SQL Server In-Memory OLTP: Understanding and Dealing with Range Indexes on Memory-Optimized Tables
Introduction
In the last article, we saw the internal structure of Hash indexes, how Bucket Count affects performance and SARGAbility. This article explains the second type of index possible with Memory-Optimized tables – the Range Index. It is to be noted that the name “Range Index” was what Microsoft initially gave to this index in the CTP release of SQL Server 2014, however, the terminology was later changed in its production release and it is now called “Non-Clustered Index”. It should also be noted that both Hash and Range indexes are Non-Clustered in nature, but Range indexes are now specifically referred to as non-clustered indexes. This article uses the word “Range index” and “Non-clustered index” interchangeably as they are one and the same.
Hash indexes are best for point-lookup equality searches and when you know the cardinality to estimate the correct number of buckets. Range indexes, on the other hand, provide the best performance when you are searching for a range of values (for example, using <, <=, >, >= operators in predicates). This article explains the internal structure of Range indexes, how data rows are linked with the index leaf pages and performance impact when using the indexes inappropriately.
The internal structure of range indexes
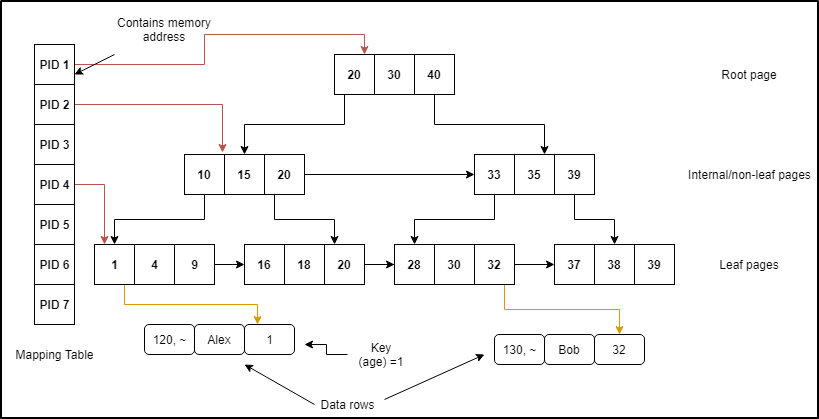
Range indexes have a similar structure as their B-Tree index counterparts in disk-based tables, however, they are not same. Range indexes are implemented using a new data structure called “BW -tree” which is a lock and latch free variation of B-tree and doesn’t restrict the index pages to 8 kb fixed size. Range Index pages can be of various sizes and are not fixed. Just like B-tree indexes, a range index page consists of index key values where each value has a pointer to the index page at the next level. The index tree has levels, at the very top, there is a root page which connects to the next level pages called “internal” pages and internal pages in-turn connect to the last level pages called “leaf pages” which in-turn connect the data rows. Data rows with same index key values are linked together.
Index pages have a page pointer which is a logical page ID (PID) which determines the position in an array-like structure called mapping table which in-turn connects PIDs to their corresponding physical memory address. Just like Hash indexes, Range indexes are defined and created at the time of table creation but unlike Hash indexes, there is no need to specify the word “Range”, instead, the word “Non-clustered” must be defined indicating that the type of index being created is Range.
Just like the data rows in memory-optimized tables, range index pages are never updated, instead, they are replaced with a new index page followed by an update in the mapping table for the corresponding PID so that the entry reflects the new memory address for the same PID.
Every index row on the internal page consists of an index key value and a PID of the next level page. The key value on the page is the highest value on the next level as opposed to the regular B-tree index pages wherein the index rows store the minimum value on the page at the next level. As mentioned earlier, the leaf level pages do contain the index key values but not PID since these are leaf pages and there is no further page level in the index tree. The leaf pages instead contain the memory address of a data row. The data row could, in turn, be linked to a data row chain if all rows have the same key value referenced on the index page.
The following figure illustrates the structure of a range index on column "age".
How delta pages are linked to leaf pages
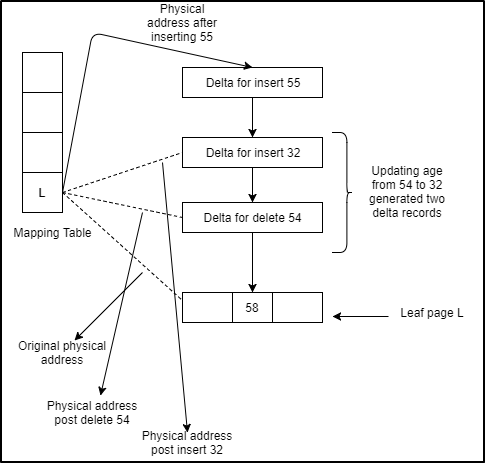
A question might now arise, what happens when index key values are updated in the data rows? What happens to the corresponding leaf pages which connect to the data rows and hold the old index key values? Firstly, remember, by an update, it’s the “delete” followed by an “insert” i.e. when an update to a row happens, the row's "EndTS" is populated marking it "deleted" and a new row version is created with the "BeginTS" same as the "EndTS" of the deleted row. Index pages are never updated. Now, when the index key values change, it creates a delta record page (describing the DML inert/delete operation) linked to the corresponding leaf page.
Now that the leaf page is linked to a new delta page which reflects the update to the index key value, what happens to the mapping table entry for that corresponding PID which still holds the old physical memory address? The answer is, the mapping table is updated with the physical memory address of the delta page that reflects the insert or delete operation against the key value.
In the following example, the leaf page “L” is initially linked with the mapping table with a certain physical memory address but as soon as an index key value “54” is updated to "32" from the data row, two delta record pages indicating a delete followed by insert operation are created and linked through memory pointers with the leaf page. At this point, the mapping table reflects the memory address of the delta page after insert 32. Now, if there is an insert of a new value “55” which didn’t exist before, there is a new delta record indicating the “insert” created and linked with the previous delta page that indicated “insert 32” and the mapping table is updated to reflect the memory address of the latest delta page.
Overhead due to delta pages
As you can imagine, when a query searches through a range index, it traverses and analyzes all delta pages when accessing the index pages and that would affect query performance if there are longer delta chains. For this very reason, SQL Server combines all the delta pages and creates one new index base page. Note that it doesn’t rebuild a leaf page on every delta page creation, instead, the leaf page rebuild process is triggered when there already exist 16 delta pages and a new delta page for that specific leaf page is being requested. At that point, SQL Server consolidates all delta pages and creates a new page with the PID same as the old one followed by updating the mapping table. The old page is marked for Garbage Collection which is a process that clears the deleted pages from memory.
Other processes, besides the delta pages consolidation, that can create new base pages are “Page Splitting” and “Page Merging” both of which are beyond the scope of this article but know that Page Splitting occurs when an index page doesn’t have space to accommodate a new index row whereas Page Merging occurs when the index rows on a page are deleted to a point which leaves the page less than 10 percent occupied.
A key difference between the Bw-tree range indexes and their B-tree counterparts is that the leaf pages of disk-based index consist of separate index rows for same key values whereas, in case of range indexes on memory-optimized tables, the leaf pages have single index row for the row-chain that have the same index key values.
Header and data of range indexes
Range indexes do not have a fixed size as in the case of disk-based B-tree indexes however, an index page cannot exceed 8 KB size. There are two areas in a range index internal and leaf page i.e. Header and Data. The “header” contains page information which includes the following:
Header
PID: The position in the mapping table
Page Type: Root/internal, leaf, delta or special page
Right-Page PID: PID of the page to the right
Key values: Number of index rows on the page
Max key value: Highest value of the key on the page
Page Statistics: Delta record count and count of records
Height: Number of levels to the leaf page from the current page
Data
The area covered by the “data” includes two or three of the following fixed length arrays:
Values: An array of pointers size of each is 8 bytes. Every pointer contains PID of the next level page in case of internal pages. For leaf pages, it contains the memory address of the data rows or the first data row in a row-chain.
Keys: A key is the first value on the page (internal page) or value in the data row chains (leaf page).
Offsets: Array of 2-byte offsets that exists only if the key value has variable lengths.
Note that delta pages have similar “header” area as any other internal or leaf page but a delta page doesn’t have the data area as described for internal or leaf pages above. A delta page only consists of the “insert” or “delete” operation code and the memory address for the corresponding data row (chain) and key value for the delta change.
Impact of data modification on memory-optimized indexes
Let us understand how data modification affects the memory-optimized indexes. In the following example, we will create a new database called “InMemoryDB” and add a new filegroup to hold the memory optimized tables. We will then create three tables:
1) A disk-based table named “DiskBasedTbl” with one clustered and one non-clustered index.
2) A memory-optimized table called “MemoryOptimizedTwoIndex” with one Hash and one range index.
3) A memory-optimized table called “MemoryOptimizedSixIndex” with one Hash and five range indexes.
--creating a new database
CREATE DATABASE [InMemoryDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'InMemoryDB', FILENAME = N'E:\SQL_DATA\InMemoryDB.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB )
LOG ON
( NAME = N'InMemoryDB_log', FILENAME = N'D:\SQL_LOGS\InMemoryDB_log.ldf' , SIZE = 8192KB , FILEGROWTH = 65536KB )
GO
ALTER DATABASE [InMemoryDB] SET COMPATIBILITY_LEVEL = 130
USE [InMemoryDB]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'PRIMARY')
ALTER DATABASE [InMemoryDB] MODIFY FILEGROUP [PRIMARY] DEFAULT
GO
--Add Filegroup to store memory_optimized tables
ALTER DATABASE InMemoryDB ADD FILEGROUP InMemoryDB_FG CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE InMemoryDB
ADD FILE (NAME= 'InMemoryDB_Dir', FILENAME='E:\SQL_DATA\InMemoryDB_Dir')
TO FILEGROUP InMemoryDB_FG
GO
Now that the new database is created, let's create the three tables.
use InMemoryDB
go
--Creating a disk based table with one clustered and one non-clustered index
create table dbo.DiskBasedTbl
(
Id int not null,
SSN int not null,
Name varchar(100),
SerialNo int not null,
Age int not null,
Code int not null
constraint PK_DiskBasedTbl
primary key clustered(Id)
)
create nonclustered index IdX_DiskBasedTbl_SerialNo
on dbo.DiskBasedTbl(SerialNo);
--Creating a non-durable memory-optimized table with one Hash index(PK) and one range index
create table dbo.MemoryOptimizedTwoIndex
(
Id int not null
constraint PK_MemoryOptimizedTwoIndex
primary key nonclustered
hash with (bucket_count=1000000),
SSN int not null,
Name varchar(100),
SerialNo int not null,
Age int not null,
Code int not null
index IdX_SerialNo nonclustered(SerialNo)
)
with (memory_optimized=on, durability=schema_only);
--Creating a non-durable memory-optimized table with one Hash index(PK) and five range indexes
create table dbo.MemoryOptimizedSixIndex
(
Id int not null
constraint PK_MemoryOptimizedSixIndex
primary key nonclustered
hash with (bucket_count=1000000),
SSN int not null,
Name varchar(100),
SerialNo int not null,
Age int not null,
Code int not null
index SSN nonclustered(SSN),
index Name nonclustered(Name),
index SerialNo nonclustered(SerialNo),
index Age nonclustered(Age),
index Code nonclustered(Code)
)
with (memory_optimized=on, durability=schema_only);
Insert Test:
The goal of this insert test is to see if an insert operation is affected if there are more indexes on the memory-optimized tables. We will insert 100,000 records into each of the three tables (1 disk-based and 2 In-memory) created above. We will then see their execution times. Let's start with the disk-based table.
--Inserting 100k records in the disk based table
use InMemoryDB
go
set statistics time on
;with
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)) ,L1 as (select 1 AS c from L0 as A cross join L0 as B) ,L2 as (select 1 AS c from L1 as A cross join L1 as B),L3 as (select 1 AS c from L2 as A cross join L2 as B) ,L4 as(select 1 AS c from L3 as A cross join L3 as B),L5 as (select 1 AS c from L4 as A cross join L4 as B) ,numbers as (select row_number() over (order by (select null)) as k from L5)
insert into dbo.DiskBasedTbl(Id, SSN, Name, SerialNo, Age, Code)
select k, k, k, k, k, k from numbers where k <= 100000;
set statistics time off
go
[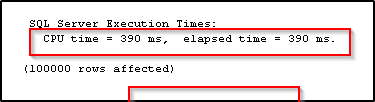
](resources/12641.1.png)As you can see, insert against Disk-based table finished in 390 ms.
Let’s go ahead and insert 100,000 records into the two memory-optimized tables.
Use InMemoryDB
go
set statistics time on
insert into dbo.MemoryOptimizedTwoIndex(Id,SSN,Name,SerialNo
,Age,Code)
select Id,SSN,Name,SerialNo
,Age,Code
from dbo.DiskBasedTbl
option (maxdop 1);
insert into dbo.MemoryOptimizedSixIndex(Id,SSN,Name,SerialNo
,Age,Code)
select Id,SSN,Name,SerialNo
,Age,Code
from dbo.DiskBasedTbl
option (maxdop 1);
set statistics time off
go
[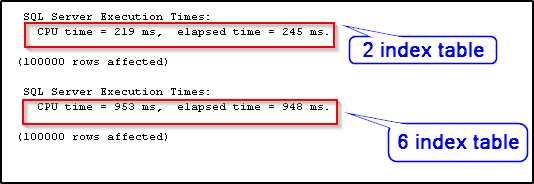
](resources/84827.2.png)It's clearly visible that there is a good difference between the execution times. The memory-optimized table with two indexes took less time (245 ms) than the one with six indexes (948 ms). This is due to the index maintenance overhead incurred by the table with six indexes.
Update Test:
In the update test, we will run two update statements against the disk-based table, in which, one update is on the index column and the second update is on the non-index column.
use InMemoryDB
go
--Updating index column SerialNo is a bit slower
set statistics time on
update dbo.DiskBasedTbl set SerialNo = 117
option (maxdop 1);
--Updating non index column Age is faster
update dbo.DiskBasedTbl set Age = 65
option (maxdop 1);
set statistics time off
go
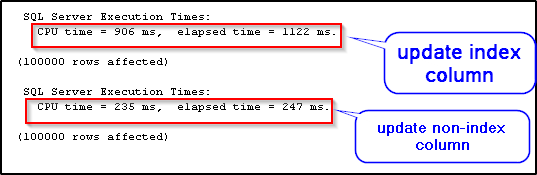
As you can see, update on indexed column took 1122 ms whereas update against non-indexed column took only 247 ms. This is because a non-clustered index in disk-based tables stores data separately and hence, an update on a non-indexed column has no overhead whereas an update on the indexed column incurs the overhead of updating the indexes.
Let us repeat the two update statements but this time against the memory-optimized table.
use InMemoryDB
go
--Updating index column SerialNo in memory optimized table
set statistics time on
update dbo.MemoryOptimizedTwoIndex set SerialNo = 117
option (maxdop 1);
----Updating a non-index column Age
update dbo.MemoryOptimizedTwoIndex set Age = 65
option (maxdop 1);
set statistics time off
go
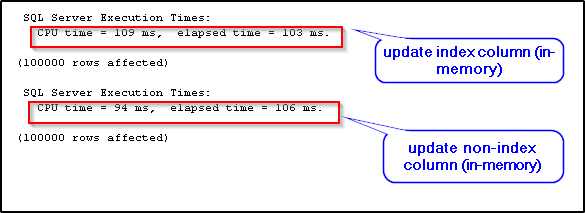
It's evident from the example that the execution times of both update statements against the memory-optimized table are about the same even when the second update ran against the non-index column. This is because, in the case of memory-optimized tables, new data rows are generated irrespective of the columns being updated. An update on a memory-optimized table is a delete followed by an insertion of a new row. Hence, there is not much difference in the execution times.
Conclusion
Range indexes are one of the non-clustered indexes supported by the In-memory OLTP engine which uses a variation of B-tree known as Bw-tree which is lock and latch free. They are helpful when the query doesn't use point-lookup equality searches and instead uses range. For point-lookup equality searches, hash indexes provide better performance provided there is a correct estimation of bucket-count. For better performance, one must avoid having too many indexes as it negatively affects the data modification as proven in this article's examples.
See Also
A Closer Look at Hash Indexes on Memory Optimized tables, Bucket Count and SARGAbility
Memory-Optimized Non-Clustered Index Design Guidelines
Guidelines for Using Indexes on Memory-Optimized Tables