SQL Server In-Memory OLTP: A Closer Look at Hash Indexes on Memory-Optimized Tables, Bucket Count and SARGAbility
Introduction
SQL Server 2014 introduced the much awaited In-Memory OLTP feature which provides breakthrough performance for OLTP workloads. The In-Memory OLTP engine has been designed and integrated to exist with the traditional database engine in such a way that the interfaces such as T-SQL, SSMS etc. can transparently access the in-memory OLTP engine without any need to change anything. In other words, clients can access and work with memory-optimized tables just the way they would with any disk-based tables and would be totally unaware if the tables they are working with are in fact, memory-optimized rather than disk-based.
This article explains one of the new types of indexes introduced in the In-Memory OLTP—Hash Index. We will see the internal structure of Hash indexes and understand how SQL Server works with them, how bucket count (the number of hash buckets in the index array) impacts performance and the proper way to estimate the bucket count. Finally, we will understand the SARGAbility (Search ARGument Ability) of Hash indexes and how it affects performance when the indexes are not used correctly in queries and how to use them properly to make the workload faster.
A brief overview of indexes on memory-optimized tables
Indexes in memory-optimized tables have a very different internal structure than their disk-based counterparts. Every memory-optimized table must, at the very least, have one index. Disk-based tables uses data pages to organize data rows into a single structure whereas in memory-optimized tables, there is no concept of “data page” instead SQL Server uses indexes to combine and organize all rows i.e. the rows belonging to a specific table into one single structure, thus the reason why each memory-optimized must have at least one index. The data rows in memory-optimized tables are linked into index row-chains via memory pointers.
A maximum of eight indexes is allowed on a memory-optimized table. Just like how SQL Server stores the memory-optimized tables in memory, the indexes, too reside entirely in memory. Operations against indexes are never logged and the indexes are never stored to the checkpoint files on disk (in case of durable memory-optimized tables). Indexes are maintained by SQL Server automatically and there is no concept of index fragmentation in case of memory-optimized tables. When SQL Server restarts, it rebuilds the indexes on memory-optimized tables, thus relieving DBAs from the burden of maintaining indexes.
SQL Server 2014 allowed only two types of indexes on memory-optimized tables i.e. Hash and Range indexes, both of which are non-clustered. However, SQL Server 2016 extended it and allows you to create clustered columnstore indexes to support OLAP or analytics workloads. Range and Columnstore indexes are outside the scope of this article and as such, are not discussed.
Is altering a memory-optimized table allowed?
In SQL Server 2014, “ALTER TABLE” or any schema level changes against memory-optimized tables are not allowed. The reason is, memory-optimized tables are natively compiled. Yes, you read it right, not only there is a concept of natively-compiled stored procedures but the tables in memory are natively compiled too. When a memory-optimized table is created, SQL Server uses the table’s metadata to compile native language routines (algorithms) into a DLL which describes the access paths, row format and how to traverse through indexes etc. This is the reason why alter against a memory-optimized table is not allowed otherwise SQL would have to recreate the DLLs all over again.
However, SQL Server 2016 does allow altering a table, index, and schema but the underlying concept is that it creates a new table in memory and performs copying of data from old table to the new one. As you can clearly guess, it requires enough memory to accommodate more than one copy of the table and the process is pretty resource-intensive.
Hash Indexes
A hash index is a brand-new type of index specifically designed for the memory-optimized tables. This index is useful during point-lookups on specific values. Hashing, by definition, is the transformation of data into short, fixed-length values. Hash indexes are of immense help when performing point-lookup operations that normally search within large strings using equality predicates. Hash indexes also improve the performance of point-lookups by reducing the index key size.
A hash index is stored as a hash table (or hash map) and is an array of hash buckets. Each bucket points to the memory location of a data row. A hashing algorithm is known as “hash function” provides a random distribution. One crucial point to note about the hash function is that it always generates the same hash value for the same input. However, different input values can generate the same hash value too, which is known as the hash collision. Hash maps (or hash tables) are the data structures that store hash keys, which map them to the actual data. Each hash key is mapped to a bucket which contains the original data.
A critical point to note here is that although each unique hash key is stored in an individually dedicated bucket in an ideal scenario, if there are less number of buckets, several unique hash keys can be placed in the same bucket and this is what leads to a hash collision. Hence, it is very crucial that a careful determination about the number of buckets is made to minimize hash collision as much as possible.
So, to summarize, a hash index is stored as a hash table which consists of an array of hash pointers where each array element is a hash bucket and stores pointer to the memory location of the data row. Whenever a hash index is created on a column, SQL Server applies a hash function (algorithm) to the index key values and the hash function result determines which bucket will contain the pointer to that row. All rows that have the same hash value are part of the same hash bucket and are linked together through an index pointer chain in the data rows. As mentioned earlier, it’s possible that multiple unique hash keys exist in the same bucket if more buckets are not available.
Example of a Hash Index
To understand how hash indexes are stored, let’s say we have a hash index on a column in a memory-optimized table and new row whose hash value is calculated as 100 is inserted into it. SQL Server stores a pointer to the newly inserted row in bucket 100 in the index array. Now, let’s say there is another row inserted into the same table and co-incidentally the index key value hashes to the same value “100” as the previous row. In this case, the second row inserted becomes the first row in the row-chain in the bucket 100. The newly inserted row will have a pointer to the previous row which hashed to the same hash value. Hence, all key values that hash to the same hash function value exist in the same hash bucket and subsequent rows are linked together in a chain one after the other.
Assuming a hash index is created on the column “FirstName” in a memory-optimized table “Employees” and assuming a hash function generates hash values based on the first letter of the string, a hash index would look something like the following example.
In the real world, a hash function would be much more complex and not as simple as using character-based hashes as assumed in the following example.

As you can see, the left-hand side vertical column containing letters A to Z is the hash table (map) with a hash index on the first name. The two rows with first names Alex and Allison hashed to the same hash value and as such, placed in the same bucket. The row with the first name “Yates” is placed in a different bucket.
If the buckets are not sufficient, multiple different hash keys will have to be accommodated in buckets leading to lookups taking longer as they would have to traverse through longer row chains in each bucket. On the other hand, if the buckets quantity is appropriate, the traversing through row-chains will be a minimum and thus better performance for lookups.
How bucket count impacts performance
Let us now understand how inaccurately estimated bucket-count affects performance. We will create a new database for our experiment with hash indexes. We will then create two memory-optimized tables within the new database, one with low bucket count (1000 buckets) and the other with high bucket count (500000 buckets). It is to be noted that SQL Server rounds the number of buckets to the next power of 2. Also, note that the two tables are schema-only and non-durable in nature i.e. data in them is removed upon SQL restart or when a Database is taken offline. The following are the tables:
- LowBucketCount- 1000 buckets rounded to the next power of 2 gives 1024 buckets
- HighBucketCount- 500000 buckets rounded to the next power of 2 gives 524288 buckets
The following script creates a new database named “InMemoryDB” and adds a new Filegroup “InMemoryDB_FG” to hold the container for checkpoint files for memory-optimized tables. Remember, memory-optimized tables require a separate Filegroup of their own. Finally, the above two tables are created with 1024 and 500000 buckets respectively.
--creating a new database
CREATE DATABASE [InMemoryDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'InMemoryDB', FILENAME = N'E:\SQL_DATA\InMemoryDB.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB )
LOG ON
( NAME = N'InMemoryDB_log', FILENAME = N'D:\SQL_LOGS\InMemoryDB_log.ldf' , SIZE = 8192KB , FILEGROWTH = 65536KB )
GO
ALTER DATABASE [InMemoryDB] SET COMPATIBILITY_LEVEL = 130
USE [InMemoryDB]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'PRIMARY')
ALTER DATABASE [InMemoryDB] MODIFY FILEGROUP [PRIMARY] DEFAULT
GO
--Add Filegroup to store memory_optimized tables
ALTER DATABASE InMemoryDB ADD FILEGROUP InMemoryDB_FG CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE InMemoryDB
ADD FILE (NAME= 'InMemoryDB_Dir', FILENAME='E:\SQL_DATA\InMemoryDB_Dir')
TO FILEGROUP InMemoryDB_FG
GO
use InMemoryDB
go
--1. creating a memory-optimized table with bucket_count=1000
create table dbo.LowBucketCount
(
Id int not null
constraint PK_LowBucketCount primary key nonclustered
hash with (bucket_count=1000),--hash index on PK
SerialNo int not null
)
with (memory_optimized=on, durability=schema_only)--non-durable table
--2. creating a memory-optimized table with bucket_count=500000
create table dbo.HighBucketCount
(
Id int not null
constraint PK_HighBucketCount primary key nonclustered
hash with (bucket_count=500000),
SerialNo int not null
)
with (memory_optimized=on, durability=schema_only)--non-durable table
go
Now that the two tables i.e. HighBucketCount and LowBucketCount are created, let us perform an insert test against them by inserting 500,000 records and compare the time it takes for each of them.
a) Insert Test
use InMemoryDB
go
set statistics time on
;with
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c))
,L1 as (select 1 AS c from L0 as A cross join L0 as B) ,L2 as (select 1 AS c from L1 as A cross join L1 as B),L3 as (select 1 AS c from L2 as A cross join L2 as B) ,L4 as (select 1 AS c from L3 as A cross join L3 as B),L5 as (select 1 AS c from L4 as A cross join L4 as B)
,numbers as (select row_number() over (order by (select null)) as k from L5)
insert into dbo.HighBucketCount(Id, SerialNo)
select k, k
from numbers
where k <= 500000;
;with
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)) ,L1 as (select 1 AS c from L0 as A cross join L0 as B),L2 as (select 1 AS c from L1 as A cross join L1 as B),L3 as (select 1 AS c from L2 as A cross join L2 as B),L4 as (select 1 AS c from L3 as A cross join L3 as B)
,L5 as (select 1 AS c from L4 as A cross join L4 as B) ,numbers as (select row_number() over (order by (select null)) as k from L5)
insert into dbo.LowBucketCount(Id, SerialNo)
select k, k
from numbers
where k <= 500000;
set statistics time off
go
The following screen-print shows the time it took to insert 500k records into both tables. Clearly, the insert against the “HighBucketCount” table took much lesser than the insert against the “LowBucketCount” took. This is because of the fact that the low bucket-count has a greater degree of hash collisions and longer row chains due to non-availability of buckets. The high bucket-count, on the other hand, has very minimal hash collisions as it can accommodate almost every distinct record in an individual bucket.
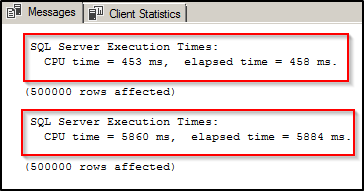
Note: You might argue that we inserted 500k records into a table with 500k + buckets. You would expect each record to reside in its own bucket and that there would be no hash collisions but know that there is still a possibility for a very minimal hash collision even when the bucket count is pretty good.
b) Select Test
Now that we are convinced that low bucket count affects inserts, let’s proceed and test how select against the two tables perform.
The following script retrieves 65k+ rows from both tables i.e. HighBucketCount and LowBucketCount.
Use InMemoryDB
go
declare
@Table table(Id int not null primary key)
;with
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)) ,L1 as (select 1 AS c from L0 as A cross join L0 as B) ,L2 as (select 1 AS c from L1 as A cross join L1 as B) ,L3 as (select 1 AS c from L2 as A cross join L2 as B) ,L4 as (select 1 AS c from L3 as A cross join L3 as B)
,numbers as (select row_number() over (order by (select null)) as k from L4)
insert into @Table(Id)
select k from numbers;
set statistics time on
select t.id, c.Cnt
from @Table t cross apply ( select count(*) as Cnt from dbo.HighBucketCount hwhere h.Id = t.Id ) c;
select t.id, c.Cnt
from @Table tcross apply ( select count(*) as Cnt from dbo.LowBucketCount h
where h.Id = t.Id ) c;
set statistics time off;
go
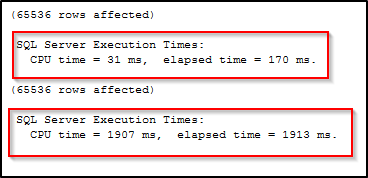
As you can clearly see, “select” against HighBucketCount took much lesser time than LowBucketCount due to the fact that there is no need to traverse through longer row-chains in the case of the **HighBucketCount **table.
What is a good number for bucket count?
You might now be thinking that a high bucket-count helps. It sure does, but not always. Firstly, each bucket costs some size i.e. 8 bytes whether it holds anything or not. If you have lots of unused/empty buckets, then it’s surely a waste of memory. Though it may not seem like a whole lot, for very high bucket counts, it sure is some wastage of memory. The more number of indexes you have on tables with unused buckets, more memory is wasted. Performance might be impacted due to the need to scan all buckets during an index scan.
Also worth mentioning is the fact that when you try to change the bucket-count after a table is created (SQL Server 2016), it creates a new table under the covers. A good number for bucket-count is the number that exceeds the number of unique index keys. You should also take future growth into consideration. It’s always safe to have some extra room and have free buckets to accommodate the future load. If you go with bucket count based on current workload and cardinality, you might run into hash collisions and longer row-chains in near future when you add more data.
Microsoft recommends keeping the bucket-count between one and two times the number of distinct values in the index. Also, if you have a large number of duplicate values in a column, then that column is probably not the one you want to create a hash index on. The reason is, all duplicate values will hash to the same hash value and thus reside in the same bucket and have longer row chains. Tip: Author and Microsoft MVP Dmitri Korotkevitch suggests keeping at least 33 percent of the buckets in the index as empty.
SARGAbility with Hash Indexes
If a query performs an index seek operation then the predicate (the where clause) within that query is said to be SARGable. As mentioned earlier, Hash indexes are of utmost help with point-lookups using equality predicates on high cardinality columns. Normally, a primary key is the best fit for a hash index but not necessarily. Columns with a large number of duplicates are not good candidates for hash indexes as traversing through long row chains adversely affects performance. It should be noted that a hash function generates a hash value based on all the index key columns; in other words, a hash value for an index on a single column would be different than the hash value for a composite index.
As an example, if a hash index is created on column “FirstName”, the hash function returns hash value based on the FirstName column only. That means a query will be able to benefit from this hash index only if its predicate contains “FirstName”. On the other hand, if the query supplies both FirstName and LastName as predicate then the hash value calculated by the hash function would be totally different and as such doesn’t utilize the index. Therefore, the equality predicates for all key columns need to be provided to be able to perform “seek”. This behavior is different in case of disk-based tables wherein index-seek is still possible even when the predicate references a single column when the index is defined as a composite.
Once SQL Server calculates the corresponding hash value, it can locate the bucket that contains the row. If a query uses “between”, < or > as predicates then hash indexes won’t provide any benefit.
To see how SARGAbility works in memory-optimized tables, let’s create two tables with one being the traditional disk-based and the other memory-optimized. We will see how an execution plan for a query changes from “Index Seek” to “Table Scan” in memory-optimized tables when the equality predicate is changed whereas the execution plan remains constant in case of disk-based tables.
The following script creates two tables DiskbasedTbl_Employees and **MemoryOptimizedTbl_Employees **with a nonclustered composite index on FirstName and LastName columns. In case of the latter table, a composite hash index is created on the said two columns. 1000 records are then populated into each of them and a simple select query (with both index key columns in the equality predicates) is run against both tables and their execution plans are evaluated.
set nocount on
go
use InMemoryDB
go
--create Disk-based table
create table dbo.DiskBasedTbl_Employees
(
EmployeeId int not null identity(1,1),
FirstName varchar(128) not null,
LastName varchar(128) not null,
constraint PK_DiskBasedTbl_Employees primary key clustered(EmployeeId)
)
create nonclustered index IDX_DiskBasedTbl_Employees_Composite
on dbo.DiskBasedTbl_Employees(LastName, FirstName)
go
--create memory-optimized table
create table dbo.MemoryOptimizedTbl_Employees
(
EmployeeId int not null identity(1,1)
constraint PK_MemoryOptimizedTbl_Employees primary key nonclustered hash with (bucket_count = 64000),
FirstName varchar(128) not null,
LastName varchar(128) not null,
index IDX_MemoryOptimizedTbl_Employees_Composite nonclustered hash(LastName, FirstName)
with (bucket_count = 1024),
)
with (memory_optimized = on, durability = schema_only)
go
--insert 1000 records in both tables
declare @id int
select @id = 1
while @id <= 1000
begin
insert into DiskBasedTbl_Employees(FirstName,LastName) values('Mark'+ convert(varchar(5), @id), 'josh' + convert(varchar(5), @id))
insert into MemoryOptimizedTbl_Employees(FirstName,LastName) values('Mark'+ convert(varchar(5), @id), 'josh' +convert(varchar(5), @id))
select @id = @id + 1
end
--run select and check execution plan
select EmployeeId, FirstName, LastName
from dbo.DiskBasedTbl_Employees
where FirstName = 'Mark101' and LastName = 'Josh101';
select EmployeeId, FirstName, LastName
from dbo.MemoryOptimizedTbl_Employees
where FirstName = 'Mark101' and LastName = 'Josh101';
go
Let’s take a look at the execution plan.

As you can see, the select query performed an index-seek on both disk-based and memory-optimized tables.
Let’s now change the predicate and remove “LastName” from it leaving only “FirstName”.
Use InMemoryDB
go
select EmployeeId, FirstName, LastName
from dbo.DiskBasedTbl_Employees
where FirstName = 'Mark101';
select EmployeeId, FirstName, LastName
from dbo.MemoryOptimizedTbl_Employees
where FirstName = 'Mark101';
go
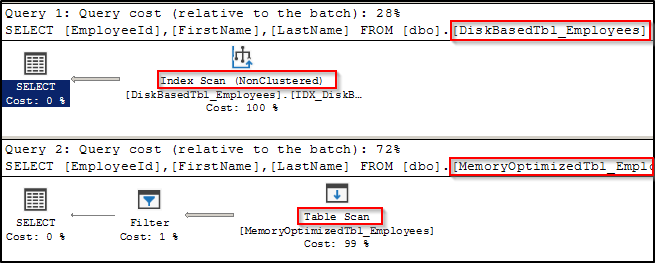
As you can see although the query performed index-scan against the disk-based table, it performed “table scan” on the memory-optimized table. This is due to the fact that SQL calculated the hash value by taking all key columns into consideration and requires all key columns in the equality predicates so a seek can be performed. But since we had only FirstName, it wasn’t able to use the hash index and perform seek.
Conclusion
Hash indexes are very useful when performing point-lookup equality searches and provide no benefit when doing range searches. Bucket-count for hash indexes plays a very important role in index tuning but too many unused buckets are not good either. Therefore the tables need to be carefully evaluated and a proper bucket count should be determined by keeping future growth into consideration. This will prevent long row chains in individual buckets and improves performance. All index key columns are required in the query predicates to be able to use hash indexes, this is because the hash function creates a hash key based on all key columns.