BizTalk: Simplify BizTalk Dev by Using the Empty Namespace
I won’t be shy, XML namespaces are fine concept, but a frustrating implementation. I can say without the slight bit of doubt, the XML Namespace implementation has caused many, many more problems for me than it solved, which is exactly 0. This is because after doing this for 17 years, I have never, ever experienced a name collision, which is the only reason Namespaces exist. As of today, other formats have grown in legitimate popularity that offer much more direct approach to formatting data, namely JSON, that don’t support the concept of namespaces at all**.
Even though XML will be the foundation of BizTalk Dev for, well, forever and there’s nothing wrong with that, we can adopt the huge benefit of the JSON scheme while giving up absolutely no functionality. The best part, XML itself provides a completely legitimate way to avoid all of the complication that namespaces bring by just using the Empty Namespace (or no namespace, depending on where you look).
**Yes, I am aware that a namespace is implicitly part of JSON since it follows Java rules, but we can do the same thing in Xml. “Contoso.PlantName” : “Bellvue” and <Fabrikan.PlantName>Tacoma</Fabrikan.PlantName> are conceptually the same.
The sample Solution for this Article can be found in the MSDN Code Gallery at: https://code.msdn.microsoft.com/BizTalk-Simplify-BizTalk-90f4e1cf
Benefits of Using the Empty Namespace
Before we get started, I want to lay out some key benefits and important points.
- The Empty Namespace is part of XML. There is no hack or trick involved. An Empty Namespace is just as valid as any Namespace Uri.
- The Empty Namespace is fully supported in .NET and BizTalk Sever because of point #1.
- The Empty Namespace means much simpler and readable XPath and Xslt. See the original MSDN XPath Examples: XPath Examples
- The Empty Namespace means much smaller and readable XML documents.
- Points #3 and #4 will save you a lot of frustration and dev time.
Creating Schemas
Creating a Schema with the Empty Namespace is very easy. There are just two extra steps:
- Remove any value in the TargetNamespace property leaving it blank.
- Set Element FormDefault to Qualified to Qualified.

Step 2 is very important. I often find developers are still confused by this definition, believing that Qualified vs Unqualified refers to the use of a namespace prefix, such as ns0. This is not the case. It means that all Elements in the Schema, at any level, are qualified with the Target Namespace, whatever it is. What trips people up is that the the Target Namespace will always apply to elements defined at the Root, but not elements defined lower in the hierarchy unless Element FormDefault is Qualified.
A-ha, if you’re the inquisitive type, you will notice that when using an empty Target Namespace, the value of Element FormDefault has no effect, and you would be correct. I still recommend setting it to Qualified so that all elements are unambiguously defined in the Empty Namespace, as opposed to the ‘default’ Empty Namespace. Splitting hairs, yes, but you should be using Qualified even when using a namespace so this is also an issue of consistency.
Modifying External Schemas
If full Canonical Schemas don’t make sense for a particular app, we can still benefit from using the Empty Namespace by modifying the external schema for use within our app.
Simple Schemas
The EDI Schemas are a great candidate for this. You will still need versions of the EDI Schemas for the edge, meaning for use by the EDI Disassembler and Assembler, but within your app, Maps, Orchestrations, Rules, etc., all use Schemas with the Empty Namespace.
Modifying the EDI schemas for this purpose is very easy.
- Copy the EDI Schema in your Solution.
- Set Target Namespace to blank.
- Set Element FormDefault to Qualified.
- Remove the EDI Schema Editor Extension.
Now, you have a much simplified Schema to use within the app.
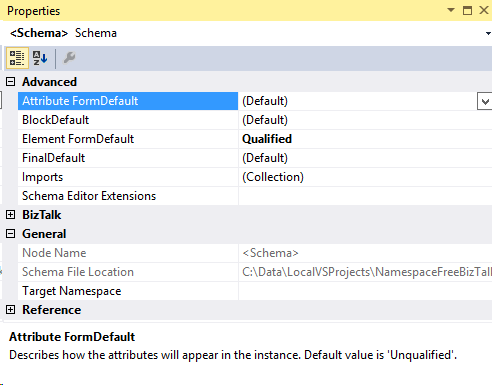
In these Properties, note the Schema Editor Extensions field is blank.
To see how this XML looks, right-click the Schema in Solution Explorer and choose Generate Instance. The structure is fully preserved but there is no namespace noise.
Complex Schemas
The EDI Schemas are easy to make namespace free since they are all self contained with no external references. This is not always the case and there are many interface schemas that use a complicated import/include scheme when defining types and structures (I’m looking at you CRM! ).
Using the CRM Schema as an example, we can’t simple remove the namespaces since that will break all the references. But, this is not a showstopper, we just have to take a quick round trip through a Generated Instance and the Schema Generator Wizard.
1. Set Root Reference to the operation you want a Schema for.

2. Right-click and choose Generate Instance.
3. Open the generated instance in the Visual Studio XML Editor.
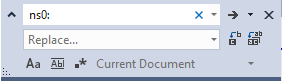
4. Replace “ns0:”, “ns1:” and “ns2:” all with nothing. You don’t need to do anything about the xmlns declarations since the Schema Generator will ignore them.
5. Use the Well-formed XML Schema Wizard to generate a Schema from the modified instance.
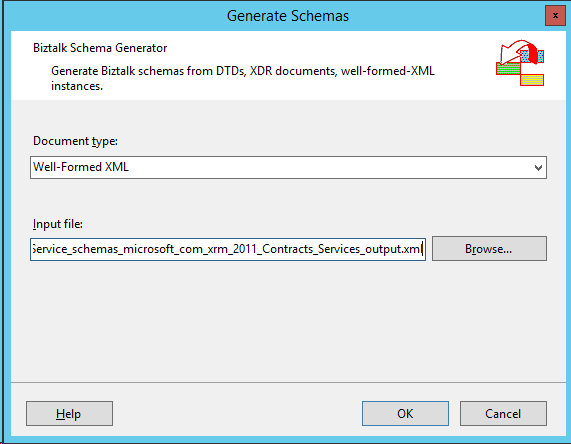
The wizard will generate a single .xsd representing the Create operation for CRM. Verify the Element FormDefault is set to Qualified and the TargetNamespace option is empty.
You now have a very much simplified Schema to use within your app.
**Note, having done this several times, it’s worth pointing out that while the Schema Wizard usually does a really great job, it’s not always perfect. So, during development, I recommend you run the either the XmlAssembler with Validation on or use the XmlValidator component to catch any differences between the inferred Schema and the actual messages.
Removing Namespaces
Now that we have simple, easy to use Schemas using the Empty Namespace, we have to get our incoming message to conform. There are two ways to accomplish this, a Pipeline Component that strips namespaces and references or a Map. The choice depends on weather or not you are using an dedicated Canonical Schema or a Schema copy with the Empty Namespace.
Mapping To Namespace Free Messages
A Map is the best option if you meet these two criteria:
- You are using a dedicated Canonical Schema or have modified the incoming schema
-and- - Have a simple transform from the endpoint format to the Canonical or modified schema
In these two cases, using a Map allows you to remove the namespaces and modify the structure at the same time. Also, since a Map would be used to create the outgoing message, which likely would require namespaces, this keeps the two operations consistent. Creating the Map from the incoming to Canonical is the exact same Mapping process we would do in any app, including converting data, changing structure and anything else that needs to be done. The fact that the the destination Schema is namespace free is irrelevant.
Namespace Remover Pipeline Component
However, if one of these apply:
- Using a copy of the endpoint Schema just with no namespace
-or- - Have a complex transform from the endpoint to the Canonical
Then a Pipeline Component is the best option. The reason this applies for case 2 is that using the Empty Namespace significantly reduces mapping complexity, especially if custom Xslt is required. For this scenario, the pattern would be:
- Create an Empty Namespace Schema as described above.
- Use the RemoveNamespace Pipeline Component in the Decode Stage, then use the XmlDisassembler normally in the Disassemble Stage.
- Apply the Map either at the Receive Port or in an Orchestration.
The compiled Assembly is included with the sample Solution linked above.
Using XML in the Empty Namespace
Because the Empty Namespace is part of XML, all of BizTalk Server and .Net fully support the use of XML documents with an Empty Namespace. This applies to the Schema Designer, Map Designer, XML Disassembler and Assembler, the Flat File Disassembler and Assembler, Orchestration Designer and Engine (including the xpath() function), Xslt. Simply, there is no technical requirement for anything other then the Empty Namespace.
Here are some examples of why using the Empty Namespace is better:
XPath
CRM Value With Namespaces: /*[local-name()='Create' and namespace-uri()='http://schemas.microsoft.com/xrm/2011/Contracts/Services'%5D/*%5Blocal-name()='entity' and namespace-uri()='http://schemas.microsoft.com/xrm/2011/Contracts/Services'%5D/*%5Blocal-name()='Attributes' and namespace-uri()='http://schemas.microsoft.com/xrm/2011/Contracts'%5D/*%5Blocal-name()='KeyValuePairOfstringanyType' and namespace-uri()='http://schemas.microsoft.com/xrm/2011/Contracts'%5D/*%5Blocal-name()='value' and namespace-uri()='http://schemas.datacontract.org/2004/07/System.Collections.Generic']
CRM Value with the Empty Namespace: /Create/entity/Attributes/KeyValuePairOfstringanyType/value
CRM XPath with conditions: /Create/entity/Attributes/KeyValuePairOfstringanyType[key = ‘customerName’]/value
Of interesting note, on the MSDN page titled XPath Examples, every sample uses the Empty Namespace. See here: XPath Examples
Orchestration xpath()
The Orchestration xpath() function uses the Empty Namespace without issue. The sample Solution includes XPathSample.odx with the following code:
EmptyNamespaceFlatFileSent = EmptyNamespaceFlatFileReceived;
xpath(EmptyNamespaceFlatFileSent, "/EmptyNamespaceFlatFile/EmptyNamespaceFlatFile_Child1[2]/EmptyNamespaceFlatFile_Child1_Child2") = "SET IN ORCHESTRATION";
Xslt
Xslt get the same XPath benefits on the source document, shorter queries and readable condition. For the output document, we can also emit elements and attributes directly, avoiding xsl:element declarations.
With Namespaces:
<xsl:element name="MyOutputElementName" namespace="http://MyNamespace">
<xsl:text>MyOutputValue</xsl:text><br>
</xsl:element>
With the Empty Namespace:
<MyOutputElementName>
<xsl:text>MyOutputValue</xsl:text>
</MyOutputElementName>
XML Disassembler & Assembler
Because the Empty Namespace is completely valid XML, the XmlDisassembler and XmlAssembler work without issue.
Flat File Disassembler & Assembler
Similar to the XML components, the Flat File Assembler and Disassembler work with Empty Namespace Schemas without issue. There is one exception in the Flat File Experience. The Flat File Schema Wizard requires a Target Namespace be entered with running the Wizard. But, this Target Namespace can be immediately deleted from the generated Schema
JSON Decoder & Encoder
Oddly, there is a bug in the JSON Decoder component in that it requires a value for the RootNodeNamespace property, otherwise, a runtime error is thrown. This problem is compounded by the lack of a way to set the scope of the namespace. Fortunately, this is very easy to work around this by using the above referenced Empty Namespace Pipeline Component.
The JSON Encoder works with Empty Namespace message without issue.
Adding Namespaces to Outbound XML Messages
For the long foreseeable future, we will have to XML with namespace to apps that still require them. This is actually requires the least effort and should happen normally in most apps.
Adding any required namespaces to outbound documents should happen naturally and without any additional effort in the final map to the outbound format, meaning, it’s just another mapping operation. Because the source document uses the Empty Namespace, we still get most of the benefits and most of the problems are well hidden by the Mapper.
For cases, such as EDI, where we are using a copy of a schema with an Empty Namespace, the Mapping operation is just the opposite of the Map to remove the namespace.
A Note on Performance
In many cases, there is no extra effort to use the Empty Namespace in out app, especially if we can do this in an existing Mapping operation. Also, the Empty Namespace Pipeline Component uses a Stream implementation for minimal impact. So, in most cases, any ‘performance’ impact would be barely detectable.
Also worth considering is that XML Documents using only the Empty Namespace are much smaller, often by more than half. Moving around fewer bits is always better so the ‘cost’ of removing namespaces can be made up by saving the cost of handling them. This applies to memory, network and storage.
Finally, while a lot of unnecessary effort is put on runtime performance, I see too often where dev-time performance issues are ignored. Eliminating the burden of namespaces in our app development is well worth the expense of CPU time probably measured in minutes over a year. I compare that to the hours spent in XPath/Xslt/Schema dev cycles just to deal with namespace issues. That is hours plus hours we can use to make better apps in every other way.
Happy BizTalking!