SQL Server Columnstore Performance Tuning
 Important Notice Important Notice |
|---|
| The "SQL Server Columnstore Index FAQ" page on TechNet Wiki has been decommissioned and replaced by this article on MSDN: Columnstore Indexes Described |
Introduction
SQL Server columnstore indexes are new in the SQL Server 2012 release. They are designed to improve query performance for data warehouses and data marts. This page describes query performance tuning for columnstores.
Fundamentals of Columnstore Index-Based Performance
Columnstore indexes can speed up some queries by a factor of 10X to 100X on the same hardware depending on the query and data. These key things make columnstore-based query processing so fast:
- The columnstore index itself stores data in highly compressed format, with each column kept in a separate group of pages. This reduces I/O a lot for most data warehouse queries because many data warehouse fact tables contain 30 or more columns, while a typical query might touch only 5 or 6 columns. Only the columns touched by the query must be read from disk. Only the more frequently accessed columns have to take up space in main memory. The clustered B-tree or heap containing the primary copy of the data is normally used only to build the columnstore, and will typically not be accessed for the large majority of query processing. It'll be paged out of memory and won't take main memory resources during normal periods of query processing.
- There is a highly efficient, vector-based query execution method called "batch processing" that works with the columnstore index. A "batch" is an object that contains about 1000 rows. Each column within the batch is represented internally as a vector. Batch processing can reduce CPU consumption 7X to 40X compared to the older, row-based query execution methods. Efficient vector-based algorithms allow this by dramatically reducing the CPU overhead of basic filter, expression evaluation, projection, and join operations.
- Segment elimination can skip large chunks of data to speed up scans. Each partition in a columnstore indexes is broken into one million row chunks called segments. Each segment has metadata that stores the minimum and maximum value of each column for the segment. The storage engine checks filter conditions against the metadata. If it can detect that no rows will qualify then it skips the entire segment without even reading it from disk.
- The storage engine pushes filters down into the scans of data. This eliminates data early during query execution, improving query response time.
The columnstore index and batch query execution mode are deeply integrated into SQL Server. A particular query can be processed entirely in batch mode, entirely in the standard row mode, or with a combination of batch and row-based processing. The key to getting the best performance is to make sure your queries process the large majority of data in batch mode. Even if the bulk of your query can't be executed in batch mode, you can still get significant performance benefits from columnstore indexes through reduced I/O, and through pushing down of predicates to the storage engine.
To tell if the main part of your query is running in batch mode, look at the graphical showplan, hover the mouse pointer over the most expensive scan operator (usually a scan of a large fact table) and check the tooltip. It will say whether the estimated and actual execution mode was Row or Batch. See here for an example.
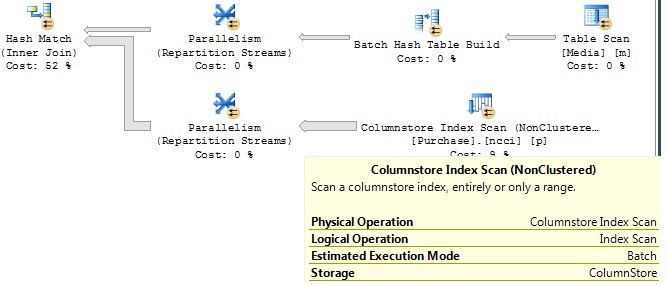{kind=link}
DOs and DON'Ts for using Columnstores Effectively
Obeying the following do's and don'ts will help you get the most out of columnstores for your decision support workload.
DOs
- Put columnstore indexes on large tables only. Typically, you will put them on your fact tables in your data warehouse, but not the dimension tables. If you have a large dimension table, containing more than a few million rows, then you may want to put a columnstore index on it as well.
- Include every column of the table in the columnstore index. If you don't, then a query that references a column not included in the index will not benefit from the columnstores index much or at all.
- Structure your queries as star joins with grouping and aggregation as much as possible. Avoid joining pairs of large tables. Join a single large fact table to one or more smaller dimensions using standard inner joins. Use a dimensional modeling approach for your data as much as possible to allow you to structure your queries this way.
- Use best practices for statistics management and query design. This is independent of columnstore technology. Use good statistics and avoid query design pitfalls to get the best performance. See the white paper on SQL Server statistics for guidance. In particular, see the section "Best Practices for Managing Statistics."
DON'Ts
(Note: we are already working to improve the implementation to eliminate limitations associated with these "don'ts" and we anticipate fixing them sometime after the SQL Server 2012 release. We're not ready to announce a timetable yet.) Later, we'll describe how to work around the limitations.
- Avoid joins and string filters directly on columns of columnstore-indexed tables. String filters don't get pushed down into scans on columnstore indexes, and join processing on strings is less efficient than on integers. Filters on number and date types are pushed down. Consider using integer codes (or surrogate keys) instead of strings in columnstore indexed fact tables. You can move the string values to a dimension table. Joins on the integer columns normally will be processed very efficiently.
- Avoid use of OUTER JOIN on columnstore-indexed tables. Outer joins don't benefit from batch processing. Instead, SQL Server 2012 reverts to row-at-a-time processing.
- Avoid use of NOT IN on columnstore-indexed tables. NOT IN (<subquery>) (which internally uses an operator called "anti-semi-join") can prevent batch processing and cause the system to revert to row mode. NOT IN (<list of constants>) typically works fine though.
- Avoid use of UNION ALL to directly combine columnstore-indexed tables with other tables. Batch processing doesn't get pushed down over UNION ALL. So, for example, creating a view vFact that does a UNION ALL of two tables, one with a columnstore indexes and one without, and then querying vFact in a star join query, will not use batch processing.
Maximizing Performance and Working Around Columnstore Limitations
Follow the links to the topics listed below about how to maximize performance with columnstores indexes, and work around their functional and performance limitations in SQL Server 2012.
Ensuring Use of the Fast Batch Mode of Query Execution
- Parallelism (DOP >= 2) is Required to Get Batch Processing
- Use Outer Join and Still Get the Benefit of Batch Processing
- Work Around Inability to get Batch Processing with IN and EXISTS
- Perform NOT IN and Still Get the Benefit of Batch Processing
- Perform UNION ALL and Still Get the Benefit of Batch Processing
- Perform Scalar Aggregates and Still get the Benefit of Batch Processing
- Maintaining Batch Processing with Multiple Aggregates Including one or More DISTINCT Aggregates
- Using HASH JOIN hint to avoid nested loop join and force batch processing
Physical Database Design, Loading, and Index Management
- Adding Data Using a Drop-and-Rebuild Approach
- Adding Data Using Partition Switching
- Trickle Loading with Columnstore Indexes
- Avoid Using Nonclustered B-tree Indexes
- Changing Your Application to Eliminate Unsupported Data Types
- Achieving Fast Parallel Columnstore Index Builds
Maximizing the Benefits of Segment Elimination
- Understanding Segment Elimination
- Verifying Columnstore Segment Elimination
- Ensuring Your Data is Sorted or Nearly Sorted by Date to Benefit from Date Range Elimination
- Multi-Dimensional Clustering to Maximize the Benefit of Segment Elimination
Additional Tuning Considerations
- Work Around Performance Issues for Columnstores Related to Strings
- Force Use or Non-Use of a Columnstore Index
- Workarounds for Predicates that Don't Get Pushed Down to Columnstore Scan (Including OR)
- Using Statistics with Columnstore Indexes
References
- MSDN: Columnstore Indexes Described (Has superseded the "SQL Server Columnstore Index FAQ" on TechNet Wiki)