SQL Server Transaction Log Internal Architecture- Facts Every SQL Server Database Professional Should Know
Introduction
Transaction log or T-log, as it is often called, is a vast subject and critical for anyone working with SQL Server databases. The ability to recover a database to a certain point-in-time after a crash or failure heavily depends on how its T-log is managed. This article attempts at explaining the internal structure of T-log files and how they log transactions, their usage during recovery operations and how they are extended as a result of log file auto extension. You will see throughout this article that the names T-logs or Transaction logs or SQL Server log files are used interchangeably as they all mean one and the same.
What lies within a Transaction log file?
If you have worked with SQL Server databases, you must have noticed that a database consists of one or more LDF files (alongside MDFs, which are data files). These physical files are nothing but SQL Server log files. A transaction log file records all changes made to the database. It also stores enough information required to roll back a transaction in the event it is killed by the user running it or should SQL Server itself chooses to roll it back (in case of a deadlock). The information the T-log captures is needed during the recovery of a database every time SQL Server reboots or when a database is restored with recovery. The operations that modify data pages in the database buffer cache write log records in the log file (Spoiler- not directly to the log file, explained shortly) that describe what changes were made.
Each log record includes information about the transaction such as the page numbers of the data pages affected by that operation along with date and time of the beginning and end of the transaction. Log records are also generated when checkpoints occur. Detailed explanation about CHECKPOINT is outside the scope of this article but for the sake of this article just know that one of the events that happen when a checkpoint runs is the flushing of dirty data pages from the buffer cache to disk. A dirty page is nothing but a data page called from disk into memory and is modified as a result of the user operation. A page can be changed multiple times while still in memory before being written to disk. Each log record is uniquely identified by a number known as Log Sequence Number or LSN. LSNs cannot and will not be duplicated and are guaranteed to be unique.
The Log Cache
Does SQL Server write log records directly to the physical LDF files? The answer is No. Here comes the role of the “Log Cache”. Log cache is an area in memory where SQL Server caches the log records before they are written to the physical LDF files. The log cache can contain up to 128 entries on a 64-bit or 32 entries on a 32-bit machine. Each entry corresponds to a buffer of 60 KB size where the log records are cached before being written to the physical file as single 512 bytes to 60 KB blocks. As mentioned just now, each entry contains a buffer of 60 KB so it can accommodate the largest potential block of 60 KB. The number of allocated buffers varies with the workload i.e. if the workload generates large blocks there will be less number of buffers allocated and vice versa. If the log writer takes time to flush the cached log blocks, more buffers will be needed and vice versa.
Virtual Log Files – VLFs
** **
Transaction log files are managed internally by a number of virtual log files or VLFs. SQL Server determines the size of each VLF based on the total size of all T-log files and the “Auto Extend” increment setting for the log file. When a log file is originally created, it always consists of VLFs between 2 and 16. The breakdown is given below:
- If the file size is less than or equal to 1 MB, SQL divides the size of the log file by the minimum VLF size (31 * 8 KB) and determines the number of VLFs.
- If the file size is between 1 MB and 64 MB, SQL Server divides the log file into 4 VLFs.
- If the file size is between 64 MB and 1 GB, it creates 8 VLFs.
- If the file size is greater than 1 GB, 16 VLFs are created.
The above VLFs are determined by initial log creation and the same procedure is followed every time the log is auto extended.
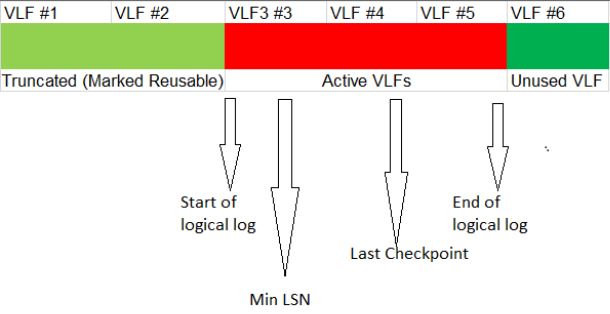
States of a VLF
At any given point in time, a VLF can be in any of the following four states.
a) Active: The part of the T-log that starts at the min LSN (Minimum LSN) representing an active transaction and ends at the last LSN is known as the active portion of the transaction log. Always remember, an active portion of the log can never be truncated (truncate operation is covered later in the article). The VLFs that span the active portion of the log are considered to be active VLFs.
b) Recoverable: The portion of the T-log preceding the oldest active transaction is needed to maintain a sequence of log backups for restoring the database to a point-in-time. The VLFs located in this area are said to be recoverable. Recall in simple recovery model, this recoverable area gets truncated on every checkpoint as log backups are not at all possible there. Always remember, an active portion of the T-log cannot be truncated even in the case of the simple recovery model.
c) Reusable: The recoverable area becomes reusable after a log backup (in case of full or bulk-logged recovery model) or checkpoint (in case of simple recovery model). All the VLFs covered by this area are marked reusable. These are the VLFs preceding the oldest active transaction.
** Unused**: The VLFs that have not yet been used are unused VLFs. Normally these are the VLFs that are located at the physical end of the log file.
Properties of Virtual Log Files
An undocumented command “DBCC LOGINFO” is used to check the properties of VLFs. Each row returned by this command corresponds to one VLF hence the number of rows returned is equal to the number of VLFs present in the log file.
The screenshot provided below is the result of running DBCC LOGINFO against one of the demo databases. As you can clearly see it returned eight rows and hence eight VLFs exist in the log file. Recall SQL Server creates eight VLFs if the log file size is between 64 MB and 1 GB and since the database used for demo had 100 MB log file, it, sure enough, created eight VLFs. Let’s walk through each column returned and see what it means.
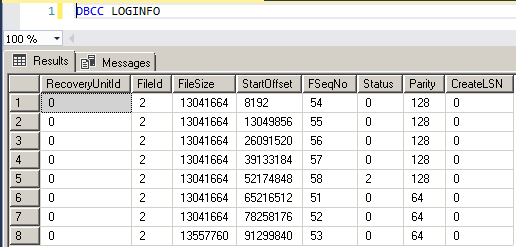
- Fileid: This column indicates which of the physical log files contains the VLF. Since the database I ran it against had only one log file and hence only one number.
- FileSize: Size in bytes of the corresponding VLF.
- StartOffset: position in terms of bytes. Notice that the first VLF starts at 8192 bytes which is nothing but 1 page of 8 KB. This means, the very first page doesn’t have any VLFs and contains header information. The VLFs starts after the first 8 KB page. If you subtract the two successive StartOffset values, the result would be the FileSize of the corresponding VLF.
- FSeqNo: File Sequence Number is the logical order in which the VLFs are used. The sixth row i.e. the sixth VLF indicated by FSeqNo “51” is actually the first one used. The FSeqNo do not start with 0 because these values keep incrementing every time a VLF is reused. Even if a brand new database is created, these values wouldn’t start with 0 because a new database takes the image of Model database and the next FSeqNo after maximum FSeqNo of Model database’s VLF would be the starting VLF for the new database being created.
- Status: The value of 2 in the status column means the VLF is active or recoverable whereas a value of 0 indicates the VLF can be reused or was completely unused. In the screenshot above, except row 5, all have the status of 0 which means they can be reused. The VLF in row 5 could either be part of an active transaction or recoverable.
- Parity: Parity column has two possible values 64 and 128. This value keeps switching when a VLF is reused.
- CreateLSN: This is the T-log LSN when the VLF was added to the log file. Status “0” in this column means the corresponding VLF was added as part of the original database creation. In the screenshot above, all CreateLSN values show 0, indicating that there was no auto-extend ever happened for the log file.
**Notes:
**
- An important point to note here is, although the rows returned are in the physical order of arrangement of StartOffset but that is not always how VLFs are accessed. They are used in the logical order given in the column FSeqNo.
- There is no documentation pertaining to what the column RecoveryUnitID is for.
Pro-tip 1: If you notice that log doesn’t truncate even after taking log backups or running manual checkpoints, run DBCC LOGINFO and see if the “status” column for the VLFs remains as 2. If it does, then yes, there are active VLFs that are holding up the truncation. Also, note that if all the VLFs show a status of 2 then SQL Server would need to add more VLFs to write the subsequent log records.
Pro-tip 2: To know how many VLFs were added as a result of auto-extension of the log file, simply add the rows that have same CreateLSN and the total would be the number of new VLFs added.
Recommended size and number of VLFs
It depends. On one side, if there are a few large size VLFs, it makes managing log space difficult due to the fact that the VLFs cannot be marked reusable if they contain active log records. The entire VLF is marked active and cannot be reused for storing new log records even if only few log records within the large VLF are active. On the flip side, smaller VLFs are not good either. The may cause delays during log backups as there will be a lot of VLFs. Imagine you have log shipping configured and having too many smaller VLFs could potentially increase the log backup and restore times.
Hence, there is always a tradeoff. With that being said, the recommended size for a VLF is less than 1 GB. So as an example, if you are creating a new database and would like to start your log file size with 64 GB initial size, try to increase the log file size in chunks instead of one time creation i.e. create the database with 8 GB as initial size of the log file and then alter its size seven times to add 8 GB more each time. This will make the size of each VLF to 512 MB.
As for the number of VLFs, the recommended number is less than 1000 VLFs. As mentioned earlier, having too many VLFs causes overhead in the log backups and recovery (VLFs would be examined during the recovery process every time SQL starts and in any other recovery scenario).
Pro-tip: If you notice a large number of VLFs in your log file, a workaround to minimize the number of VLFs is to shrink the log file and use an auto growth setting in a way that would create less number of VLFs. Again, if you have an active transaction, you may not have much luck with shrink operation so consider committing/rolling back the active transaction followed by truncating the log and finally shrinking it.
Does using multiple log files help?
The answer is, not really. The log is treated as a single stream regardless of the number of T-log files present. If you have multiple log files but you regularly take log backups (if your database is running under full/bulk-logged recovery model) and efficiently manage the log, SQL may never go to the next physical log file and will continue to use the first one created at the time of database creation. Only when SQL runs out of VLFs (which is when there’s no VLF that can be reused) in all log files is when SQL adds new VLFs in a round-robin method.
Let’s see this in action. The following script creates a new database called “SAMPLE” with three log files whose initial size is given as 10 MB each. Notice that the “SAMPLE_LOG_2.ldf” and “SAMPLE_LOG_3.ldf” do not have any auto increment set. This was done intentionally to see how SQL adds new VLFs when the log grows. The next code performs a SELECT INTO operation to copy data from an AdventureWorks database into the newly created SAMPLE database to force the log files to grow.
CREATE DATABASE [SAMPLE]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'SAMPLE', FILENAME = N'D:\Program Files\Microsoft SQL Server\Datafiles\SAMPLE.mdf' , SIZE = 102400KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'SAMPLE_log1', FILENAME = N'D:\Program Files\Microsoft SQL Server\Logfiles\SAMPLE_LOG_1.ldf' , SIZE = 10240KB , MAXSIZE = 2097152KB , FILEGROWTH = 10240KB ),
( NAME = N'SAMPLE_log2', FILENAME = N'D:\Program Files\Microsoft SQL Server\Logfiles\SAMPLE_LOG_2.ldf' , SIZE = 10240KB , FILEGROWTH = 0),
( NAME = N'SAMPLE_log3', FILENAME = N'D:\Program Files\Microsoft SQL Server\Logfiles\SAMPLE_LOG_3.ldf' , SIZE = 10240KB , FILEGROWTH = 0)
GO
USE [SAMPLE]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'PRIMARY') ALTER DATABASE [SAMPLE] MODIFY FILEGROUP [PRIMARY] DEFAULT
GO
Let’s see what DBCC LOGINFO returns for this blank database containing no database objects.
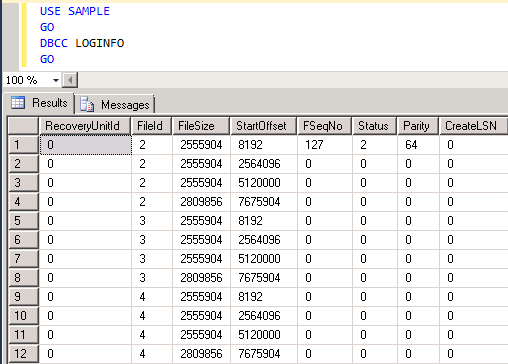
As you can see, it created 4 VLFs for each log file hence a total of 12 VLFs combined. Also, CreateLSN shows “0” for all VLFs indicating that these VLFs were created as part of the initial database creation.
Now, let’s run the SELECT INTO statement to populate a table in SAMPLE database and generate some log records.
USE SAMPLE
GO
SELECT * INTO GenerateLog FROM AdventureWorks2012.Sales.SalesOrderDetail;
GO
Again, run DBCC LOGINFO and see what changed after the SELECT INTO operation.
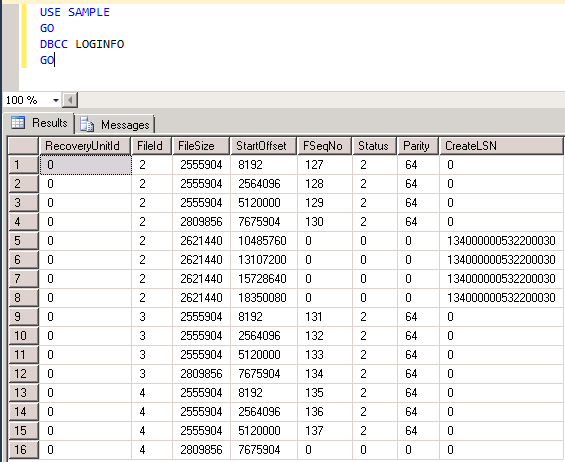
As you can see, the VLFs increased from 12 to 16 and if you notice the CreateLSN field, there are four rows with same LSN indicating that four new VLFs were added to one of the physical files with FileId “2” as the log grew. Also, the Status of the newly added VLFs shows as “0” meaning they are unused. On the other hand, the “Status” for all other VLFs shows as 2 which means they are active.
Let us try to save the DBCC LOGINFO results to a table and sort it by FseqNo so the results look clean.
--create a table in master to store the DBCC LOGINFO results
CREATE TABLE SP_THREELOGS
(RecoveryUnitID int,
Fileid tinyint,
Filesize bigint,
StartOffset bigint,
FseqNo int,
Status tinyint,
Parity tinyint,
CreateLSN Numeric(25,0)
)
GO
--Load the DBCC INFO output into the SP_THREELOGS table
INSERT INTO SP_THREELOGS
EXEC('DBCC LOGINFO')
GO
--return the results for review
SELECT FILEID, STARTOFFSET, FSEQNO,
STATUS, CREATELSN FROM SP_THREELOGS
ORDER BY FSEQNO
GO
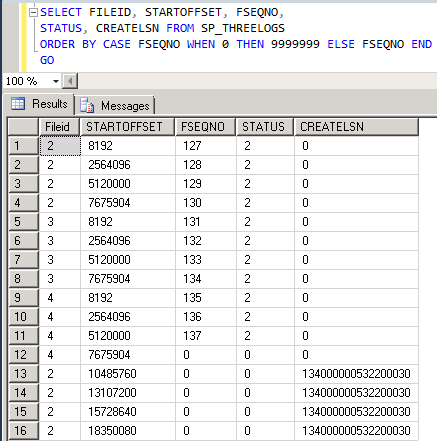
As can be seen above, because the other two log files didn’t have auto-extend set to ON, SQL Server extended the size of the primary log file to 20 MB by adding 10 MB to the original 10 MB size. Hence, it added four new VLFs as shown by the last four rows with non-zero CreateLSN.
Truncate Vs Shrink operation on a T-log
There seems to be some sort of confusion among the DBAs regarding the truncate operation in a transaction log file. Truncation in a log file is nothing but marking the VLFs preceding the oldest active transactions as reusable. This is not a physical operation nor does it shrink the log file. Hence, you would not see any space reclaimed after truncating a T-log. Truncation of a log file is a logical operation and as just mentioned, simply marks the parts of the log as not needed or reusable so it can be used to store the new log records.
Shrink, on the other hand, is what you would need to run to reduce the log file size. This actually reclaims space from the log file by removing any VLFs at the end of the log file that are not active. You may choose to either truncate or shrink or both. In fact, there is an option to automatically shrink the database by enabling the AUTO_SHRINK option for the database. A background task runs every 30 minutes and shrinks the database to leave 25% free space.
Caution: Never set the AUTO_SHRINK option to true as it causes massive fragmentation and consumes a lot of resources every time it is invoked. Enabling this option is not at all recommended. Not only this option, one should never shrink a database unless it becomes absolutely necessary.
Write-Ahead Logging-WAL
When a transaction is in progress, the data pages being affected by the transaction are called into memory from disk (unless they are already in memory). The area in memory where the data pages undergo changes is the database buffer cache. The buffer cache is one of the largest consumers of memory. Data pages are read into buffer cache from disk and get “dirtied” followed by being flushed out to disk by a process known as CHECKPOINT that runs at regular intervals, this flushing of pages is also known as hardening of the data pages to disk.
By now you know that as the data pages are being worked in memory, the corresponding changes are also written to the log cache and later flushed out to the physical log files. A question now arises, which of the two operations i.e. flushing of dirty data pages from the buffer cache to disk and flushing of log blocks from log cache to the physical log files, happens first for the corresponding transaction? The answer is, SQL Server always flushes the log blocks to the physical log files before the corresponding data pages are written to disk. This phenomenon is known as Write-Ahead Logging or WAL. The reason is pretty simple, imagine the other way around i.e. what if the data pages were written to the disk before the log records made their way to the physical log files. Further, imagine there was a power failure immediately after the data pages were flushed to disk as a result of checkpoint but before the corresponding log records made their way to log files. Remember the transaction was in progress when the power failure occurred.
Now, as soon as SQL Server comes back online, the first thing it does is try to recover the database to the point just before the failure. Now, because the log records were still in memory and were lost due to crash, SQL Server cannot “undo” the incomplete transaction that was in progress. Although its data pages exist on disk but since they were uncommitted, they need to be rolled back to bring the database back to a consistent state but because the corresponding log records do not exist in the log file, the incomplete transaction cannot be undone and would lead to inconsistencies between the data and log files. Hence to avoid this kind of a situation, SQL Server makes absolutely sure that the log records are written to the log files before the corresponding data pages can be flushed out.
At the time of checkpoint, SQL Server only flushes the data pages that carry LSN which is less than or equal to the LSN of the latest log record. This way, it ensures that it doesn’t flush out any data page whose corresponding log record is still in log cache. Hence, adhering to the Write-Ahead Logging phenomenon.
Conclusion
Log files are very critical and a SQL Server database has one or more log files in addition to one or more data files. To efficiently manage a log file, make sure that log backups are taken regularly if the database runs under full or bulk-logged recovery model. Always ensure that the number of VLFs is within the recommended limit of 1000 and that the size of each VLF is less than 1 GB. Level of the log stored in the log file is determined by the recovery model a database runs under. Transaction log files guarantee the consistency of the data.