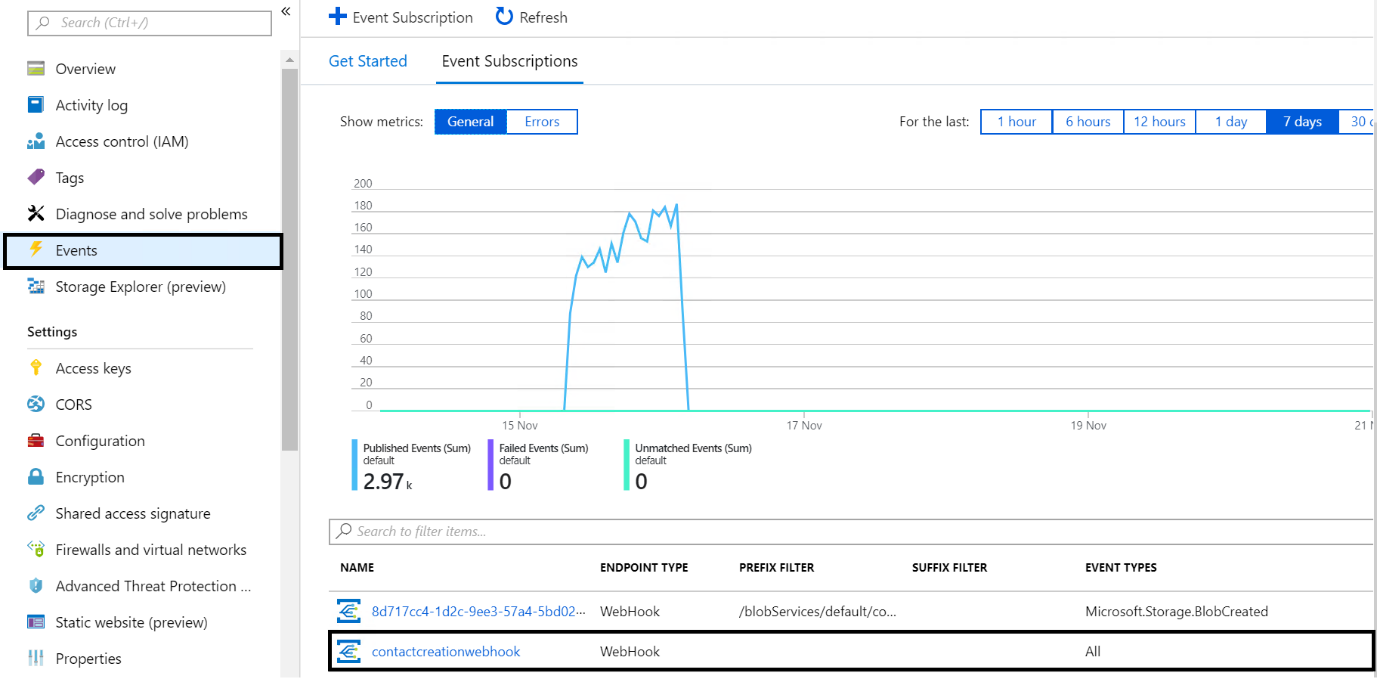
Once the Sync pipelines complete successfully, you can query the vertices within graph explorer or use it within your enterprise application.

At the end of this exercise you can verify the data factory pipeline and the overview of number of nodes (vertices) being written into cosmos graph instance.
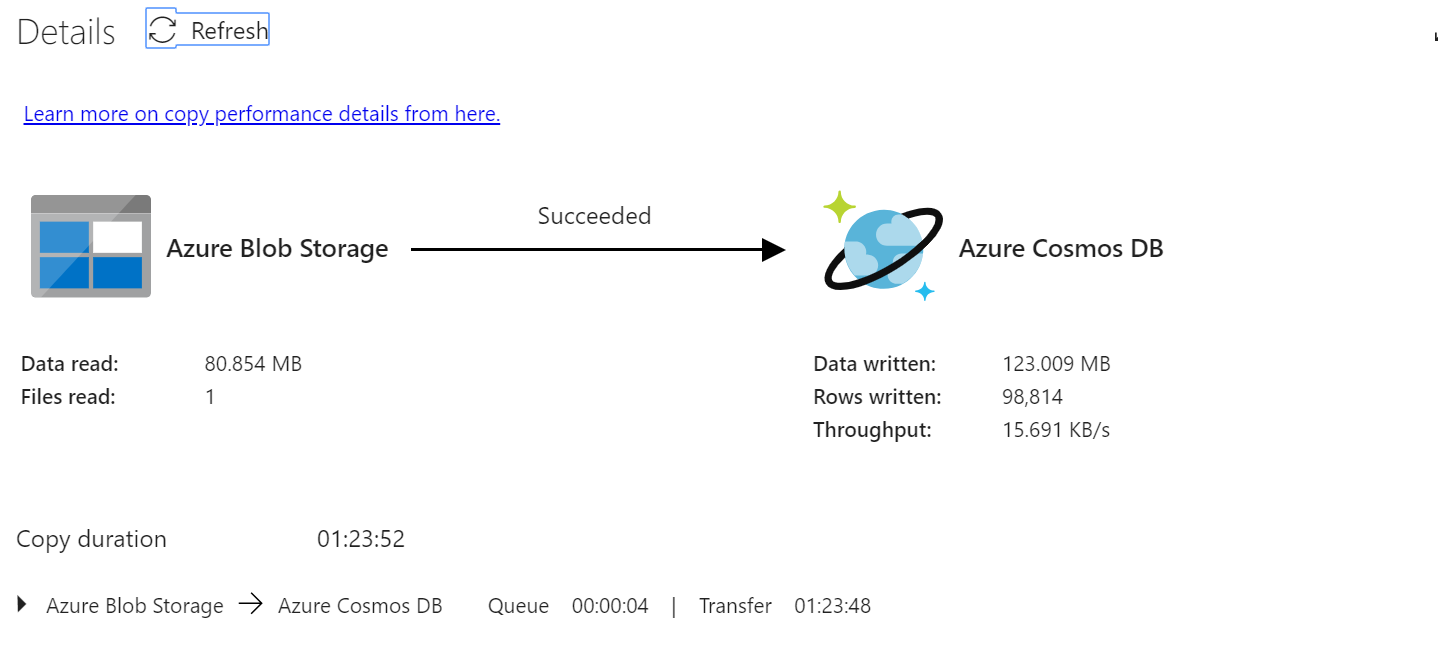
In the next part of this article we will try to show how you can use gremlin and document db library together and work with graph connects. That will help you to get some real useful information with gremlin transversal path.
Conclusion
In this Technet wiki article we have discussed cosmos graph collection and how you can perform bulk sync using event based process . This wiki contains sample code which you can use within your application to listen for Azure events through Event Grid . In next article we will discuss more in details about the gremlin language and how you can work with cosmos graph to build social network within your group .
This article is also been posted on medium Cosmos Graph database –Big Data processing with Azure Data Factory, Functions and Event Grid
See Also
https://github.com/LuisBosquez/azure-cosmos-db-graph-working-guides/blob/master/graph-backend-json.md
/en-us/azure/cosmos-db/graph-introduction
https://azure.microsoft.com/en-au/resources/videos/create-a-graph-with-the-azure-cosmos-db-graph-api/