Private Cloud Planning Guide for Operations
This document provides guidance for planning and designing the operations of a private cloud. It addresses operational design considerations based on the Private Cloud Principles and Concepts. This guide should be used by architects and consultants who are designing the operational processes, procedures, and best practiceshttp://blogs.technet.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-85-24-metablogapi/5658.image_5F00_64BCDD48.png for a private cloud. The reader should already be familiar with the Microsoft Operations Framework (MOF) and Information Technology Infrastructure Library (ITIL) models as well as the principles described in the Private Cloud Principles, Concepts, and Patterns document.
{kind=link}
Note:
This document is part of a collection of documents that comprise the Reference Architecture for Private Cloud document set. The Reference Architecture for Private Cloud documentation is a community collaboration project. Please feel free to edit this document to improve its quality. If you would like to be recognized for your work on improving this article, please include your name and any contact information you wish to share at the bottom of this page.
This article is no longer being updated by the Microsoft team that originally published it. It remains online for the community to update, if desired. Current documents from Microsoft that help you plan for cloud solutions with Microsoft products are found at the TechNet Library Solutions or Cloud and Datacenter Solutions pages.
1 The Private Cloud Operations Layer
The Private Cloud Reference Model shown here with the Operations Layer highlighted focuses on the primary functions within the Operations Layer that are impacted by the Private Cloud Principles and Concepts.

Figure 1: Private Cloud Reference Model
This document examines how the design decisions in each of these functions are guided by the Private Cloud Principles and Concepts.

2 The Operations Layer
The Operations Layer defines the operational processes and procedures necessary to deliver Information Technology (IT) as a Service. This layer leverages IT Service Management concepts that can be found in prevailing best practices such as ITIL and MOF. The main focus of the Operations Layer is to execute the business requirements defined at the Service Delivery Layer. Cloud-like service attributes cannot be achieved through technology alone and require a high level of IT Service Management maturity.
2.1 Change Management
Change Management process is responsible for controlling the life cycle of all changes. The primary objective of Change Management is to eliminate or at least minimize disruption while desired changes are made to services. Change Management focuses on understanding and balancing the cost and risk of making the change versus the benefit of the change to either the business or the service. Driving predictability and minimizing human involvement are the core principles for achieving a mature Service Management process and ensuring changes can be made without impacting the perception of continuous availability.
2.1.1 Minimize Human Involvement
The principle of minimizing human involvement is necessary for achieving infrastructure resiliency. A well-designed private cloud can dynamically perform operational tasks, automatically “detect and respond” to failure conditions in the environment, and elastically add or reduce capacity as required by the workloads. However, all of these actions are changes, and with each change comes risk.
Each change type must be categorized based on the risk of the change and processed through an appropriate approval process, as would occur in a traditional data center. The Change Advisory Board (CAB) will need to evaluate each change type and determine if a given change can be categorized as a Standard Change. Standard Changes are those changes that have been pre-approved by the CAB and therefore, can be fully automated since no further approval is necessary.
Non-Standard Changes will still need approval for each instance and therefore cannot be fully automated. However, it is recommended that these changes be mechanized wherever possible by automating those steps in the change process that do not require human involvement.
While a private cloud is in development, it is critical to thoroughly test all types of changes that are candidates for automation (for example, moving workloads across fault domains) and to acquire the needed approval from the CAB before they are automated. Similarly, each new service will require the same level of testing and CAB approval before deployment into production.
Standard (Automated) Change |
Non-Standard (Mechanized) Change |
||
Benefit |
Trade-off |
Benefit |
Trade-off |
|
|
|
|
Table 1: Automation vs. Mechanization
The following questions must be answered and defined in the change approval process for Non-Standard Changes:
- What human intervention is needed to evaluate the risk and approve the change?
- Who will make a decision on the intervention?
- What information does the CAB need to be able to make the decision?
- What must be done to make sure that the CAB has the necessary information as quickly as possible?
- After the decision has been made to go ahead with the change, can the rest of the change process be automated?
- What steps or checks require human intervention?
- After the change, what steps need to be taken to make sure that the change was successful?
It is important to note that a record of all changes must be maintained, including Standard Changes that have been automated. The automated process for Standard Changes should include the creation and population of the change record per standard policy in order to make sure auditability.
Automating changes also enables other key principles such as:
- Perception of Continuous Availability: Automated changes enable near real-time fabric management, allowing VMs to be moved throughout the resource pool as needed.
- Resiliency over Redundancy Mindset: Automated change is necessary to achieve infrastructure resiliency.
- Service Provider’s Approach to Delivering Infrastructure: Mature IT Service Management dictates that the risk of change is managed and only those change types with acceptable risk are automated.
- Drive Predictability: Automated workflow eliminates the chance of human error.
2.2 Service Asset and Configuration Management
The Service Asset and Configuration Management process is responsible for maintaining information on the assets, components, and infrastructure needed to provide a service. Critical configuration data for each component, and its relationship to other components, must be accurately captured and maintained. This configuration data should include past and current states and future-state forecasts, and be easily available to those who need it. Mature Service Asset and Configuration Management processes are necessary for achieving predictability.
2.2.1 Virtualized Infrastructure
A virtualized infrastructure adds complexity to the management of Configuration Items (CIs) due to the transient nature of the relationship between guests and hosts in the infrastructure. How is the relationship between CIs maintained in an environment that is potentially changing very frequently?
A service comprises software, platform, and infrastructure layers. Each layer provides a level of abstraction that is dependent on the layer beneath it. This abstraction hides the implementation and composition details of the layer. Access to the layer is provided through an interface and as long as the fabric is available, the actual physical location of a hosted VM is irrelevant. To provide Infrastructure as a Service (IaaS), the configuration and relationship of the components within the fabric must be understood, whereas the details of the configuration within the VMs hosted by the fabric are irrelevant.
The Configuration Management System (CMS) will need to be partitioned, at a minimum, into physical and logical CI layers. Two Configuration Management Databases (CMDBs) might be used; one to manage the physical CIs of the fabric (facilities, network, storage, hardware, and hypervisor) and the other to manage the logical CIs (everything else). The CMS can be further partitioned by layer, with separate management of the infrastructure, platform, and software layers. The benefits and trade-offs of each approach are summarized below.
CMS Partitioned by Layer |
CMS Partitioned into Physical and Logical |
||
Benefit |
Trade-off |
Benefit |
Trade-off |
|
|
|
|
Table 2: Configuration Management System Options
Partitioning logical and physical CI information allows for greater stability within the CMS, because CIs will need to be changed less frequently. This means less effort will need to be expended to accurately maintain the information. During normal operations, mapping a VM to its physical host is irrelevant. If historical records of a VM’s location are needed, (for example, for auditing or Root Cause Analysis) they can be traced through change logs.
2.2.2 Fabric Management
The physical or fabric CMDB will need to include a mapping of fault domains, upgrade domains, and Live Migration domains. The relationship of these patterns to the infrastructure CIs will provide critical information to the Fabric Management System.
2.3 Release and Deployment Management
The Release and Deployment Management processes are responsible for making sure that approved changes to a service can be built, tested, and deployed to meet specifications with minimal disruption to the service and production environment. Where Change Management is based on the approval mechanism (determining what will be changed and why), Release and Deployment Management will determine how those changes will be implemented.
2.3.1 Drive Predictability
The primary focus of Release and Deployment Management is to protect the production environment. The less variation is found in the environment, the greater the level of predictability – and, therefore, the lower the risk of causing harm when new elements are introduced. The concept of homogenization of physical infrastructure is derived from this predictability principle. If the physical infrastructure is completely homogenized, there is much greater predictability in the release and deployment process.
While complete homogenization is the ideal, it may not be achievable in the real world. Homogenization is a continuum. The closer an environment gets to complete homogeneity, the more predictable it becomes and the fewer the risks. Full homogeneity means not only that identical hardware models are used, but all hardware configuration is identical as well. When complete hardware homogeneity is not feasible, strive for configuration homogeneity wherever possible.
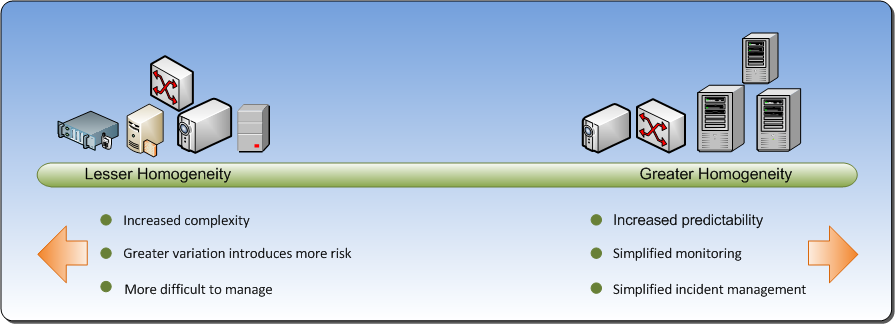
Figure 2: Homogenization Continuum
2.3.2 Scale Unit
The Scale Unit concept drives predictability in Capacity Planning and agility in the release and deployment of physical infrastructure. The hardware specifications and configurations have been pre-defined and tested, allowing for a more rapid deployment cycle than in a traditional data center. Similarly, known quantities of resources are added to the data center when the Capacity Plan is triggered. However, when the Scale Unit itself must change (for example, when a vendor retires a hardware model), a new risk is introduced to the private cloud.
There will likely be a period where both n and n-1 versions of the Scale Unit exist in the infrastructure, but steps can be taken to minimize the risk this creates. Work with hardware vendors to understand the life cycle of their products and coordinate changes from multiple vendors to minimize iterations of the Scale Unit change. Also, upgrading to the new version of the Scale Unit should take place one Fault Domain at a time wherever possible. This will make sure that if an incident occurs with the new version, it can be isolated to a single Fault Domain.
2.3.3 Homogenization of Physical Infrastructure
Homogenization of the physical infrastructure means consistency and predictability for the VMs regardless of which physical host they reside on. This concept can be extended beyond the production environment. The fabric can be partitioned into development, test, and pre-production environments as well. Eliminating variability between environments enables developers to more easily optimize applications for a private cloud and gives testers more confidence that the results reflect the realities of production, which in turn should greatly improve testing efficiency.
2.3.4 Virtualized Infrastructure
The virtualized infrastructure enables workloads to be transferred more easily between environments. All VMs should be built from a common set of component templates housed in a library, which is used across all environments. This shared library includes templates for all components approved for production, such as VM images, the gold OS image, server role templates, and platform templates. These component templates are downloaded from the shared library and become the building blocks of the development environment. From development, these components are packaged together to create a test candidate package (in the form of a virtual hard disk (VHD) that is uploaded to the library. This test candidate package can then be deployed by booting the VHD in the test environment. When testing is complete, the package can again be uploaded to the library as a release candidate package – for deployment into the pre-production environment, and ultimately into the production environment.
Since workloads are deployed by booting a VM from a VHD, the Release Management process occurs very quickly through the transfer of VHD packages to different environments. This also allows for rapid rollback should the deployment fail; the current release can be deleted and the VM can be booted off the previous VHD.
Virtualization and the use of standard VM templates allow us to rethink software updates and patch management. As there is minimal variation in the production environment and all services in production are built with a common set of component templates, patches need not be applied in production. Instead, they should be applied to the templates in the shared library. Any services in production using that template will require a new version release. The release package is then rebuilt, tested, and redeployed, as shown below.
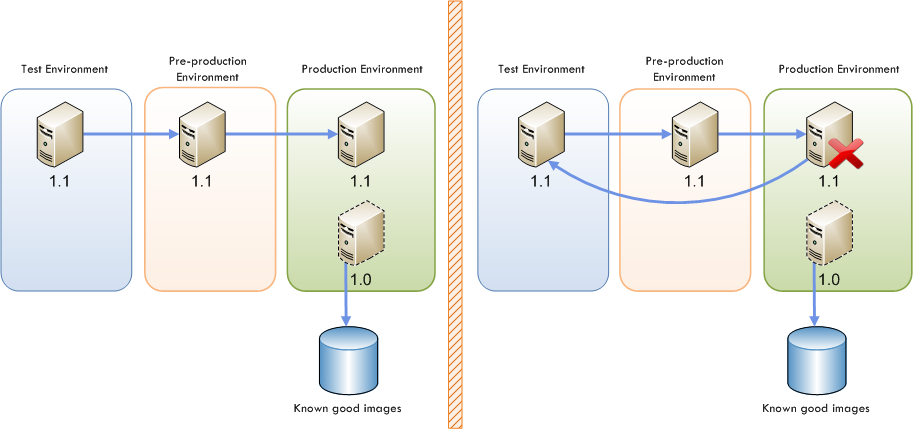
Figure 3: The Release Process
This may seem counter-intuitive for a critical patch scenario, such as when an exploitable vulnerability is exposed. But with virtualization technologies and automated test scripts, a new version of a service can be built, tested, and deployed quite rapidly.
2.3.5 Minimize Human Involvement
Variation can also be reduced through standardized, automated test scenarios. While not every test scenario can or should be automated, tests that are automated will improve predictability and facilitate more rapid test and deployment timelines. Test scenarios that are common for all applications, or the ones that might be shared by certain application patterns, are key candidates for automation. These automated test scripts may be required for all release candidates prior to deployment and would make sure further reduction in variation in the production environment.
2.4 Knowledge Management
Knowledge Management is the process of gathering, analyzing, storing, and sharing knowledge and information within an organization. The goal of Knowledge Management is to make sure that the right people have access to the information they need to maintain a private cloud. As operational knowledge expands and matures, the ability to intelligently automate operational tasks improves, providing for an increasingly dynamic environment.
2.4.1 Service Provider's Approach to Delivering Infrastructure
An immature approach to Knowledge Management costs organizations in terms of slower, less-efficient problem solving. Every problem or new situation that arises becomes a crisis that must be solved. A few people may have the prior experience to resolve the problem quickly and calmly, but their knowledge is not shared. Immature knowledge management creates greater stress for the operations staff and usually results in user dissatisfaction with frequent and lengthy unexpected outages. Mature Knowledge Management processes are necessary for achieving a service provider’s approach to delivering infrastructure. Past knowledge and experience is documented, communicated, and readily available when needed. Operating teams are no longer crisis-driven as service-impacting events grow less frequent and are quickly resolves when they do occur.
When designing a private cloud, development of the Health Model will drive much of the information needed for Knowledge Management. The Health Model defines the ideal states for each infrastructure component and the daily, weekly, monthly, and as-needed tasks required to maintain this state. The Health Model also defines unhealthy states for each infrastructure component and actions to be taken to restore their health. This information will form the foundation of the Knowledge Management database.
2.4.2 Drive Predictability
Aligning the Health Model with alerts allows these alerts to contain links to the Knowledge Management database describing the specific steps to be taken in response to the alert. This will help drive predictability as a consistent, proven set of actions will be taken in response to each alert.
2.4.3 Minimize Human Involvement
The final step toward achieving a private cloud is the automation of responses to each alert as defined in the Knowledge Management database. Once these responses are proven successful, they should be automated to the fullest extent possible. It is important to note, though, that automating responses to alerts does not make them invisible and forgotten. Even when alerts generate a fully automated response they must be captured in the Service Management system. If the alert indicates the need for a change, the change record should be logged. Similarly, if the alert is in response to an incident, an incident record should be created. These automated workflows must be reviewed regularly by Operations staff to make sure the automated action achieves the expected result. Finally, as the environment changes over time, or as new knowledge is gained, the Knowledge Management database must be updated along with the automated workflows that are based on that knowledge.
2.5 Incident and Problem Management
The goal of Incident Management is to resolve events that are impacting, or threaten to impact, services as quickly as possible with minimal disruption. The goal of Problem Management is to identify and resolve root causes of incidents that have occurred as well as identify and prevent or minimize the impact of incidents that may occur.
2.5.1 Virtualized Infrastructure
Pinpointing the root cause of an incident can become more challenging when workloads are abstracted from the infrastructure and their physical location changes frequently. Additionally, incident response teams may be unfamiliar with virtualization technologies (at least initially) which could also lead to delays in incident resolution. Finally, applications may have neither a robust Health Model nor expose all of the health information required for a proactive response. All of this may lead to an increase in reactive (user initiated) incidents which will likely increase the Mean-Time-to-Restore-Service (MTRS) and customer dissatisfaction.
This may seem to go against the resiliency principle, but note that virtualization alone will not achieve the desired resiliency unless accompanied by highly mature IT Service Management (ITSM) maturity and a robust automated health monitoring system.
2.5.2 Resiliency over Redundancy
The drive for resiliency requires a different approach to troubleshooting incidents. Extensive troubleshooting of incidents in production negatively impacts resiliency. Therefore, if an incident cannot be quickly resolved, the service can be rolled back to the previous version, as described under Release and Deployment. Further troubleshooting can be done in a test environment without impacting the production environment. Troubleshooting in the production environment may be limited to moving the service to different hosts (ruling out infrastructure as the cause) and rebooting the VMs. If these steps do not resolve the issue, the rollback scenario could be initiated.
2.5.3 Minimizing Human Involvement
Minimizing human involvement in incident management is critical for achieving resiliency. The troubleshooting scenarios described earlier could be automated, which will allow for identification and possible resolution of the root much more quickly than non-automated processes. But automation may mask the root cause of the incident. Careful consideration should be given to determining which troubleshooting steps should be automated and which require human analysis.
Automated Troubleshooting |
Human Analysis of Troubleshooting |
||
Benefit |
Trade-off |
Benefit |
Trade-off |
|
|
|
|
2.5.4 Compute Resource Decay
If a compute resource fails, it is no longer necessary to treat the failure as an incident that must be fixed immediately. It may be more efficient and cost effective to treat the failure as part of the decay of the Resource Pool. Rather than treat a failed server as an incident that requires immediate resolution, treat it as a natural candidate for replacement on a regular maintenance schedule, or when the Resource Pool reaches a certain threshold of decay. Each organization must balance cost, efficiency, and risk as it determines an acceptable decay threshold – and choose among these courses of action:
- Replace all failed servers on a regular maintenance schedule.
- Replace all failed servers when a certain percent have failed.
- Replace an entire Scale Unit when server decay within the Scale Unit reaches a certain threshold.
- Continue to treat a failed server as an incident.
The benefits and trade-off of each of the options are listed below:
| Option 1: Replace on Regular Maintenance Schedule | |
Benefit |
Trade-off |
|
|
| Option 2: Replace on Percent of Decay | |
Benefit |
Trade-off |
|
|
| Option 3: Replace When it Reaches Threshold of Decay | |
Benefit |
Trade-off |
|
|
| Option 4: Continue to Treat Component Failures as Incidents | |
Benefit |
Trade-off |
|
|
Option 4 is the least desirable, as it does not take advantage of the resiliency and cost reduction benefits of a private cloud. A well-planned Resource Pool and Reserve Capacity strategy will account for Resource Decay.
Option 1 is the most recommended approach. A predictable maintenance schedule allows for better procurement planning and can help avoid conflicts with other maintenance activities, such as software upgrades. Again, a well-planned Resource Pool and Reserve Capacity strategy will account for Resource Decay and minimize the risk of exceeding critical thresholds before the scheduled maintenance.
Option 3 will likely be the only option for self-contained Scale Unit scenarios, as the container must be replaced as a single Scale Unit when the decay threshold is reached.
2.6 Request Fulfillment
The goal of Request Fulfillment is to manage requests for service from users. Users should have a clear understanding of the process they need to initiate to request service and IT should have a consistent approach for managing these requests.
2.6.1 Service Provider's Approach
Much like any service provider, IT should clearly define the types of requests available to users in the service catalog. The service catalog should include an SLA on when the request will be completed, as well as the cost of fulfilling the request, if any.
2.6.2 Encourage Desired Consumer Behavior
The types of requests available and their associated costs should reflect the actual cost of completing the request and this cost should be easily understood. For example, if a user requests an additional VM, its daily cost should be noted on the request form, which should also be exposed to the organization or person responsible for paying the bill.
It is relatively easy to see the need for adding resources, but more difficult to see when a resource is no longer needed. A process for identifying and removing unused VMs should be put into place. There are a number of strategies to do this, depending on the needs of a given organization, such as:
- The VM owner is responsible for determining when a VM should be decommissioned. The VM will continue to exist and the VM owner will be charged until the time they indicate that the VM is no longer needed.
- VMs expire on a timer if they are not renewed. When the expiration date approaches, the owner will be notified and will have to take action to renew the expiration timer.
- VMs are automatically deleted when they remain under a utilization threshold for a period of time.
- The user can select an expiration date at the time a VM is created.
The benefits and trade-offs of each of these approaches are detailed below:
| Option 1: VM owner will indicate when to decommission the VM | |
Benefit |
Trade-off |
|
|
| Option 1: VM expire on timer if not renewed by owner | |
Benefit |
Trade-off |
|
|
| Option 3: VM is decommissioned when utilization remains under a certain threshold | |
Benefit |
Trade-off |
|
|
| Option 4: Owner can select timer at time of VM creation | |
Benefit |
Trade-off |
|
|
Option 4 affords the greatest flexibility, while still working to minimize server sprawl. When a user requests a VM, they have the option of setting an expiration date with no reminder (for example, if they know they will only be using the workload for one week). They could set an expiration deadline with a reminder (for example, a reminder that the VM will expire after 90 days unless they wish to renew). Lastly, the user may request no expiration date if they expect the workload will always be needed. If the last option is chosen, it is likely that underutilized VMs will still be monitored and owners notified.
2.6.3 Minimizing Human Involvement
Finally, self-provisioning should be considered, if appropriate, when evaluating request fulfillment options to drive towards minimal human involvement. Self-provisioning allows great agility and user empowerment, but it can also introduce risks depending on the nature of the environment in which these VMs are introduced.
For an enterprise organization, the risk of bypassing formal build, stabilize, and deploy processes may or may not outweigh the agility benefits gained from the self-provisioning option. Without strong governance to make sure each VM has an end-of-life strategy, the fabric may become congested with VM server sprawl. The pros and cons of self-provisioning options are listed in the next diagram:
Self-provisioning |
No Self-provisioning |
||
Benefit |
Trade-off |
Benefit |
Trade-off |
|
|
|
|
The primary decision point for determining whether to use self-provisioning is the nature of the environment. Allowing developers to self-provision into the development environment greatly facilitates agile development, and allows the enterprise to maintain release management controls as these workloads are moved out of development and into test and production environments.
A user-led community environment isolated from enterprise mission-critical applications may also be a good candidate for self-provisioning. As long as user actions are isolated and cannot impact mission critical applications, the agility and user empowerment may justify the risk of giving up control of release management. Again, it is essential that in such a scenario, expiration timers are included to prevent server sprawl.
2.7 Access Management
The goal of Access Management is to make sure authorized users have access to the services they need while preventing access by unauthorized users. Access Management is the implementation of security policies defined by Information Security Management at the Service Delivery Layer.
2.7.1 Perception of Continuous Availability
Maintaining access for authorized users is critical for achieving the perception of continuous availability. Besides allowing access, Access Management defines users who are allowed to use, configure, or administer objects in the Management Layer. From a provider’s perspective, it answers questions like:
- Who has access to service reporting?
- Which users are allowed to deploy and provision machines in the cloud?
From a consumer’s perspective, it answers questions such as:
- Who is allowed to manage the database?
- Who is allowed to administer the business application?
Access Management is implemented at several levels and can include physical barriers to systems such as requiring access smartcards at the data center, or virtual barriers such as network and Virtual Local Area Network (VLAN) separation, firewalling, and access to storage and applications.
2.7.2 Take a Service Provider's Approach
Taking a service provider’s approach to Access Management will also make sure that resource segmentation and multi-tenancy is addressed.
Resource Pools may need to be segmented to address security concerns around confidentiality, integrity, and availability. Some tenants may not wish to share infrastructure resources to keep their environment isolated from others. Access Management of shared infrastructure requires logical access control mechanisms such as encryption, access control rights, user groupings, and permissions. Dedicated infrastructure also relies on physical access control mechanisms, where infrastructure is not physically connected, but is effectively isolated through a firewall or other mechanisms.
2.8 Systems Administration
The goal of systems administration is to make sure that the daily, weekly, monthly, and as-needed tasks required to keep a system healthy are being performed.
Regularly performing ongoing systems administration tasks is critical for achieving predictability. As the organization matures and the Knowledge Management database becomes more robust and increasingly automated, systems administration tasks is no longer part of the job role function. It is important to keep this in mind as an organization moves to a private cloud. Staff once responsible for systems administration should refocus on automation and scripting skills – and on monitoring the fabric to identify patterns that indicate possibilities for ongoing improvement of existing automated workflows.
REFERENCES:
ACKNOWLEDGEMENTS LIST:
If you edit this page and would like acknowledgement of your participation in the v1 version of this document set, please include your name below:
[Enter your name here and include any contact information you would like to share]