Basis of Neural Networks in C#
Scope
In this article, we'll see how to implement a neural network in C#, i.e. a model capable of processing input data and adjust its internal mechanics to learn how to produce a desired result. We'll see more on this later. The present article will focus on generic definitions about neural networks and their behaviours, offering a simple implementation for the reader to test. In the final paragraph, we will code a small network capable of swapping two variables.
This article is a re-release of Basis of Neural Networks in Visual Basic .NET, written in 2015 and implementing the neural network in Visual Basic .NET. In the present article, though, we'll see some improvements about the topic.
Introduction
A first definition
The term "neural network" is typically used as a reference to a network or circuit constituted by neurons. We can differentiate two types of neural networks: a) biological and b) artificial. Obviously, speaking about software development, we are here referring to artificial ones, but that kind of implementations get their basic model and inspiration from their natural counterparts, so it can be useful to briefly consider the functioning of what we intend when we speak of biological neural networks.
Natural neural networks
Those are networks constituted by biological neurons, and they are typical of living creatures. The neurons/cells are interconnected into the peripheral nervous system or in the central one. In neurosciences, groups of neurons are identified by the physiological function they perform.
Artificial neural networks
Artificial networks are mathematical models, which could be implemented through an electronic medium, which mime the functioning of a biological network. Simply speaking, we will have a set of artificial neurons apt to solve a particular problem in the field of artificial intelligence. Like a natural one, an artificial network could "learn", through time and trial, the nature of a problem, becoming more and more efficient in solving it.
Neurons
After this simple premise, it should be obvious that in a network, being it natural or artificial, the entity known as "neuron" has a paramount importance, because it receive inputs, and is somewhat responsible of a correct data processing, which end in a result. Think about our brain: it's a wonderful supercomputer composed by 86*10^9 neurons (more or less). An amazing number of entities which constantly exchange and store informations, running on 10^14 synapses. Like we've said, artificial models are trying to capture and reproduce the basic functioning of a neuron, which is based on three main parts:
- Soma, or cellular body
- Axon, the neuron output line
- Dendrite, the neuron input line, which receives the data from other axons through synapses
The soma executes a weighted sum of the input signals, checking if they exceed a certain limit. If they do, the neuron activates itself (resulting in a potential action), staying in a state of quiet otherwise. An artificial model tries to mimic those subparts, with the target of creating an array of interconnected entities capable of adjusting itself on the basis of received inputs, constantly checking the produced results against an expected situation.
How a network learns
Typically, the neural network theory identifies 3 main methods through which a network can learn (where, with "learn", we intend - from now on - the process through which a neural network modifies itself to being able to produce a certain result with a given input). Regarding the Visual Basic implementation, we will focus only on one of them, but it's useful to introduce all the paradigms, in order to have a better overview. For a NN (neural network) to learn, it must be "trained". The training can be supervisioned, if we possess a set of data constituted by input and output values. Through them, a network could learn to infer the relation which binds a neuron with another one. Another method is the unsupervisioned one, which is based on training algorithms which modifies the network's weights relying only on input data, resulting in networks that will learn to group received informations with probabilistic methods. The last method is the reinforced learning, which doesn't rely on presented data, but on exploration algorithms which produce inputs that will be tested through an agent, which will check their impact on the network, trying to determine the NN performance on a given problem. In this article, when we'll come to code, we will see the first presented case, or the supervisioned training.
Supervisioned training
So, let's consider the method from a closer perspective. What it means to training a NN with supervision? As we've said, it deals primarily of presenting a set of input and output data. Let's suppose we want to teach our network to sum two numbers. In that case, following the supervisioned training paradigm, we must feed our network with input data (lets say [1;5]) but also telling it what we expect as a result (in our case, [6]). Then, a particular algorithms must be applied in order to evaluate the current status of the network, adjusting it by processing our input and output data. The algorithm we will use in our example is called backpropagation.
Backpropagation
The backpropagation of errors is a technique in which we first initialize our network (typically with random values regarding the weights on single neurons), proceeding in forwarding our input data, matching results with output data we expect. Then we calculate the deviation of the obtained values from the desired one, obtaining a delta factor which must be backpropagated to our neurons, to adjust their initial state according to the entity of error we've calculated. Through trials and repetitions, several sets of input and output data are presented to the network, each time repeating the match between the real and the ideal value. In a certain time, that kind of operation will produce increasingly precise outputs, calibrating the weight of each network's components, and ultimately refining its ability to process the received data. For an extensive explanation about backpropagation, please refer to the Bibliography section.
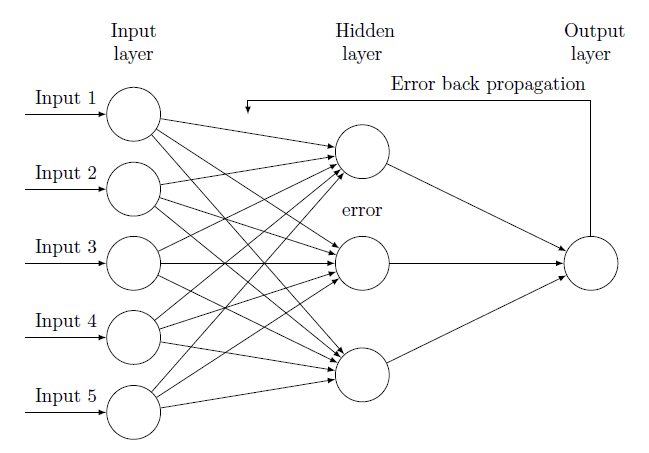
Creating a neural network
Now that we saw some preliminary concepts about neural networks, we should be able to develop a model which responds to the discussed paradigms. Without exceeding in mathematical over-explanations (which aren't really needed, unless you want to understand better what we will see), we will proceed step by step in coding a simple yet functional neural network, that we'll test when completed. The first thing we need to consider is the structure of a neural network: we know it's organized in neurons, and the neurons themselves are interconnected. But we don't know how.
Layers
And that's where the layers comes into scene. A layer is a group of neurons which share a more or less common function. For example, think about the entry point of input data. That will be the input layer, in which resides a group of neurons which share a common functionality, in that case limited to receiving and forward informations. Then we'll surely have an output layer, which will group those neurons that receive the result of previous processing. Among those layers could reside many layers, typically called "hidden", because an user won't have direct access to them. The number of those hidden layers, and the number of neurons each of them will contain, depends heavily on the natura and complexity of the problem we want to solve. To sum up, each network will be constituted of layers, each of which will contain a certain predetermined number of neurons
Neurons and dendrites
"Artificially" speaking, we could conceive a neuron like an entity which exposes a certain value, adjusted by trial iterations and bound to other neurons through dendrites, which in our case will be represented by sub-entities possessing an initial random weight. The training process will consist in feeding the input layer neurons, which transmit their value through dendrites to an upper layer, which will do the same thing until the output layer is reached. Finally, we calculate a delta between the current output and the desired one, recurring through the network and adjusting the dendrites weights, the neuron values and each deviation value, to correct the network itself. Then we start again with another training round.
Preparing network classes
Having seen how a network is structured, we could sketch down some classes to manage the various entities of a network. In the following snippet, we will outline Dendrite, Neuron and Layer classes, which we will use together in the implementation of a NeuralNetwork class.
CryptoRandom class
Since neural networks make extensive use of random values (at least for their initialization), we need a good function from which a truly random number can be retrieved. The Random namespace could not accomplish that, since it can only give pseudo-random values, and if called on very little timeframes, results tends to be similar. A better solution will be the one which use a random number generator from cryptography services, to ensure real randomness. We could achieve that by this simple class, which will be used for the proper classes of neural network itself
public class CryptoRandom
{
public double RandomValue { get; set; }
public CryptoRandom()
{
using (RNGCryptoServiceProvider p = new RNGCryptoServiceProvider())
{
Random r = new Random(p.GetHashCode());
this.RandomValue = r.NextDouble();
}
}
}
Dendrite class
public class Dendrite
{
public double Weight { get; set; }
public Dendrite()
{
CryptoRandom n = new CryptoRandom();
this.Weight = n.RandomValue;
}
}
As you can see, the Dendrite class is constituted by a sole property, named Weight. In initializing a Dendrite, a random Weight is attributed to our dendrite. The type of the Weight property is Double, because our input values will be between zero and one, so we need a strong precision when it comes to decimal places. More on this later. No other properties nor functions are required for that class.
Neuron class
public class Neuron
{
public List<Dendrite> Dendrites { get; set; }
public double Bias { get; set; }
public double Delta { get; set; }
public double Value { get; set; }
public int DendriteCount
{
get
{
return Dendrites.Count;
}
}
public Neuron()
{
Random n = new Random(Environment.TickCount);
this .Bias = n.NextDouble();
this .Dendrites = new List<Dendrite>();
}
}
Next, the Neuron class. As one can imagine, it will expose a Value property (of type Double, for the same motivations saw above), and a series of potential Dendrites, the number of which will depend to the neuron number of the layer our current neuron will be connected to. So we have a Dendrite property, a DendriteCount (which returns the number of Dendrites), and two property which will serve in the process of recalibration, namely Bias and Delta.
Layer class
public class Layer
{
public List<Neuron> Neurons { get; set; }
public int NeuronCount
{
get
{
return Neurons.Count;
}
}
public Layer(int numNeurons)
{
Neurons = new List<Neuron>(numNeurons);
}
}
Finally, a Layer class, which is simply a container for an array of neurons. In calling upon the New method, the user must indicate how many neurons the layer is required to have. We'll see in the next section how those classes can interact in the contest of a full-fledged neural network.
NeuralNetwork class
Our NeuralNetwork can be seen as a list of layers (each of which will inherit the underlying layer properties, i.e. neurons and dendrites). A neural network must be launched (or put in running state) and trained, so we will likely have two methods which can be used for that means. The network initialization must specify, among other properties, a parameter that we will call "learning rate". That will be a variable we'll use in weights recalculation. As the name implies, the learning rate is a factor which determines how fast a network will learn. Since it's a corrective factor, the learning rate must be chosen accurately: if its value is too large, but there is a large multitude of possible inputs, a network may not learn too well, or at all. Generally speaking, a good practice is to set the learning rate to a relatively small value, increasing it if the effective recalibration of our network becomes too slow.
Lets see an almost complete NeuralNetwork class:
public class NeuralNetwork
{
public List<Layer> Layers { get; set; }
public double LearningRate { get; set; }
public int LayerCount
{
get
{
return Layers.Count;
}
}
public NeuralNetwork(double learningRate, int[] layers)
{
if (layers.Length < 2) return;
this .LearningRate = learningRate;
this .Layers = new List<Layer>();
for ( int l = 0; l < layers.Length; l++)
{
Layer layer = new Layer(layers[l]);
this .Layers.Add(layer);
for (int n = 0; n < layers[l]; n++)
layer.Neurons.Add( new Neuron());
layer.Neurons.ForEach((nn) =>
{
if (l == 0)
nn.Bias = 0;
else
for (int d = 0; d < layers[l - 1]; d++)
nn.Dendrites.Add( new Dendrite());
});
}
}
private double Sigmoid(double x)
{
return 1 / (1 + Math.Exp(-x));
}
public double[] Run(List<double> input)
{
if (input.Count != this.Layers[0].NeuronCount) return null;
for (int l = 0; l < Layers.Count; l++)
{
Layer layer = Layers[l];
for (int n = 0; n < layer.Neurons.Count; n++)
{
Neuron neuron = layer.Neurons[n];
if (l == 0)
neuron.Value = input[n];
else
{
neuron.Value = 0;
for (int np = 0; np < this.Layers[l - 1].Neurons.Count; np++)
neuron.Value = neuron.Value + this .Layers[l - 1].Neurons[np].Value * neuron.Dendrites[np].Weight;
neuron.Value = Sigmoid(neuron.Value + neuron.Bias);
}
}
}
Layer last = this .Layers[ this .Layers.Count - 1];
int numOutput = last.Neurons.Count ;
double [] output = new double[numOutput];
for (int i = 0; i < last.Neurons.Count; i++)
output[i] = last.Neurons[i].Value;
return output;
}
public bool Train(List<double> input, List<double> output)
{
if ((input.Count != this.Layers[0].Neurons.Count) || (output.Count != this.Layers[this.Layers.Count - 1].Neurons.Count)) return false;
Run(input);
for ( int i = 0; i < this.Layers[this.Layers.Count - 1].Neurons.Count; i++)
{
Neuron neuron = this .Layers[ this .Layers.Count - 1].Neurons[i];
neuron.Delta = neuron.Value * (1 - neuron.Value) * (output[i] - neuron.Value);
for ( int j = this.Layers.Count - 2; j > 2; j--)
{
for ( int k = 0; k < this.Layers[j].Neurons.Count; k++)
{
Neuron n = this .Layers[j].Neurons[k];
n.Delta = n.Value *
(1 - n.Value) *
this .Layers[j + 1].Neurons[i].Dendrites[k].Weight *
this .Layers[j + 1].Neurons[i].Delta;
}
}
}
for ( int i = this.Layers.Count - 1; i > 1; i--)
{
for ( int j=0; j < this.Layers[i].Neurons.Count; j++)
{
Neuron n = this .Layers[i].Neurons[j];
n.Bias = n.Bias + ( this .LearningRate * n.Delta);
for (int k = 0; k < n.Dendrites.Count; k++)
n.Dendrites[k].Weight = n.Dendrites[k].Weight + ( this .LearningRate * this .Layers[i - 1].Neurons[k].Value * n.Delta);
}
}
return true;
}
NeuralNetwork Constructor
When our network is initialized, it requires a learning rate parameter, and a list of Layers. Processing that list, you can see how each layer will result in a generation of neurons and dendrites, which are assigned to their respective parents. Calling the New() method of neurons and dendrites, will result in a random assignation of their initial values and weights. If the passed layers are less than two, the subroutine will exit, because a neural network must have at least two layers, input and output.
public NeuralNetwork(double learningRate, int[] layers)
{
if (layers.Length < 2) return;
this .LearningRate = learningRate;
this .Layers = new List<Layer>();
for ( int l = 0; l < layers.Length; l++)
{
Layer layer = new Layer(layers[l]);
this .Layers.Add(layer);
for (int n = 0; n < layers[l]; n++)
layer.Neurons.Add( new Neuron());
layer.Neurons.ForEach((nn) =>
{
if (l == 0)
nn.Bias = 0;
else
for (int d = 0; d < layers[l - 1]; d++)
nn.Dendrites.Add( new Dendrite());
});
}
}
Run() Function
As we've said, our network must possess a function through which we process input data, making them move into our network, and gathering the final results. The following function does this. First, we'll check for input correctness: if the number of inputs are different from the input layer neurons, the function cannot be executed. Each neuron must be initialized. For te first layer, the input one, we simply assign to the neuron Value property our input. For other layers, we calculate a weighted sum, given by the current neuron Value, plus the Value of the previous layer neuron multiplied by the weight of the dendrite. Finally, we execute on the calculated Value a Sigmoid function, which we'll analyze below. Processing all layers, our output layer neurons will receive a result, which is the parameter our function will return, in the form of a List(Of Double).
public double[] Run(List<double> input)
{
if (input.Count != this.Layers[0].NeuronCount) return null;
for (int l = 0; l < Layers.Count; l++)
{
Layer layer = Layers[l];
for (int n = 0; n < layer.Neurons.Count; n++)
{
Neuron neuron = layer.Neurons[n];
if (l == 0)
neuron.Value = input[n];
else
{
neuron.Value = 0;
for (int np = 0; np < this.Layers[l - 1].Neurons.Count; np++)
neuron.Value = neuron.Value + this .Layers[l - 1].Neurons[np].Value * neuron.Dendrites[np].Weight;
neuron.Value = Sigmoid(neuron.Value + neuron.Bias);
}
}
}
Layer last = this .Layers[ this .Layers.Count - 1];
int numOutput = last.Neurons.Count ;
double [] output = new double[numOutput];
for (int i = 0; i < last.Neurons.Count; i++)
output[i] = last.Neurons[i].Value;
return output;
}
Sigmoid() Function
The sigmoid is a mathematical function known for its typical "S" shape. It is defined for each real input value. We use such a function in neural network programming, because its differentiability - which is a requisite for backpropagation - and because it introduces non-linearity into our network (or, it makes out network able to learn the correlations among inputs that don't produce linear combinations). Plus, for each real value, the sigmoid function return a value between zero and one (excluding upper limit). That function has peculiarities which make it really apt when it comes to backpropagation.
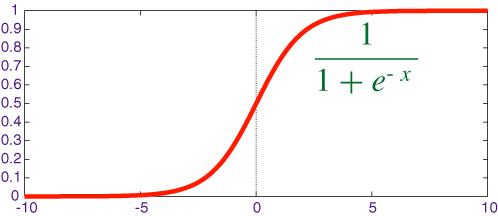
private double Sigmoid(double x)
{
return 1 / (1 + Math.Exp(-x));
}
Train() Function
A network is initialized with random values, so - without recalibration - the results they return are pretty random themselves, more or less. Without a training procedure, a freshly started network can be almost useless. We define, with the word training, the process through which a neural network keeps running on a given set of inputs, and its results are constantly matched against expected output sets. Spotting differences on our outputs from the returned values of the net, we then proceed in recalibrating each weight and value on the net itself, stepping forward a closer resemblance of what we want and what we get from the network.
In VB code, something like this:
public bool Train(List<double> input, List<double> output)
{
if ((input.Count != this.Layers[0].Neurons.Count) || (output.Count != this.Layers[this.Layers.Count - 1].Neurons.Count)) return false;
Run(input);
for ( int i = 0; i < this.Layers[this.Layers.Count - 1].Neurons.Count; i++)
{
Neuron neuron = this .Layers[ this .Layers.Count - 1].Neurons[i];
neuron.Delta = neuron.Value * (1 - neuron.Value) * (output[i] - neuron.Value);
for ( int j = this.Layers.Count - 2; j > 2; j--)
{
for ( int k = 0; k < this.Layers[j].Neurons.Count; k++)
{
Neuron n = this .Layers[j].Neurons[k];
n.Delta = n.Value *
(1 - n.Value) *
this .Layers[j + 1].Neurons[i].Dendrites[k].Weight *
this .Layers[j + 1].Neurons[i].Delta;
}
}
}
for ( int i = this.Layers.Count - 1; i > 1; i--)
{
for ( int j=0; j < this.Layers[i].Neurons.Count; j++)
{
Neuron n = this .Layers[i].Neurons[j];
n.Bias = n.Bias + ( this .LearningRate * n.Delta);
for (int k = 0; k < n.Dendrites.Count; k++)
n.Dendrites[k].Weight = n.Dendrites[k].Weight + ( this .LearningRate * this .Layers[i - 1].Neurons[k].Value * n.Delta);
}
}
return true;
}
As usual, we check for correctness of inputs, then start our network by calling upon the Execute() method. Then, starting from the last layer, we process every neuron and dendrite, correcting each value by applying the difference of outputs. The same thing will be done on dendrites weights, introducing the learning rate of the network, as saw above. At the end of a training round (or, more realistically, on the completion of several hundreds of rounds), we'll start to observe that the outputs coming from the network will become more and more precise.
NetworkHelper class
The sample code provided in the article contains a static class named NetworkHelper: it does not represent a vital part of the package, simply implementing two methods to get a graphical representation of the network itself.
- ToTreeView(TreeView t, NeuralNetwork nn)
- ToPictureBox(PictureBox p, NeuralNetwork nn, int X, int Y)
Those two methods can be used to create a representation of the neural network on a given TreeView control, passing to the ToTreeView function the apt parameters, or to draw the network schema on a PictureBox, painting a circle for each neuron on different layers. Each neuron will contain its value, rounded (only graphically) to the second decimal place.
A test application
In the present section we will see a simple test application, which we'll use to create a pretty trivial network, used to swap two variables. In the following, we will consider a network with three layers: an input layer constituted by two neurons, an hidden layer with four neurons, and an output layer with two neurons. What we expect from our network, giving enough supervisioned training, will be the ability to swap the values we present it or, in other words, to being able to shift the value of the input neuron #1 on the output neuron #2, and vice versa.
In the downloadable NeuralNetwork class, you'll find a couple of methods which we haven't analyzed in the article, which refers to the graphical and textual network rendering. We will use them in our example, and you can consult them by downloading the source code.
Initializing the network
Using our classes, a neural network can be simply initialized by declaring it, and feeding it its learning rate and start layers. For example, in the test application you can see a snippet like this:
NeuralNetwork nn = new NeuralNetwork(21.5, new int[] { 2, 4, 2 });
We've defined the network as globally to a Form, then - in the Load() event - we've created the layers i need, passing them to the network initialization. That will result in having our layers correctly populated with the number of neurons specified, each element starting with random values, deltas, biases and weights.
Running a network
Running and training a network are very simple procedures as well. All they require is to call upon the proper method, passing a set of input and/or output parameters. In case of the Execute() method, for example, we could write:
List< double > ins = new List<double>();
ins.Add(txtIn01.Text);
ins.Add(txtIn02.Text);
double [] ots = nn.Run(ins);
txtOt01.Text = ots[0].ToString();
txtOt02.Text = ots[1].ToString();
Where txtIn01, txtIn02, txtOt01, txtOt02 are Form's TextBoxes. What we will do with the above code, is simply to get inputs from two TextBoxes, using them as inputs for the network, and writing on another couple of TextBoxes the returned values. The same procedure applies in case of training.
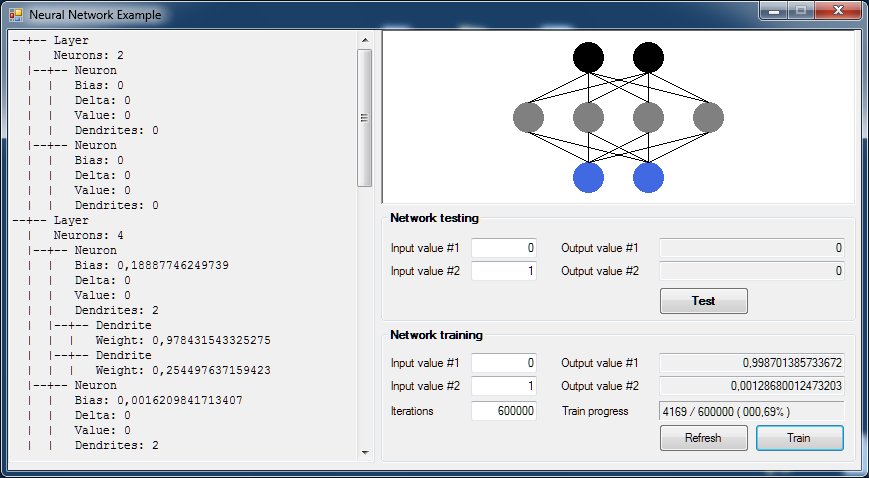
Swapping two variables (Sample in VB.NET)
In the following video, you could see a sample training session. The running program is the same you'll find by downloading the source code at the end of the article. As you can see, by starting with random values, the network will learn to swap the signals it receives. The values of 0 and 1 must not be intended as precise numbers, but rather as "signals of a given intensity". By observing the results of training, you could note how the intensity of the values will increase toward 1, or decrease to zero, never really reaching the extremes, but representing them anyway. So, at the end of an "intense" training to teach our network that, in case of an input couple of [0,1] we desire an output of [1,0], we can observe that we receive something similar to [0.9999998,0.000000015], where the starting signals are represented, by their intensity, to the closer conducive value, just like a neuron behave himself, speaking about activation energy levels.
Source code
The source code we've discussed so far can be download at the following link:
- https://code.msdn.microsoft.com/Basis-of-Neural-Networks-f12ce1e9 [C# code]
- https://code.msdn.microsoft.com/Basis-of-Neural-Networks-a379549c [VB.NET code]
Bibliography
Other Programming Languages
The present article is available (with the due changes) in the following programming languages: