T-SQL: Remove Duplicate Rows From A Table Using Query Without Common Table Expression
Introduction
Another TechNet article by sqlsaga discusses removing duplicates from a table using Common Table Expression.
That article can be accessed here: How to Remove Duplicates from a Table in SQL Server.
This article explores our possibilities of refraining ourselves from using 'with common table expression' to achieve the same result.
This article shows how to remove duplicate rows from a table in SQL Server without a common table expression.
Prerequisite
If we take the same example of the table used in the article, How to Remove Duplicates from a Table in SQL Server as follows:
CREATE ``TABLE People ``(
Name varchar(50) NOT NULL,
City varchar(30) NOT NULL,
[State] char(2) NOT NULL
);
INSERT INTO People(Name, City, [State])
VALUES
('John', 'Dallas','TX'),
('Mark', 'Seattle','WA'),
('Nick', 'Phoenix','AZ'),
('Laila', 'San Jose','CA'),
('Samantha', 'Tulsa','OK'),
('Bella', 'San Antonio','TX'),
('John', 'Dallas','TX'),
('John', 'Dallas','TX'),
('Mark', 'Seattle','WA'),
('Nick', 'Tempe','FL'),
('John', 'Dallas','TX');
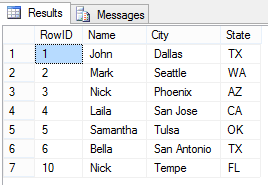
SELECT * FROM People;
The aforementioned script will create the table, People, with 11 records, where 5 records are duplicates (if we consider similar Name field) or 4 records are duplicates (if we consider all of Name, City, State fields). Therefore the aforementioned Select query returns the following rows:
Query To Delete Duplicates Without Common Table Expression
You can execute the following query to delete the aforementioned 5 duplicate records from the table People:
-- Delete any duplicates which have the same Name field in the table
DELETE DUP
FROM
(
SELECT ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Name ) AS Val
FROM People
) DUP
WHERE DUP.Val > 1;
-- Or else you can also use the following query
-- to delete duplicates having same Name, City and State fields in the People table
DELETE DUP
FROM
(
SELECT ROW_NUMBER() OVER (PARTITION BY Name, City, State ORDER BY Name, City, State ) AS Val
FROM Peole
) DUP
WHERE DUP.Val > 1;
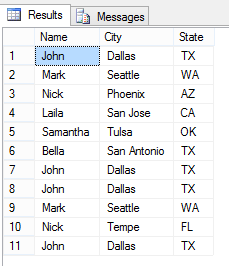
The aforementioned query (or queries) uses an inner query to construct a view over the People table based on ROW_NUMBER within a partitioning of a result set. Now, if you run the select statement on People table once again you can find that the duplicates have been removed effectively as follows:
Dealing With Real World Tables To Remove Duplicates
MS SQL Tables in the real world will have primary key column most of the times, unlike the example that was presented above. In case your tables do not have the primary key column(s) then you should ask yourself whether the table structure is formed correctly and revisit the design of your table structures to amend it. Now, if we take the same People table into consideration with a small amendment, having an identity primary key column, we can remove duplicates in another way.
Prerequisite
Create Table With Identity Column
Let's create the People table with an identity column, which will also serve as the primary key of the table as follows:
CREATE TABLE People(
RowID int not null identity(1,1) primary key,
Name varchar(50) NOT NULL,
City varchar(30) NOT NULL,
[State] char(2) NOT NULL
);
-- Use the same code as in the previous script to populate the table
SELECT * FROM People
Removing Duplicates From A Table With Identity Primary Key Column
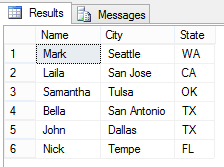
Execute the following code and all your duplicates are gone forever:
DELETE FROM People
WHERE RowId NOT IN (SELECT MIN(RowId) FROM People GROUP BY Name, City, [State]);
And now if you use the select statement on the table, People you will find that the duplicates have been removed effectively by a one-liner query shown above.