Private Cloud Principles, Concepts, and Patterns
A key goal is to enable IT organizations to leverage the principles and concepts described in Reference Architecture for Private Cloud content set to offer Infrastructure as a Service (IaaS), allowing any workload hosted on this infrastructure to automatically inherit a set of Cloud-like attributes. Fundamentally, the consumer should have the perception of infinite capacity and continuous availability of the services they consume. They should also see a clear correlation between the amount of services they consume and the price they pay for these services.
Achieving this requires virtualization of all elements of the infrastructure (compute [processing and memory], network, and storage) into a fabric that is presented to the container, or the virtual machine (VM). It also requires the IT organization to take a service provider’s approach to delivering infrastructure, necessitating a high degree of IT Service Management maturity. Moreover, most of the operational functions must be automated to minimize the variance as much as possible while creating a set of predictable models that simplify management.
Finally, it is vital to ensure that the infrastructure is designed in a way that services, applications, and workloads can be delivered independently from where they are originally sourced or provided. Thus, one of the major goals is to enable portability between a customer’s private cloud and external public cloud platforms and providers.

Therefore, this requires a strong service quality driven, consumer oriented approach as opposed to a “feature” or capability oriented approach. Although this approach is not orthogonal to other approaches, it may seem counterintuitive at first. This documentation defines the process elements for planning, building, and managing a private cloud environment with a common set of best practices.
Note:
This document is part of a collection of documents that comprise the Reference Architecture for Private Cloud document set. The Solution for Private Cloud is a community collaboration project. Please feel free to edit this document to improve its quality. If you would like to be recognized for your work on improving this document, please include your name and any contact information at the bottom of this page.
An updated version of this article is now available as part of the Cloud Services Foundation Reference Architecture article set. For additional cloud and datacenter architectural and solution guidance, please visit the Microsoft Cloud and Data Center Solutions Hub.
1 Principles
The principles outlined in this section provide general rules and guidelines to support the evolution of a cloud infrastructure. They are enduring, seldom amended, and inform and support the way a cloud fulfills its mission and goals. They also strive to be compelling and aspirational in some respects since there needs to be a connection with business drivers for change. These principles are often interdependent and together form the basis on which a cloud infrastructure is planned, designed and created.
1.1 Achieve Business Value through Measured Continual Improvement
Statement:
The productive use of technology to deliver business value should be measured via a process of continual improvement.
Rationale:
All investments into IT services need to be clearly and measurably related to delivering business value. Often the returns on major investments into strategic initiatives are managed in the early stages but then tail off, resulting in diminishing returns. By continuously measuring the value which a service is delivering to a business, improvements can be made which achieve the maximum potential value. This ensures the use of evolving technology to the productive benefit of the consumer and the efficiency of the provider. Adhered to successfully, this principle results in a constant evolution of IT services which provide the agile capabilities that a business requires to attain and maintain a competitive advantage.
Implications:
The main implication of this principle is the requirement to constantly calculate the current and future return from investments. This governance process needs to determine if there is still value being returned to the business from the current service architecture and, if not, determine which element of the strategy needs to be adjusted.
1.2 Perception of Infinite Capacity
Statement:
From the consumer’s perspective, a cloud service should provide capacity on demand, only limited by the amount of capacity the consumer is willing to pay for.
Rationale:
IT has historically designed services to meet peak demand, which results in underutilization that the consumer must pay for. Likewise, once capacity has been reached, IT must often make a monumental investment in time, resources and money in order to expand existing capacity, which may negatively impact business objectives. The consumer wants “utility” services where they pay for what they use and can scale capacity up or down on demand.
Implications:
A highly mature capacity management strategy must be employed by the provider in order to deliver capacity on demand. Predictable units of network, storage and compute should be pre-defined as scale units. The procurement and deployment times for each scale unit must be well understood and planned for. Therefore, Management tools must be programmed with the intelligence to understand scale units, procurement and deployment times, and current and historical capacity trends that may trigger the need for additional scale units. Finally, the provider (IT) must work closely with the consumer (the business) to understand new and changing business initiatives that may change historical capacity trends. The process of identifying changing business needs and incorporating these changes into the capacity plan will be critical to the providers Capacity Management processes.
1.3 Perception of Continuous Service Availability
Statement:
From the consumer’s perspective, a cloud service should be available on demand from anywhere and on any device.
Rationale:
Traditionally, IT has been challenged by the availability demands of the business. Technology limitations, architectural decisions and lack of process maturity all lead to increased likelihood and duration of availability outages. High availability services can be offered, but only after a tremendous investment in redundant infrastructure. Access to most services has often been limited to on-premises access due to security implications. Cloud services must provide a cost-effective way of maintaining high availability and address security concerns so that services can be made available over the internet.
Implications:
In order to achieve cost-effective highly available services, IT must create a resilient infrastructure and reduce hardware redundancy wherever possible. Resiliency can only be achieved through highly automated fabric management and a high degree of IT service management maturity. In a highly resilient environment, it is expected that hardware components will fail. A robust and intelligent fabric management tool is needed to detect early signs of eminent failure so that workloads can be quickly moved off of failing components, ensuring the consumer continues to experience service availability. Legacy applications may not be designed to leverage a resilient infrastructure and some applications may need to be redesigned or replaced in order to achieve cost-effective high availability.
Likewise, in order to allow service access from anywhere, it must be proven that security requirements can be met when access occurs over the internet. Finally, for a true cloud-like experience, considerations should be made to ensure the service can be accessed from the wide array of mobile devices that exist today.
1.4 Take a Service Provider’s Approach
Statement:
The provider of a cloud should think and behave like they are running a Service Provider business rather than an IT department within an Enterprise.
Rationale:
Enterprise IT is often driven and funded by business initiatives which encourages a silo approach and leads to inefficiencies. Solution Architects may feel it is simply too risky to share significant infrastructure between solutions. The impact of one solution on another cannot be eliminated and therefore each solution builds its own infrastructure, only sharing capabilities where there is high confidence. The result is the creation of projects that increase efficiencies (e.g. virtualization & data center consolidation).
A cloud service is a shared service, and therefore needs to be defined in a way that gives the consumer confidence to adopt it; its capabilities, performance and availability characteristics are clearly defined. At the same time, the cloud needs to show value to the organization. Because Service Providers sell to customers, there is a clear separation between the provider and the customer/consumer. This relationship drives the provider to define services from capability, capacity, performance, availability and financial perspectives. Enterprise IT needs to take this same approach in offering services to the business.
Implications:
Taking a Service Provider’s approach requires a high degree of IT Service Management maturity. IT must have a clear understanding of the service levels they can achieve and must consistently meet these targets. IT must also have a clear understanding of the true cost of providing a service and must be able to communicate to the business the cost of consuming the service. There must be a robust capacity management strategy to ensure demand for the service can be met without disruption and with minimal delay. IT must also have a high fidelity view of the health of the service and have automated management tools to monitor and respond to failing components quickly and proactively so that there is no disruption to the service.
1.5 Optimization of Resource Usage
Statement:
The cloud should automatically make efficient and effective use of infrastructure resources.
Rationale:
Resource optimization drives efficiency and cost reduction and is primarily achieved through resource sharing. Abstracting the platform from the physical infrastructure enables realization of this principle through shared use of pooled resources. Allowing multiple consumers to share resources results in higher resource utilization and a more efficient and effective use of the infrastructure. Optimization through abstraction enables many of the other principles and ultimately helps drive down costs and improve agility.
Implications:
The IT organization providing a service needs to clearly understand the business drivers to ensure appropriate emphasis during design and operations.
The level of efficiency and effectiveness will vary depending on time/cost/quality drivers for a cloud. In one extreme, the cloud may be built to minimize the cost, in which case the design and operation will maximize efficiency via a high degree of sharing. At the other extreme, the business driver may be agility in which case the design focuses on the time it takes to respond to changes and will therefore likely trade efficiency for effectiveness.
1.6 Take a Holistic Approach to Availability Design
Statement:
The availability design for a solution should involve all layers of the stack and employ resilience wherever possible and remove redundancy that is unnecessary.
Rationale:
Traditionally, IT has provided highly available services through a strategy of redundancy. In the event of component failure, a redundant component would be standing by to pick up the workload. Redundancy is often applied at multiple layers of the stack, as each layer does not trust that the layer below will be highly available. This redundancy, particularly at the Infrastructure Layer, comes at a premium price in capital as well as operational costs.
A key principle of a cloud is to provide highly available services through resiliency. Instead of designing for failure prevention, a cloud design accepts and expects that components will fail and focuses instead on mitigating the impact of failure and rapidly restoring service when the failure occurs. Through virtualization, real-time detection and automated response to health states, workloads can be moved off the failing infrastructure components often with no perceived impact on the service.
Implications:
Because the cloud focuses on resilience, unexpected failures of infrastructure components (e.g. hosting servers) will occur and will affect machines. Therefore, the consumer needs to expect and plan for machine failures at the application level. In other words, the solution availability design needs to build on top of the cloud resilience and use application-level redundancy and/or resilience to achieve the availability goals. Existing applications may not be good tenants for such an infrastructure, especially those which are stateful and assume a redundant infrastructure. Stateless workloads should cope more favorably provided that resilience is handled by the application or a load balancer, for example.
1.7 Minimize Human Involvement
Statement:
The day-to-day operations of a cloud should have minimal human involvement.
Rationale:
The resiliency required to run a cloud cannot be achieved without a high degree of automation. When relying on human involvement for the detection and response to failure conditions, continuous service availability cannot be achieved without a fully redundant infrastructure. Therefore, a fully automated fabric management system must be used to perform operational tasks dynamically, detect and respond automatically to failure conditions in the environment, and elastically add or reduce capacity as workloads require. It is important to note that there is a continuum between manual and automated intervention that must be understood.
A manual process is where all steps require human intervention. A mechanized process is where some steps are automated, but some human intervention is still required (such as detecting that a process should be initiated or starting a script). To be truly automated, no aspect of a process, from its detection to the response, should require any human intervention.
Implications:
Automated fabric management requires specific architectural patterns to be in place, which are described later in this document. The fabric management system must have an awareness of these architectural patterns, and must also reflect a deep understanding of health. This requires a high degree of customization of any automated workflows in the environment.
1.8 Drive Predictability
Statement:
A cloud must provide a predictable environment, as the consumer expects consistency in the quality and functionality of the services they consume.
Rationale:
Traditionally, IT has often provided unpredictable levels of service quality. This lack of predictability hinders the business from fully realizing the strategic benefit that IT could provide. As public cloud offerings emerge, businesses may choose to utilize public offerings over internal IT in order to achieve greater predictability. Therefore, enterprise IT must provide a predictable service on par with public offerings in order to remain a viable option for businesses to choose.
Implications:
For IT to provide predictable services, they must deliver an underlying infrastructure that assures a consistent experience to the hosted workloads in order to achieve this predictability. This consistency is achieved through the homogenization of underlying physical servers, network devices, and storage systems. In addition to homogenization of infrastructure, a very high level of IT Service Management maturity is also required to achieve predictability. Well managed change, configuration and release management processes must be adhered to, and highly effective, highly automated incident and problem management processes must be in place.
1.9 Incentivize Desired Behavior
Statement:
IT will be more successful in meeting business objectives if the services it offers are defined in a way that incentivizes desired behavior from the service consumer.
Rationale:
Most business users, when asked what level of availability they would like for a particular application, will usually ask for 99.999% or even 100% uptime when making a request of IT to deliver a service. This typically stems from the lack of insight into the true cost of delivering service on the part of the consumer as well as the IT provider. If the IT provider, for example, we’re to provide a menu style set of service classifications where the cost of delivering to requirements such as 99.999% availability were very obvious, there would be an immediate injection of reality in the definition of business needs and hence expectations of IT.
For a different, more technical example, many organizations who have adopted virtualization have found it leads to a new phenomenon of virtual server sprawl, where Virtual Machines (VM) were created on demand, but there were no incentives for stopping or removing VMs when they were no longer needed. The perception of infinite capacity may result in consumers using capacity as a replacement for effective workload management. While unlimited capacity may be perceived as an improvement in the quality and agility of a service, used irresponsibly it negatively impacts the cost of the cloud capability.
In the case above, the cloud provider wants to incentivize the consumers to use only the resources they need. This could be achieved via billing or reporting on consumption.
Encouraging desired consumer behavior is a key principle and is related to the principle of taking a service provider approach.
In the electrical utility example, consumers are encouraged to use less, and are charged a lower multiplier when utilization is below an agreed threshold. If they reach the upper bounds of the threshold, a higher multiplier kicks in as additional resources are consumed.
Implications:
The IT organization needs to identify the behavior they want to incent. The example above was related to inefficient resource usage, other examples include reducing helpdesk calls (charging per call), using the right level of redundancy (charge more for higher redundancy). Each requires a mature service management capability; e.g. metering and reporting on usage per business unit, tiered services in the product/service catalog and a move to a service-provider relationship with the business. The incentives should be defined during the product/service design phase.
1.10 Create a Seamless User Experience
Statement:
Consumers of an IT service should not encounter anything which disrupts their use of the service as a result of crossing a service provider boundary.
Rationale:
IT strategies increasingly look to incorporate service from multiple providers to achieve the most cost effective solution for a business. As more of the services delivered to consumers are provided by a hybrid of providers, the potential for disruption to consumption increases as business transactions cross provider boundaries. The fact that a composite service being delivered to a consumer is sourced from multiple providers should be completely opaque and the consumer should experience no break in continuity of usage as a result.
An example of this may be a consumer who is using a business portal to access information across their organization such as the status of a purchase order. They may look at the order through the on premise order management system and click on a link to more detailed information about the purchaser which is held in a CRM system in a public cloud. In crossing the boundary between the on premise system and the public cloud based system the user should see no hindrance to their progress which would result in a reduction in productivity. There should be no requests for additional verification and they should encounter a consistent look and feel, and performance should be consistent across the whole experience. These are just a few examples of how this principle should be applied.
Implications:
The IT provider needs to identify potential causes of disruption to the activities of consumers across a composite service. Security systems may need to be federated to allow for seamless traversal of systems, data transformation may be required to ensure consistent representation of business records, styling may need to be applied to give the consumer more confidence that they are working within a consistent environment.
The area where this may have most implications is in the resolution of incidents raised by consumers. As issues occur, the source of them may not be immediately obvious and require complex management across providers until the root cause has been established. The consumer should be oblivious to this combined effort which goes on behind a single point of contact within the service delivery function.
2 Concepts
The following concepts are abstractions or strategies that support the principles and facilitate the composition of a cloud. They are guided by and directly support one or more of the principles above.
2.1 Predictability
Traditionally, IT has often provided unpredictable levels of service quality. This lack of predictability hinders the business from fully realizing the strategic benefit that IT could provide. As public cloud offerings emerge, businesses may choose to utilize public offerings over internal IT in order to achieve greater predictability. Enterprise IT must provide a predictable service on par with public offerings in order to remain a viable option for businesses to choose.
For IT to provide predictable services, they must deliver an underlying infrastructure that assures a consistent experience to the hosted workloads in order to achieve this predictability. This consistency is achieved through the homogenization of underlying physical servers, network devices, and storage systems. In addition to homogenizing of the infrastructure, a very high level of IT Service Management maturity is also required to achieve predictability. Well managed change, configuration and release management processes must be adhered to and highly effective, highly automated incident and problem management processes must be in place.
2.2 Favor Resiliency Over Redundancy
In order to achieve the perception of continuous availability, a holistic approach must be taken in the way availability is achieved. Traditionally, availability has been the primary measure of the success of IT service delivery and is defined through service level targets that measure the percentage of uptime. However, defining the service delivery success solely through availability targets creates the false perception of “the more nines the better” and does not account for how much availability the consumers actually need.
There are two fundamental assumptions behind using availability as the measure of success. First, that any service outage will be significant enough in length that the consumer will be aware of it and second, that there will be a significant negative impact to the business every time there is an outage. It is also a reasonable assumption that the longer it takes to restore the service, greater the impact on the business.
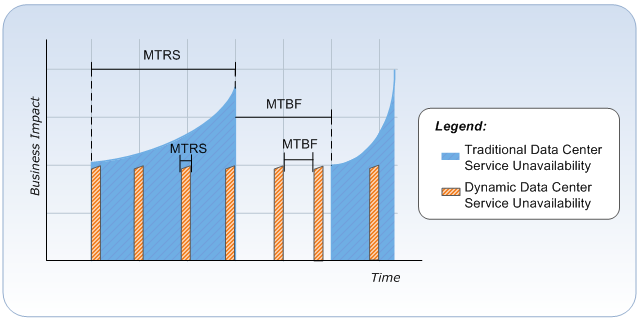
There are two main factors that affect availability. First is reliability which is measured by Mean-Time-Between-Failures (MTBF). This measures the time between service outages. Second is resiliency which is measured by Mean-Time-to-Restore-Service (MTRS). MTRS measures the total elapsed time from the start of a service outage to the time the service is restored. The fact that human intervention is normally required to detect and respond to incidents limits how much MTRS can be reduced. Therefore organizations have traditionally focused on MTBF to achieve availability targets. Achieving higher availability through greater reliability requires increased investment in redundant hardware and an exponential increase in the cost of implementing and maintaining this hardware.
Using the holistic approach, a cloud achieves higher levels of availability and resiliency by replacing the traditional model of physical redundancy with software tools. The first tool that helps achieve this is virtualization. It provides a means of abstracting the service from a specific server thereby increasing its portability. The second software tool is Hypervisor. Technologies provided by the hypervisor can allow either the transparent movement or restart of the workload to other virtualization hosts, thereby increasing resiliency and availability without any other specialized software running within the workload. The final tool is a health model that allows IT to fully understand hardware health status and automatically respond to failure conditions by migrating services away from the failing hardware.
While the compute components no longer require hardware redundancy, the storage components continue to require it. In addition, network components require hardware redundancy to support needs of the storage systems. While current network and storage requirements prevent the complete elimination of hardware redundancy, significant cost savings can still be gained by removing the compute hardware redundancy.
In a traditional data center, the MTRS may average well over an hour while a cloud can recover from failures in a matter of seconds. Combined with the automation of detection and response to failure and warn states within the infrastructure, this can reduce the MTRS (from the perspective of IaaS) dramatically. Thus a significant increase in resiliency makes the reliability factor much less important. In a cloud, availability (minutes of uptime/year) is no longer the primary measure of the success of IT service delivery. The perception of availability and the business impact of unavailability become the measures of success. This chart illustrates these points.
2.3 Homogenization of Physical Hardware
Homogenization of the physical hardware is a key concept for driving predictability. The underlying infrastructure must provide a consistent experience to the hosted workloads in order to achieve predictability. This consistency is attained through the homogenization of the underlying servers, network, and storage.
Abstraction of services from the hardware layer through virtualization makes “server stock-keeping units (SKU) differentiation” a logical rather than a physical construct. This eliminates the need for differentiation at the physical server level. Greater homogenization of compute components results in a greater reduction in variability. This reduction in variability increases the predictability of the infrastructure which, in turn, improves service quality.
The goal is to ultimately homogenize the compute, storage, and network layers to the point where there is no differentiation between servers. In other words, every server has the same processor and random access memory (RAM); every server connects to the same storage resource; and every server connects to the same networks. This means that any virtualized service runs and functions identically on any physical server and so it can be relocated from a failing or failed physical server to another physical server seamlessly without any change in service behavior.
It is understood that full homogenization of the physical infrastructure may not be feasible. While it is recommended that homogenization be the strategy, where this is not possible, the compute components should at least be standardized to the fullest extent possible. Whether or not the customer homogenizes their compute components, the model requires them to be homogeneous in their storage and network connections so that a Resource Pool may be created to host virtualized services.
It should be noted that homogenization has the potential to allow for a focused vendor strategy for economies of scale. Without this scale however, there could be a negative impact on cost, where homogenizing hardware detracts from the buying power that a multi-vendor strategy can facilitate.
2.4 Pool Compute Resources
Leveraging a shared pool of compute resources is key to cloud computing. This Resource Pool is a collection of shared resources composed of compute, storage, and network that create the fabric that hosts virtualized workloads. Subsets of these resources are allocated to the customers as needed and conversely, returned to the pool when they are not needed. Ideally, the Resource Pool should be homogeneous. However, as previously mentioned, the realities of a customer’s current infrastructure may not facilitate a fully homogenized pool.
2.5 Virtualized Infrastructure
Virtualization is the abstraction of hardware components into logical entities. Although virtualization occurs differently in each infrastructure component (server, network, and storage), the benefits are generally the same including lesser or no downtime during resource management tasks, enhanced portability, simplified management of resources, and the ability to share resources. Virtualization is the catalyst to the other concepts, such as Elastic Infrastructure, Partitioning of Shared Resources, and Pooling Compute Resources. The virtualization of infrastructure components needs to be seamlessly integrated to provide a fluid infrastructure that is capable of growing and shrinking, on demand, and provides global or partitioned resource pools of each component.
2.6 Fabric Management
Fabric is the term applied to the collection of compute, network, and storage resources. Fabric Management is a level of abstraction above virtualization; in the same way that virtualization abstracts physical hardware, Fabric Management abstracts service from specific hypervisors and network switches. Fabric Management can be thought of as an orchestration engine, which is responsible for managing the life cycle of a consumer’s workload. In a cloud, Fabric Management responds to service requests, Systems Management events and Service Management policies.
Traditionally, servers, network and storage have been managed separately, often on a project-by-project basis. To ensure resiliency, a cloud must be able to automatically detect if a hardware component is operating at a diminished capacity or has failed. This requires an understanding of all of the hardware components that work together to deliver a service, and the interrelationships between these components. Fabric Management provides this understanding of interrelationships to determine which services are impacted by a component failure. This enables the Fabric Management system to determine if an automated response action is needed to prevent an outage, or to quickly restore a failed service onto another host within the fabric.
From a provider's point of view, the Fabric Management system is key in determining the amount of Reserve Capacity available and the health of existing fabric resources. This also ensures that services are meeting the defined service levels required by the consumer.
2.7 Elastic Infrastructure
The concept of an elastic infrastructure enables the perception of infinite capacity. An elastic infrastructure allows resources to be allocated on demand and more importantly, returned to the Resource Pool when no longer needed. The ability to scale down when capacity is no longer needed is often overlooked or undervalued, resulting in server sprawl and lack of optimization of resource usage. It is important to use consumption-based pricing to incent consumers to be responsible in their resource usage. Automated or customer request based triggers determine when compute resources are allocated or reclaimed.
Achieving an elastic infrastructure requires close alignment between IT and the business, as peak usage and growth rate patterns need to be well understood and planned for as part of Capacity Management.
2.8 Partitioning of Shared Resources
Sharing resources to optimize usage is a key principle; however, it is also important to understand when these shared resources need to be partitioned. While a fully shared infrastructure may provide the greatest optimization of cost and agility, there may be regulatory requirements, business drivers, or issues of multi-tenancy that require various levels of resource partitioning. Partitioning strategies can occur at many layers, such as physical isolation or network partitioning. Much like redundancy, the lower in the stack this isolation occurs, the more expensive it is. Additional hardware and Reserve Capacity may be needed for partitioning strategies such as separation of resource pools. Ultimately, the business will need to balance the risks and costs associated with partitioning strategies and the cloud infrastructure will need the capability of providing a secure method of isolating the infrastructure and network traffic while still benefiting from the optimization of shared resources.
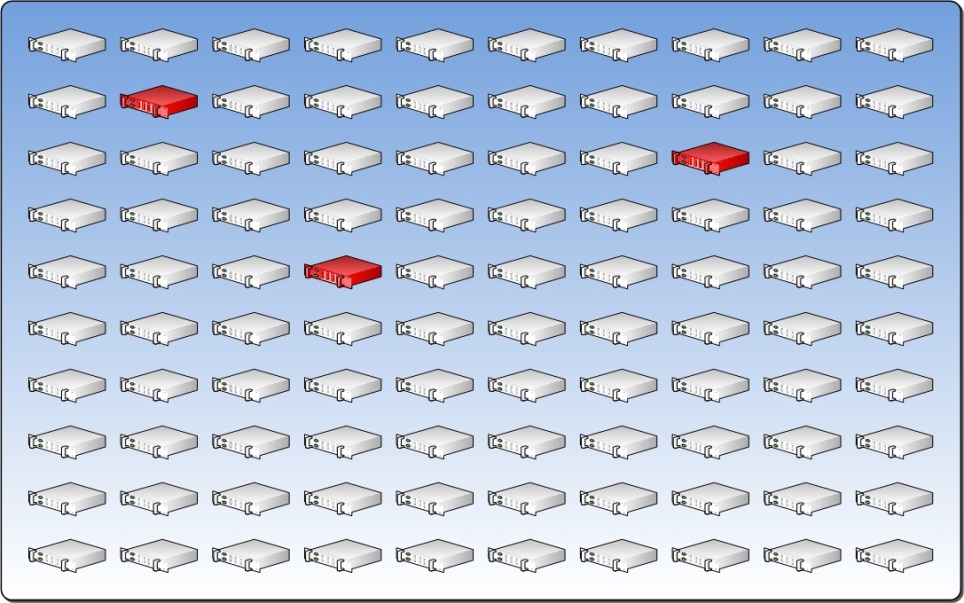
2.9 Resource Decay
Treating infrastructure resources as a single Resource Pool allows the infrastructure to experience small hardware failures without significant impact on the overall capacity. Traditionally, hardware is serviced using an incident model, where the hardware is fixed or replaced as soon as there is a failure. By leveraging the concept of a Resource Pool, hardware can be serviced using a maintenance model. A percentage of the Resource Pool can fail because of “decay” before services are impacted and an incident occurs. Failed resources are replaced on a regular maintenance schedule or when the Resource Pool reaches a certain threshold of decay instead of a server-by-server replacement.
The Decay Model requires the provider to determine the amount of “decay” they are willing to accept before infrastructure components are replaced. This allows for a more predictable maintenance cycle and reduces the costs associated with urgent component replacement.
For example, a customer with a Resource Pool containing 100 servers may determine that up to 3 percent of the Resource Pool may decay before an action is taken. This will mean that 3 servers can be completely inoperable before an action is required.
2.10 Service Classification
Service classification is an important concept for driving predictability and incenting consumer behavior. Each service class will be defined in the provider’s service catalog, describing service levels for availability, resiliency, reliability, performance, and cost. Each service must meet pre-defined requirements for its class. These eligibility requirements reflect the differences in cost when resiliency is handled by the application versus when resiliency is provided by the infrastructure.
The classification allows consumers to select the service they consume at a price and the quality point that is appropriate for their requirements. The classification also allows for the provider to adopt a standardized approach to delivering a service which reduces complexity and improves predictability, thereby resulting in a higher level of service delivery.
2.11 Cost Transparency
Cost transparency is a fundamental concept for taking a service provider’s approach to delivering infrastructure. In a traditional data center, it may not be possible to determine what percentage of a shared resource, such as infrastructure, is consumed by a particular service. This makes benchmarking services against the market an impossible task. By defining the cost of infrastructure through service classification and consumption modeling, a more accurate picture of the true cost of utilizing shared resources can be gained. This allows the business to make fair comparisons of internal services to market offerings and enables informed investment decisions.
Cost transparency through service classification will also allow the business to make informed decisions when buying or building new applications. Applications designed to handle redundancy will be eligible for the most cost-effective service class and can be delivered at roughly a sixth of the cost of applications that depend on the infrastructure to provide redundancy.
Finally, cost transparency incents service owners to think about service retirement. In a traditional data center, services may fall out of use but often there is no consideration on how to retire an unused service. The cost of ongoing support and maintenance for an under-utilized service may be hidden in the cost model of the data center. In a private cloud, monthly consumption costs for each service can be provided to the business, incenting service owners to retire unused services and reduce their cost.
2.12 Consumption Based Pricing
This is the concept of paying for what you use as opposed to a fixed cost irrespective of the amount consumed. In a traditional pricing model, the consumer’s cost is based on flat costs derived from the capital cost of hardware and software and expenses to operate the service. In this model, services may be over or underpriced based on actual usage. In a consumption-based pricing model, the consumer’s cost reflects their usage more accurately.
The unit of consumption is defined in the service class and should reflect, as accurately as possible, the true cost of consuming infrastructure services, the amount of Reserve Capacity needed to ensure continuous availability, and the user behaviors that are being incented.
2.13 Security and Identity
Security for the cloud is founded on two paradigms: protected infrastructure and network access.
Protected infrastructure takes advantage of security and identity technologies to ensure that hosts, information, and applications are secured across all scenarios in the data center, including the physical (on-premises) and virtual (on-premises and cloud) environments.
Application access helps ensure that IT managers can extend vital applications to internal users as well as to important business partners and cloud users.
Network access uses an identity-centric approach to ensure that users—whether they’re based in the central office or in remote locations—have more secure access no matter what device they’re using. This helps ensure that productivity is maintained and that business gets done the way it should.
Most important from a security standpoint, the secure data center makes use of a common integrated technology to assist users in gaining simple access using a common identity. Management is integrated across physical, virtual, and cloud environments so that businesses can take advantage of all capabilities without the need for significant additional financial investments.
2.14 Multitenancy
Multitenancy refers to the ability of the infrastructure to be logically subdivided and provisioned to different organizations or organizational units. The traditional example is a hosting company that provides servers to multiple customer organizations. Increasingly, this is also a model being utilized by a centralized IT organization that provides services to multiple business units within a single organization, treating each as a customer or tenant.
3 Patterns
Patterns are specific, reusable ideas that have been proven solutions to commonly occurring problems. The following section describes a set of patterns useful for enabling the cloud computing concepts and principles. This section introduces these specific patterns. Further guidance on how to use these patterns as part of a design is described in subsequent documents.
3.1 Resource Pooling
The Resource Pool pattern divides resources into partitions for management purposes. Its boundaries are driven by Service Management, Capacity Management, or Systems Management tools.
Resource pools exist for either storage (Storage Resource Pool) or compute and network (Compute Resource Pool). This de-coupling of resources reflects that storage is consumed at one rate while compute and network are collectively consumed at another rate.
3.11 Service Management Partitions
The Service Architect may choose to differentiate service classifications based on security policies, performance characteristics, or consumer (that is a Dedicated Resource Pool). Each of these classifications could be a separate Resource Pool.

3.12 Systems Management Partitions
Systems Management tools depend on defined boundaries to function. For example, deployment, provisioning, and automated failure recovery (VM movement) depend on the tools knowing which servers are available to host VMs. Resource Pools define these boundaries and allow management tool activities to be automated.
3.13 Capacity Management Partitions
To perform Capacity Management it is necessary to know the total amount of resource available to a datacenter. A Resource Pool can represent the total data center compute, storage, and network resources that form an enterprise. Resource Pools allow this capacity to be partitioned; for example, to represent different budgetary requirements or to represent the power capacity of a particular UPS.
The Resource Pool below represents a pool of servers allocated to a datacenter.

3.2 Physical Fault Domain
It is important to understand how a fault impacts the Resource Pool, and therefore the resiliency of the VMs. A datacenter is resilient to small outages such as single server failure or local direct-attached storage (DAS) failure. Larger faults have a direct impact on the datacenter’s capacity so it becomes important to understand the impact of a non-server hardware component’s failure on the size of the available Resource Pool.
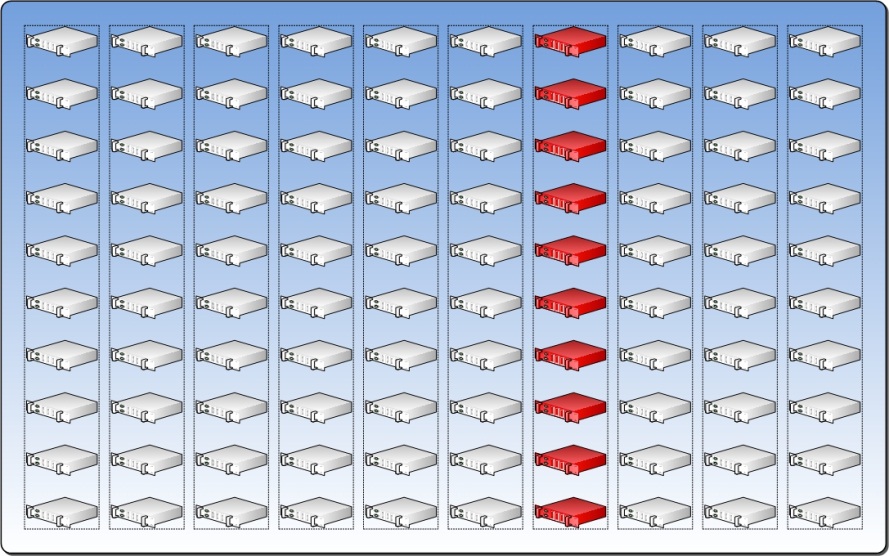
To understand the failure rate of the key hardware components, select the component that is most likely to fail and determine how many servers will be impacted by that failure. This defines the pattern of the Physical Fault Domain. The number of “most-likely-to-fail” components sets the number of Physical Fault Domains.
For example, the figure below represents 10 racks with 10 servers in each rack. Assume that the racks have two network switches and an uninterruptible power supply (UPS). Also assume that the component most likely to fail is the UPS. When that UPS fails, it will cause all 10 servers in the rack to fail. In this case, those 10 servers become the Physical Fault Domain. If we assume that there are 9 other racks configured identically, then there are a total of 10 Physical Fault Domains.
From a practical perspective, it may not be possible to determine the component with the highest fault rate. Therefore, the architect should suggest that the customer begin monitoring failure rates of key hardware components and use the bottom-of-rack UPS as the initial boundary for the Physical Fault Domain.
3.3 Upgrade Domain
The upgrade domain pattern applies to all three categories of datacenter resources; network, compute, and storage.
Although the VM creates an abstraction from the physical server, it doesn’t obviate the requirement of an occasional update or upgrade of the physical server. The Upgrade Domain pattern can be used to accommodate this without disrupting service delivery by dividing the Resource Pool into small groups called Upgrade Domains. All servers in an Upgrade Domain are maintained simultaneously, and each group is targeted in turn. This allows workloads to be migrated away from the Upgrade Domain during maintenance and migrated back after completion.
Ideally, an upgrade would follow the pseudo code algorithm below:
For each ResourceDomain in n;
Free from workloads;
Update hardware;
Reinstall OS;
Return to Resource Pool;Next;
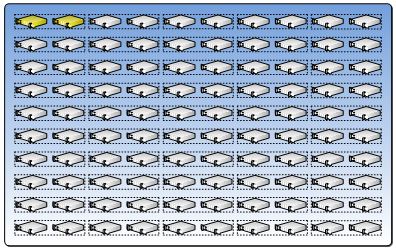
The same concept applies to network. Because the datacenter design is based on a redundant network infrastructure, an upgrade domain could be created for all primary switches (or a subset) and another upgrade domain for the secondary switches (or subset). The same applies for the storage network.
3.4 Reserve Capacity
The advantage of a homogenized Resource Pool-based approach is that all VMs will run the same way on any server in the pool. This means that during a fault, any VM can be relocated to any physical host as long as there is capacity available for that VM. Determining how much capacity needs to be reserved is an important part of designing a private cloud. The Reserve Capacity pattern combines the concept of resource decay with the Fault Domain and Upgrade Domain patterns to determine the amount of Reserve Capacity a Resource Pool should maintain.
To compute Reserve Capacity, assume the following:
TOTALSERVERS = the total number of servers in a Resource Pool
ServersInFD = the number of servers in a Fault Domain
ServersInUD = the number of servers in an Upgrade Domain
ServersInDecay = the maximum number of servers that can decay before maintenance
So, the formula is: Reserve Capacity = ServersInFD + ServersInUD + ServersInDecay / TOTALSERVERS
This formula makes a few assumptions:
- It assumes that only one Fault Domain will fail at a time. A customer may elect to base their Reserve Capacity on the assumption that more than one Fault Domain may fail simultaneously. However, this leaves more capacity unused.
- Second, if we agree to use only one Fault Domain, it assumes that failure of multiple Fault Domains will trigger the Disaster Recovery plan and not the Fault Management plan.
- It assumes a situation where a Fault Domain fails when some servers are at maximum decay and some other servers are down for upgrade.
- Finally, it is based on no oversubscription of capacity.
In the formula, the number of servers in the Fault Domain is a constant. The number of servers allowed to decay and the number of servers in an Upgrade Domain are variable and determined by the architect. The architect must balance the Reserve Capacity because too much Reserve Capacity will lead to poor utilization. If an Upgrade Domain is too large, the Reserve Capacity will be high; if it is too small, upgrades will take a longer time to cycle through the Resource Pool. Too small a decay percentage is unrealistic and may require frequent maintenance of the Resource Pool, while too large a decay percentage means that the Reserve Capacity will be high.
There is no “correct” answer to the question of Reserve Capacity. It is the architect’s job to determine what is most important to the customer and tailor the Reserve Capacity in accordance with the customer’s needs.
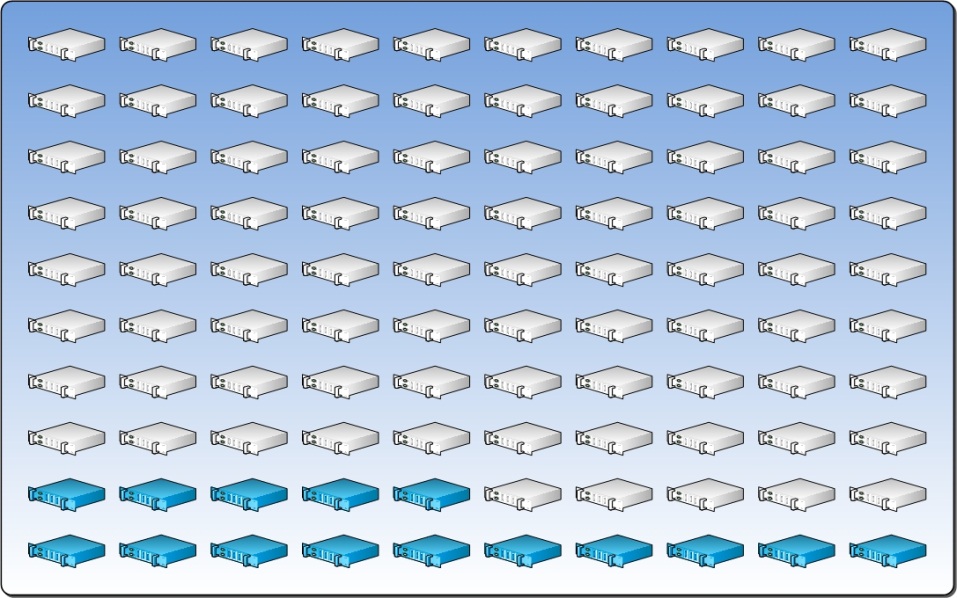
Calculating Reserve Capacity based on the example so far, our numbers would be:
TOTALSERVERS = 100
**ServersInFD = 10
ServersInUD = 2
ServersInDecay = 3
Reserve Capacity = 15%
**The figure below illustrates the allocation of 15 percent of the Resource Pool for Reserve Capacity.
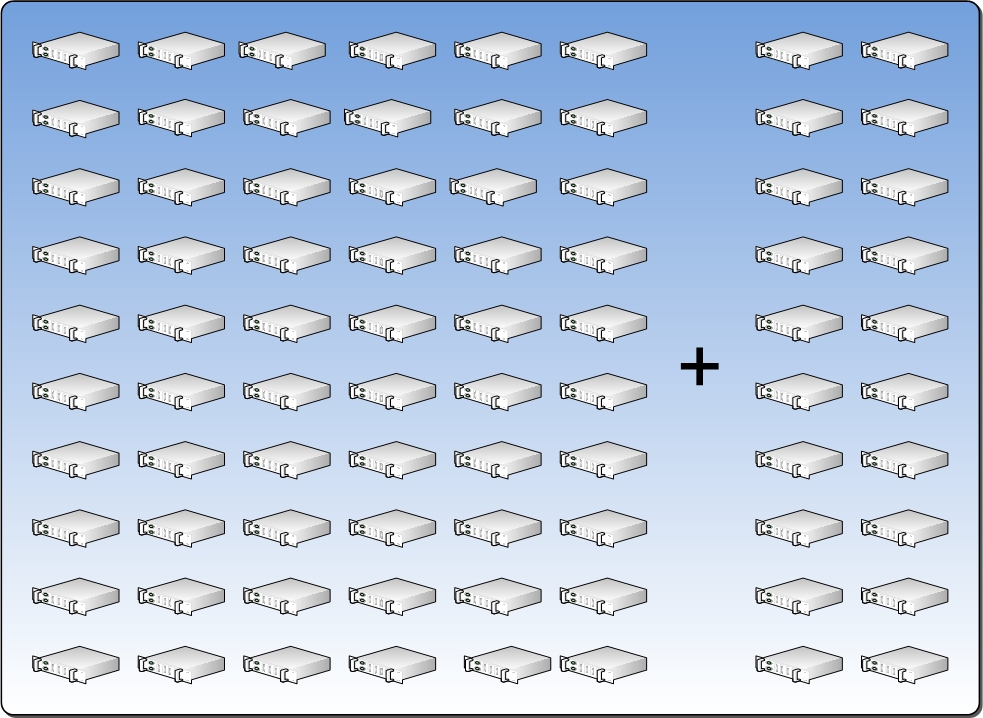
3.5 Scale Unit
At some point, the amount of capacity used will begin to get close to the total available capacity (where available capacity is equal to the total capacity minus the Reserve Capacity) and new capacity will need to be added to the datacenter. Ideally, the architect will want to increase the size of the Resource Pool to accommodate the capacity in standardized increments, with known environmental requirements (such as space, power, and cooling), known procurement lead time, and standardized engineering (like racking, cabling, and configuration). Further, this additional capacity needs to be a balance between accommodating the growth, while not leaving too much of the capacity unutilized. To do this, the architect will want to leverage the Scale Unit pattern.
The Scale Unit represents a standardized unit of capacity that is added to a datacenter. There are two types of Scale Unit; a Compute Scale Unit which includes servers and network, and a Storage Scale Unit which includes storage components. Scale Units increase capacity in a predictable, consistent way, allow standardized designs, and enable capacity modeling.
Much like Reserve Capacity, Scale Unit sizing will be left to the architect.
3.6 Capacity Plan
The Capacity Plan pattern utilizes the infrastructure patterns described above along with the business demand to ensure the perception of infinite capacity can be met. The capacity plan pattern cannot be built by IT alone but must be built and regularly reviewed and revised in conjunction with the business.
The capacity plan must account for peak capacity requirements of the business, such as holiday shopping season for an online retailer. It must account for typical as well as accelerated growth patterns of the business, such as business expansion, mergers and acquisitions, and development of new markets.
It must account for current available capacity and define triggers for when the procurement of additional Scale Units should be initiated. These triggers should be defined by the amount of capacity each Scale Unit provides and the lead time required for purchasing, obtaining, and installing a Scale Unit.
The requirements for a well-designed capacity plan cannot be achieved without a high degree of IT Service Management maturity and a close alignment between the business and IT.
3.7 Health Model
To ensure resiliency, a datacenter must be able to automatically detect if a hardware component is operating at a diminished capacity or has failed. This requires an understanding of all of the hardware components that work together to deliver a service, and the interrelationships between these components. The Health Model pattern is the understanding of these interrelationships that enables a MANAGEMENT LAYER to determine which VMs are impacted by a hardware component failure, facilitating the datacenter management system to determine if an automated response action is needed to prevent an outage, or to quickly restore a failed VM onto another system.
From a broader perspective, the management system needs to classify a failure as Resource Decay, a Physical Fault Domain failure, or a Broad Failure that requires the system to trigger the disaster recovery response.
When creating the Health Model, it is important to consider the connections between the systems including connections to power, network, and storage components. The architect also needs to consider data access while considering interconnections between the systems. For example, if a server cannot connect to the correct Logical Unit Number (LUN), the service may fail or work at a diminished capacity. Finally, the architect needs to understand how diminished performance might impact the system. For example, if the network is saturated (let’s say usage is greater than 80 Percent) there may be an impact on performance that will require the management system to move workloads to new hosts. It is important to understand how to proactively determine both the health and failed states in a predictable ladder.
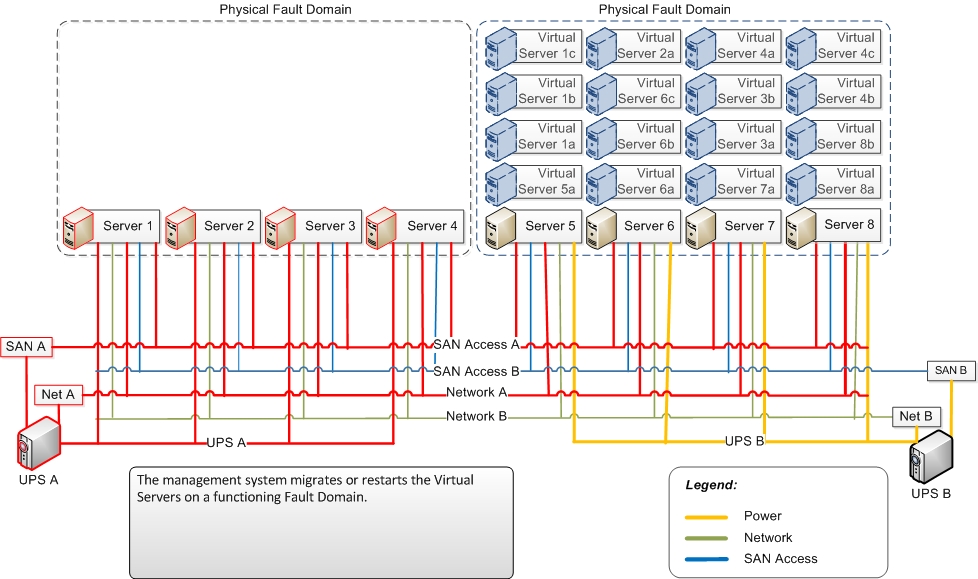
The diagrams below show typical systems interconnections and demonstrate how the health model pattern is used to provide resiliency. In this case, power is a single point of failure. Network connections and Fiber Channel connections to the Storage Area Network (SAN) are redundant.

When “UPS A” fails, it causes a loss of power to Servers 1-4. It also causes a loss of power to “Network A” and “Fiber Channel A”, but because network and Fiber Channel are redundant, only one Fault Domain fails. The other is diminished, as it loses its redundancy.

The management system detects the Fault Domain failure and migrates or restarts workloads on functioning Physical Fault Domains.
While the concept of a health model is not unique, its importance becomes even more critical in a datacenter. To achieve the necessary resiliency, failure states (an indication that a failure has occurred) and warn states (an indication that a failure may soon occur) need to be thoroughly understood for the cloud infrastructure. The Detect and Respond scenario for each state also needs to be understood, documented, and automated. Only then can the benefits of resiliency be fully realized.
This dynamic infrastructure, which can automatically move workloads around the fabric in response to health warning states, is only the first step towards dynamic IT. As applications are designed for greater resiliency, they too should have robust and high fidelity Health Models and they should provide the service monitoring toolset with the information needed to detect and respond to health warning states at the application layer as well.
3.8 Service Class
Service Class patterns are useful in describing how different applications interact with the cloud platform infrastructure. While each environment may present unique criteria for their service class definitions, in general there are three Service Class patterns that describe most application behaviors and dependencies.
The first Service Class pattern is designed for stateless applications. It is assumed that the application is responsible for providing redundancy and resiliency. For this pattern, redundancy at the infrastructure is reduced to an absolute minimum and thus, this is the least costly Service Class pattern.
The next Service Class pattern is designed for stateful applications. Some redundancy is still required at the Infrastructure Layer and resiliency is handled through Live Migration. The cost of providing this service class is higher because of the additional hardware required for redundancy.
The last and most expensive Service Class pattern is for those applications that are incompatible with a fabric approach to infrastructure. These are applications that cannot be hosted in a dynamic datacenter and must be provided using traditional data center designs.
3.9 Cost Model
Cost Model patterns are a reflection of the cost of providing services in the cloud and the desired consumer behavior the provider wishes to encourage. These patterns should account for the deployment, operations, and maintenance costs for delivering each service class, as well as the capacity plan requirements for peak usage and future growth. Cost model patterns must also define the units of consumption. The units of consumption will likely incorporate some measurement of the compute, storage, and network provided to each workload by Service Class. This can then be used as part of a consumption-based charge model. Organizations that do not use a charge back model to pay for IT services should still use units of consumption as part of notional charging. (Notional charging is where consumers are made aware of the cost of providing the services they consumed without actually billing them.)
The cost model will encourage desired behavior in two ways. First, by charging (or notionally charging) consumers based on the unit of consumption, they will likely only request the amount of resources they need. If they need to temporarily scale up their consumption, they will likely give back the extra resources when they are no longer needed. Secondly, by leveraging different cost models based on service class, the business is encouraged to build or buy applications that qualify for the most cost-effective service class wherever possible.
REFERENCES:
ACKNOWLEDGEMENTS LIST:
If you edit this page and would like acknowledgement of your participation in the v1 version of this document set, please include your name below:
[Enter your name here and include any contact information you would like to share]
Discuss the Private Cloud Principles, Patterns, and Concepts on the Private Cloud Architecture TechNet Forum