SQL Server: Inside a DELETE operation in Heaps
Introduction
Scenario is related to a project which involved troubleshooting huge amount of heaps. Further questions resulted in the statement that all Clustered Indexes have been removed by request of the - former - chief of development. The reason for this redesign was heavy arising of deadlock situations. However - when they have re-engineered their database structure the deadlocks have gone but the team has not considered a few drawbacks which will inevitable occur when you work with heaps - and these drawbacks did not have to do with indexes!
Preamble
Some of us favor heaps as often as possible; particularly DWH scenarios are good candidates for heaps.
Two very interesting blog posts discuss the difference of Heaps and Clustered Indexes.
- Unreasonable defaults: Primary Key as Clustering Key (Markus Wienand)
- Clustered Index vs. Heap (Thomas Kejser)
Basically the usage of clustered indexes has many advantages over the heap (especially for maintenance reasons). But not always is it useful to follow the "best practice" recommendations. I recommend to my customers to think about the following issues before deciding for a heap or a clustered index:
- Analysis of the workloads
- Analysis of SELECT statements
- Analysis of required maintenance (fragmentation, forwarded records, DML operations)
When all conditions are perfect I would in most cases prefer a Heap before a Clustered Index. The following "story" is coming from a real customer which did only consider the second option. What the team didn't know was the deep impact of DELETE operations in the context of Heaps.
Environment for test
For all following examples a simple heap structure will be used. The size of a record is 8,004 bytes so only one record fit on a data page. The table will be filled with 20,000 records.
-- Create a HEAP for the demo
CREATE TABLE dbo.demo_table
(
Id INT NOT NULL IDENTITY (1, 1),
C1 CHAR(8000) NOT NULL DEFAULT ('Das ist nur ein Test')
);
GO
-- Now we fill the table with 20,000 records
SET NOCOUNT ON;
GO
INSERT INTO dbo.demo_table WITH (TABLOCK) (C1)
SELECT TOP (20000)
text
FROM sys.messages;
When the table is filled up we have a total of 20,001 data pages in the buffer pool of the Microsoft SQL Server.
-- what resource of the table dbo.demo_table are in the buffer pool now!
;WITH db_pages
AS
(
SELECT DDDPA.page_type,
DDDPA.allocated_page_file_id,
DDDPA.allocated_page_page_id,
DDDPA.page_level,
DDDPA.page_free_space_percent,
DDDPA.is_allocated
FROM sys.dm_db_database_page_allocations
(
DB_ID(),
OBJECT_ID(N'dbo.demo_table', N'U'),
NULL,
NULL,
'DETAILED'
) AS DDDPA
)
SELECT DOBD.file_id,
DOBD.page_id,
DOBD.page_level,
DOBD.page_type,
DOBD.row_count,
DOBD.free_space_in_bytes,
DP.page_free_space_percent,
DP.is_allocated
FROM sys.dm_os_buffer_descriptors AS DOBD
INNER JOIN db_pages AS DP ON
(
DOBD.file_id = DP.allocated_page_file_id
AND DOBD.page_id = DP.allocated_page_page_id
AND DOBD.page_level = DP.page_level
)
WHERE DOBD.database_id = DB_ID()
ORDER BY
DP.page_type DESC,
DP.page_level DESC,
DOBD.page_id,
DOBD.file_id;

Every data page of the heap is completely filled up. With the next statement 1,000 records will be deleted from the Heap. Due to the fact that only ONE record fits on a data page the page becomes empty.
-- Now we delete half of the records
SET ROWCOUNT 2000;
DELETE dbo.demo_table
WHERE Id % 2 = 0;
The analysis of the buffer pool and DMV sys.dm_db_database_page_allocation makes the problem visible when data will be deleted from a Heap and the data pages become free.

Against the expectation that empty data pages will be deallocated and given back to the database the situation is completely different. The picture above shows the allocated. The empty data pages are still allocated although they don't have any data stored - they consume 8192 bytes. With 1,000 deleted records this is a wasted amount of nearby 8 MB in the buffer pool. For a better understanding of this behavior the general processing with Heaps need to be investigated.
Reading data pages in a Heap
When a heap will be used, data can only be accessed by a Table Scan. A Table Scan means always accessing the complete table. When all data have been read the data will be filtered by the dedicated predicate.
SELECT * FROM dbo.demo_table WHERE Id = 10 OPTION (QUERYTRACEON 9130);
The above example generates the following execution plan. Please note that TF 9130 will be used to make the FILTER-Operator visible in the execution plan!

From its structure a Heap is by definition a bunch of data without any order criteria. For this reason a Heap works like a puzzle and to find data is the same as touching every single piece of the puzzle. Another important difference to any index structure is the fact that data pages don't have a relation to each other. A single data page does not know where the next or the previous one is.

A data page in a heap is isolated and controlled by the IAM page (Index Allocation Map) of the table. Think about the IAM as the container which holds all the data pages together. When Microsoft SQL Server access the page 110 it does not know what is the next one. For that reason, Microsoft SQL Server reads the IAM data page first to know what pages it has to read for a full table scan. Based on this information the process can start and every single data page can be read. This process is called "Allocation Scan" .
Deleting records from a Heap
By the fact that a Heap does not have any ordering key it seems to be clear that a DELETE operation requires a TABLE SCAN in the same way as the reading process.
![]()
The above picture shows two processes which want to access the heap. While transaction 1 (T1) is accessing the table for a DELETE operation the Transaction 2 (T2) wants to read the data for a different process.
Based on the concepts of Heaps both processes have to read the IAM page first. As soon as the IAM has been consumed both processes can start with their work. What would happen if T1 would deallocate page 36 when the records have been deleted and the page is empty? If T1 would deallocate the page the process with T2 would run into a failure. Because T2 has already read the IAM it expects to read the data page.
Due to this reason Microsoft SQL Server left all data pages from a heap as allocated, but empty data pages for the Heap structure. Independent of any other process which access the heap this behavior is the core behavior of Microsoft SQL Server.
Deallocation of empty data pages
There are four capabilities to deallocate empty data pages back to the database.
- Use a Clustered Index instead of a Heap
- Rebuild the Heap by using ALTER TABLE
- Deletion of records with an exclusive table lock
- Automatic lock escalation when huge amount of data will be deleted
While option 1 and 2 does not need any more explanation let's focus on the last two options:
Deleting records WITH (TABLOCK)
The simplest method to remove empty data pages from a heap is the exclusive locking of the table. But keep in mind that there is no lunch for free. Blocking the table exclusively mean a no scaling system. As long as the DELETE process locks the table no other process can access the table. The only exception is the "SNAPSHOT ISOLATION" but this technique is beyond the scope of this article.
The next example (with the newly created table) demonstrates the behavior.
-- Now we delete 2000 records
BEGIN TRANSACTION;
GO
DELETE dbo.demo_table WITH (TABLOCK)
WHERE Id <= 2000;
GO
COMMIT TRANSACTION;
GO
As soon as when the process has finished Microsoft SQL Server has released 2,000 pages back to the database.
-- what pages have been allocated by the table
SELECT DDIPS.index_id,
DDIPS.index_type_desc,
DDIPS.page_count,
DDIPS.record_count
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.demo_table', N'U'),
0,
NULL,
N'DETAILED'
) AS DDIPS

Microsoft SQL Server can release the data pages from the table without risk because its IAM is firmed with an exclusive lock.
![]()
Transaction 1 (T1) starts the DELETE process with an exclusive lock on the table. This exclusive lock includes the IAM pages, too. As long as the DELETE operation is processing it holds this exclusive lock on the table. While T1 is processing the task the transaction 2 (T2) has to wait. A SELECT statement cannot start because T2 need to read the IAM page and due to lock it cannot. The drawback of these kind of process implementation is the loss of scalability.
-- output of aquired / released locks
DBCC TRACEON (3604, 1200, -1);
GO
-- delete 1,000 records
SET ROWCOUNT 2000;
DELETE dbo.demo_table WITH (TABLOCK)
WHERE Id % 2 = 0;
GO
-- deactivate the output of locks
DBCC TRACEOFF (3604, 1200, -1);
The above code example demonstrates the locking behavior of the process. The following depiction shows the implemented locks.

The DELETE process requires first an X-lock on the table (OBJECT: 8:245575913). After the table has been locked exclusively the data pages and records can/will be locked, too for deallocation. Due to the exclusive lock on the table the IAM is "safe" and no other process can access the table.
Lock Escalation with huge amount of data
The above scenario did show that a controlled process can be initiated to delete and deallocate data pages from a Heap. A strange behavior might occur if you delete a huge amount of data from a table without exclusive locking to the table. Microsoft SQL Server is using "Lock escalation" to take memory pressure from the system when to many locks will flute the RAM.
"To escalate locks, the Database Engine attempts to change the intent lock on the table to the corresponding full lock. If the lock escalation attempt succeeds and the full table lock is acquired, then all heap or B-tree, page (PAGE), or row-level (RID) locks held by the transaction on the heap or index are released. If the full lock cannot be acquired, no lock escalation happens at that time and the Database Engine will continue to acquire row, key, or page locks(lower level locks). The Database Engine does not escalate row or key-range locks to page locks, but escalates them directly to table locks. Similarly, page locks are always escalated to table locks." [MS TechNet]
The rough threshold for lock escalation is ~5,000 locks, which of course depends on many other factors internally decided by database engine. If we want to delete >= 5,000 records from a Heap it could happen that Microsoft SQL Server will set an X-lock on the table. When the table is fully locked no other process can read the IAM page. So it is safe to delete and release the data pages in the table.
The following example demonstrates a lock escalation and its side effects to the release of data pages in the Heap. The given demo table is filled with 20,000 records and a DELETE command will delete half of them without any table hints!

To filter the log activities of the DELETE process only we use a named transaction. This technique makes it much easier to filter for dedicated log records.
-- Now we delete half of the records
BEGIN TRANSACTION demo;
GO
DELETE dbo.demo_table
WHERE Id % 2 = 0;
GO
COMMIT TRANSACTION demo;
GO
When the 10,000 records have been deleted we check again the allocated data pages and found the following results:

The counter of the allocated data pages is doing no sense. The expectation would be all 20,000 data pages or - because of lock escalation - only 10,000 data pages. While the DELETE process did happen the following locks have been recorded:
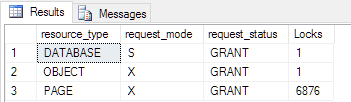
Let's do a little math: We started with 20,000 allocated records and 6,876 pages are exclusively locked. When we subtract the locked pages the result is exactly the value of the remaining data pages from the above picture. A look into the transaction log will give the answer WHY there is such a curious number of pages left!
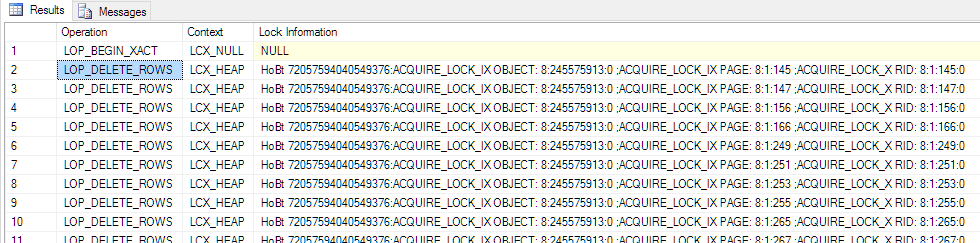
This picture shows the start of the DELETE process in the transaction log. You can clearly see the row based locking for every single DELETE command (AQUIRE_LOCK_X_RID). At the beginning Microsoft SQL Server didn't need a lock escalation and it deletes "row by row" with granular locks.
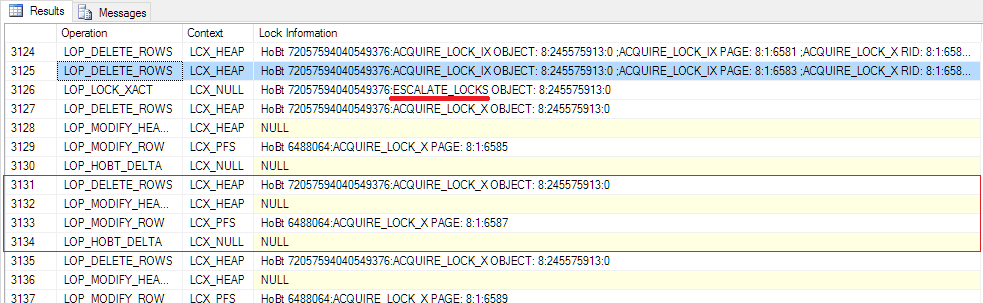
Beginning with line 3,126 in the transaction lock the situation completely changes. Up to this point Microsoft SQL Server has deleted 3124 records from the table WITHOUT deallocating the data pages. Microsoft SQL Server couldn't deallocate the pages because there was NO exclusive lock on the table!
Beginning with record 3,125 Microsoft SQL Server has too much locks open and escalates the locks (Line 3,126). When the table is locked Microsoft SQL Server changes the way it deletes records from the table:
- The record will be deleted from the data page (LOP_DELETE_RECORD)
- The header of the page will be updated (LOP_MODIFY_HEADER)
- The PFS Page need to be updated, too (LOP_MODIFY_ROW | LCK_PFS)
- Deleting the allocation in the IAM (LOP_HOBT_DELTA)
In total the first records will be deleted without release of pages because the table is not exclusively locked. When an internal threshold is reached and a lock escalation happens all ongoing DELETE statements will deallocate the data pages and release them back to the database.
Conclusion
Heaps have lots of advantages and disadvantages. Before you start with the implementation of Heaps in your database you have to consider that Heaps are "high-maintenance" than Clustered Indexes. A Heap handles DML-Operations completely different; so a Heap should be the choice when:
- The table is consuming data primarily with INSERT
- The table is autarchic and has no relation to any other table in the database
- The attributes of the table are using fixed length columns (avoid Forwarded Records)
If you have volatile data in your table and you need to delete data from a Heap you should better consider a Clustered Index. Data pages will not automatically be deallocated from a Heap and your database is growing. By using exclusive locks on the table you will lose the great benefit of granularity and concurrency for this object. This is a specialty you have to consider when you work with Heaps.