SSAS: Migrating from Oracle Essbase cubes
Introduction
Profitability Reporting System (PRS) and Devices Cost of Sales (DCOS) are two core finance reporting applications in XYZ. These applications are developed using Teradata, Oracle Essbase cube and Executive viewer. As part of 1DSC program, it was decided to migrate them to MS stack technologies.
This document discusses some of the issues faced while migrating these applications to MS technologies.
Background
These applications have historical cubes since 1996 developed using Oracle Hyperion Essbase cube as DM and Executive Viewer (EV) as the reporting tool. The requirement is to re-create the dimensional models in SSAS and use Excel for reporting to give similar user experience to end users. We started with most recent historical cube (FY15) as proof of concept to decide on design approaches and identify any issues/limitations with MS technologies. During the POC, we found few limitations with SSAS and Excel as well, which made us to think about re-designing of features mentioned below so that it fits in SSAS and work as expected. Also data extractions were bit tricky as the storage engine of Essbase is comparatively different than SSAS storage engine.
- Parallel hierarchies having shared members
- MDX formulas
- Unary operators especially for "~", which was causing issues while viewing data in Excel.
- Solve Order
- User Defined Attributes(UDA)
Since there were lots of effort required as migration to be done for more than 60 cubes with each cube having different data structure, we thought of evaluating internal/external tools to achieve quicker to meet the deadlines.
After analyzing various available internal/external tools, migration effort and costs, we decided to migrate (build the cubes) them to SSAS multi-dimensional cubes. Below are the few high level approaches evaluated,
- SSAS Tabular model
- SSAS Dimensional model
- 3rd party migration tools
- Relational DB having materialized/logical views
- MS internal tools.
- Acquiring Oracle license for ~25 users and continue using Oracle Hyperion Essbase
Since we decided to go with option (2), below are the few blocking issues encountered and mitigated for SSAS migration.
Problem Statement And Proposed Solution
a. Shared members/Parallel hierarchies
Essbase cube supports shared members, which is one member can have multiple parents. The data values associated with a shared member come from another member with the same name. The shared member stores a pointer to data contained in the other member, and the data is stored only once. Properties are also inherited from the base member but alias/description can be different. Shared members cannot have children but the base member can be from any level.
To handle this in SSAS, we need to either implement bridge table to have Many-to-many relationship or having extended/redundant dimensions where each dimensions contains only specific hierarchies. This effort is bit cumbersome and we had to take into considerations of dimensions, which requires bridge table looking at the processing performance.
NOTE: If SSAS can support this feature "Shared members", then directly we can import and generate hierarchies based on parent child record. Also we don't have to create those parallel hierarchies manually.
Below is one of the dimensions having shared members/parallel hierarchies where bridge table was implemented.
Sample data (DIM_Accounts_PC): -
PARENT |
CHILD |
ALIAS |
Unary Operator |
Stored vs Shared |
Accounts |
ACC700 |
Contribution2 |
+ |
S |
ACC700 |
ACC750 |
Contribution1 |
+ |
S |
ACC750 |
ACC510 |
Gross Profit |
+ |
S |
ACC700 |
ACC5308 |
Sales Exp. Allocations |
- |
S |
Accounts |
ACC0110 |
Net Cash Flow, Operative |
~ |
S |
ACC0110 |
ACC0020 |
Proceeds from Operations |
+ |
S |
ACC0020 |
ACC700 |
Contribution |
+ |
NULL |
ACC0020 |
ACC0030 |
Change in Networking Capital |
+ |
S |
ACC0030 |
ACC0031 |
Calculated Change in Networking Capital |
+ |
S |
Accounts |
IMRContribution |
COS Details Parallel hierarchy |
~ |
O |
IMRContribution |
ACC510 |
NULL |
~ |
NULL |
Accounts |
Sec_Read1 |
Profit and Loss Details Parallel |
~ |
O |
Sec_Read1 |
ACC510 |
NULL |
~ |
NULL |
Sec_Read1 |
ACC750 |
NULL |
~ |
NULL |
Sec_Read1 |
ACC5308 |
NULL |
~ |
NULL |
Sec_Read1 |
ACC700 |
NULL |
~ |
NULL |
- Data is in parent-child relation, but not in pre-defined levels, it's dynamic.
- Data storage property as `NULL' indicates the shared members.
- Facts are associated with leaf level member ACC5308 or ACC0031. You can see that ACC5308 has two parents with one as shared (ACC700 and Sec_Read1), but implementing parent-child hierarchy in SSAS requires one parent only (each child should roll up to only one parent). For discussion purpose let is take ACC5308, and you can see the (in below diagram) different path to traverse on the hierarchy.

SSAS does not support the shared members and can't process the cube as it will fail saying duplicate key error. When we set to ignore duplicates, it deletes the duplicate child members which are shared with multiple parents.
We have tried three different approaches to model shared members in SSAS:
- Model the dimension as many to many. This involves adding a bridge table along with generating a unique key for shared members. This method works only if based members are leaves. This approach is used currently in some of the dimensions. Since based members are actually level 1, solution was to recreate also all the children for the shared members. Generations keys columns have been altered by adding a distinct suffix.
- Using formulas as custom rollup property. This method involves generating a unique key for the shared member and a MDX formula that just takes the value of the based members. This approach is used in DCOS Plant dimension.
- We want to have something similar to this diagram for parent-child hierarchy to roll up correctly. In this we have each member with only one parent. This can be modelled in parent-child hierarchy.

As per the above diagram (ACC5308 child member), we need to ensure that each dimension record should have unique key so that we can create parallel hierarchy.
To achieve this,
We need to have all unique child/leaf member records stored in a single dimension (Dim_Accounts_Level0 created for the same).
A bridge table to be created to link between Level0 and Main dataset (DIM_ACCOUNTS_PC) having shared members (Parent child hierarchy)
Few sample scripts are provided for generating above data for unique dimension records and bridge tables.
-- Populate DIM_ACCOUNTS_PC(Data extracted from Essbase cube with parent child relations)
INSERT INTO MAIN.DBO.DIM_ACCOUNTS_PC
SELECT
PARENT
,CHILD
,COALESCE(ALIAS, CHILD) AS ALIAS
,CONSOLIDATION
,CASE
WHEN DATA_STORAGE IS NULL THEN PARENT + '|' + CHILD -- Shared members have a key consisting of PARENT>_<CHILD>
ELSE CHILD
END as HIERKEY
FROM STAGING.DBO.DIM_ACCOUNTS_PC
Level0 table is populated with all lowest level nodes, which is directly associated with the Fact.
-- Inserts into Level0 table all the distinct Level 0 members
INSERT INTO MAIN.DBO.DIM_ACCOUNTS_LEVEL0
SELECT
DISTINCT CHILD
FROM MAIN.DBO.DIM_ACCOUNTS_PC
WHERE CHILD NOT IN (SELECT DISTINCT PARENT FROM MAIN.DBO.DIM_ACCOUNTS_PC WHERE PARENT IS NOT NULL)
Bridge table is populated from Level0 and PC tables for all lowest level nodes from level0 table.
-- Insert into Bridge table
INSERT INTO MAIN.DBO.DIM_ACCOUNTS_BRIDGE
SELECT
PARENT
,CHILD
,HIERKEY
FROM MAIN.DBO.DIM_ACCOUNTS_PC
WHERE CHILD IN (SELECT ACCOUNTS FROM MAIN.DBO.DIM_ACCOUNTS_LEVEL0)
Fact Row(Accounts)?Level0(Accounts)?Bridge(HIERKEY)?PC(HIERKEY).
Final structure will look like the below diagram.

Many-to-Many relationship should look like below.
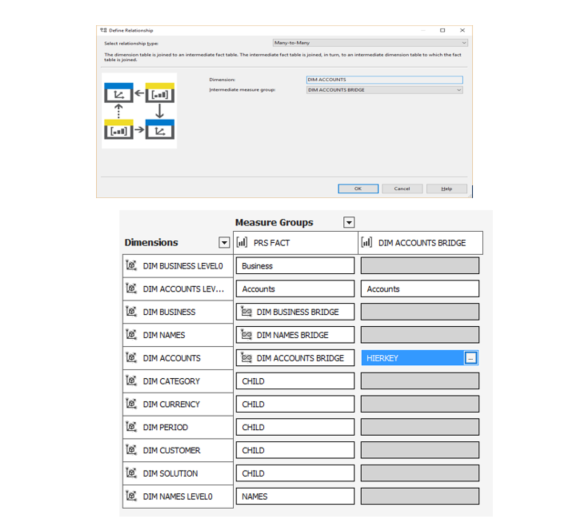
This approach appeared working well if shared members are Level0 (leaf) members, but if non-leaf members is shared, it was showing incorrect values.
Populate shared members through MDX formulas
In few dimensions (ex. DIM_BUSINESS_PC), there are non-Level0 Shared members. With the use of custom rollup property, it was possible to get the data from base member by pointing mdx formula, however the data didn't rollup to the parent member thus parent member shows incorrect values. Even using solve order didn't help (Calculation to be in sequence based on the node level). To solve this, we identified few approaches and given below
- ? Populated shared members with formula pointing to the base members. Updated the formula for base members which are used as shared members, formula should be pointing to the Main member. All the Ancestors to have a formula forcing the rollup of children.
NOTE:
Example:
--Update the formula for Non Leaf members which are used as shared members. The Formula should be just pointing to the Main member.
UPDATE PRSFY15.DIM_BUSINESS_PC
SET FORMULA = '[DIM Business].[Business Hierarchy].&[' + CHILD + ']'
WHERE HIERKEY IN (
SELECT DISTINCT A.PARENT + '|' + A.CHILD AS HIERKEY
FROM STAGING.PRSFY15.DIM_BUSINESS_PC A
WHERE A.DATA_STORAGE IS NULL
AND CHILD IN (
SELECT PARENT
FROM STAGING.PRSFY15.DIM_BUSINESS_PC
)
);
? Formula for the ancestors of Shared members pointing to non level0 members Example:
-- Set a formula for the ancestors of Shared members pointing to non level0 members
WITH #RESULT
AS (
SELECT *
FROM STAGING.PRSFY15.DIM_BUSINESS_PC
WHERE DATA_STORAGE IS NULL
AND CHILD IN (
SELECT CHILD
FROM STAGING.PRSFY15.DIM_BUSINESS_PC
WHERE DATA_STORAGE IS NULL
AND CHILD IN (
SELECT PARENT
FROM PRSFY15.DIM_BUSINESS_PC
)
)
UNION ALL
SELECT t.*
FROM STAGING.PRSFY15.DIM_BUSINESS_PC t
INNER JOIN #RESULT r ON r.PARENT = t.CHILD
)
UPDATE [PRSFY15].[DIM_BUSINESS_PC]
SET FORMULA = 'RollupChildren( [DIM BUSINESS].[Business Hierarchy].CurrentMember, [DIM BUSINESS].[Business hierarchy].CurrentMember.Properties(''Consolidation'') )'
WHERE CHILD IN (
SELECT DISTINCT PARENT
FROM #RESULT
WHERE PARENT <> 'Business' -- Excluding the root
);
This approach worked for non-Level0 Shared members, but performance was bad in cases involving the parallel hierarchies.
Third approach was to recreate the hierarchy for non-Leaf shared members by getting the details from the base members. This approach will make use of bridge table thus facilitating the aggregation without use of custom rollup property.
For e.g.
--Insert the Hierarchy under Non Leaf Shared members from main hierarchy.
DECLARE @Parent VARCHAR(242), @ParentHierkey VARCHAR(242);
DECLARE parent_cursor CURSOR FOR
SELECT CHILD, HIERKEY -- Child is used as parent
FROM PRSFY15.DIM_BUSINESS_PC
WHERE HIERKEY IN (
SELECT PARENT + '|' + CHILD AS HIERKEY
FROM STAGING.PRSFY15.DIM_BUSINESS_PC
WHERE DATA_STORAGE IS NULL
AND CHILD IN ( -- If it exists as PARENT column then it is not a leaf member
SELECT PARENT FROM STAGING.PRSFY15.DIM_BUSINESS_PC
)
)ORDER BY DISPLAY_ORDER;
OPEN parent_cursor;
-- Fetch first row
FETCH NEXT FROM parent_cursor
INTO @Parent, @ParentHierkey;
-- Check @@FETCH_STATUS to see if there are any more rows to fetch.
WHILE @@FETCH_STATUS = 0
BEGIN
WITH #HIER (PARENT, CHILD, ALIAS, CONSOLIDATION, HIERKEY, NEW_HIERKEY, DISPLAY_ORDER, PG_UDA, FORMULA, ONLYINSSASFLAG, NEW_PARENT)
AS
(
SELECT
A.PARENT
,A.CHILD
,A.ALIAS
,A.CONSOLIDATION
,A.HIERKEY
,@ParentHierkey + '|' + A.HIERKEY AS NEW_HIERKEY
,A.DISPLAY_ORDER
,A.PG_UDA
,A.FORMULA
,'Y' AS ONLYINSSASFLAG
,@ParentHierkey AS NEW_PARENT
FROM PRSFY15.DIM_BUSINESS_PC A
WHERE A.PARENT = @Parent
UNION ALL
SELECT
B.PARENT
,B.CHILD
,B.ALIAS
,B.CONSOLIDATION
,B.HIERKEY
,@ParentHierkey + '|' + B.HIERKEY AS NEW_HIERKEY
,B.DISPLAY_ORDER
,B.PG_UDA
,B.FORMULA
,'Y' AS ONLYINSSASFLAG
,CAST(@ParentHierkey + '|' + B.PARENT AS VARCHAR(242)) AS NEW_PARENT
FROM PRSFY15.DIM_BUSINESS_PC B
INNER JOIN #HIER Recurse
ON B.PARENT = Recurse.HIERKEY
)
INSERT INTO PRSFY15.DIM_BUSINESS_PC
SELECT NEW_PARENT AS PARENT, CHILD, ALIAS, CONSOLIDATION, NEW_HIERKEY, DISPLAY_ORDER, PG_UDA, FORMULA, ONLYINSSASFLAG
FROM #HIER
-- This is executed as long as the previous fetch succeeds.
FETCH NEXT FROM parent_cursor
INTO @Parent, @ParentHierkey;
END
CLOSE parent_cursor;
DEALLOCATE parent_cursor;
This approach has considerable amount of improvement in mdx queries involving the use of the parallel hierarchies.
Another approach considered was to convert the dimensions from flat hierarchies to snowflake schema. In practice, it means that all the parallel hierarchies are modelled as individual dimensions. But the effort involved was quite a lot, and it was decided not to implement this approach.
b. Unary Operator (~)
We have encountered a specific situation with branches of members that do not need to sum up. In this case parents are used for grouping and for navigation through hierarchy purposes, not for aggregation purposes. Essbase branch is modeled by specifying ~ as operator. This means that children have values but parent should not have any value. While ~ operator is supported in SSAS, Excel client by default will not display the entire branch because the parent does not have any value and even if children are selected they will not be displayed in the report as it requires an extra step to expand the parent. While this behavior can be changed by setting the options to show empty rows/columns this affects the entire report and you cannot hide other rows that are empty. The extra step required to expand the hierarchy and the default behavior of including all the parent of selected members instead of including only the selected members is causing the issue.
Workaround was to set a formula on parents that sets/resets the value to 0 or `'. In this case children can all sum up to parents and usage of unary operator column may not be required but it requires the custom rollup column for the formula.
Note: There is an excel client issue that, selecting just specific members from different levels is challenging as by default parents are added to the report.
c. MDX Formulas
It doesn't recognize members name in the same dimensions and we need to provide the full path. We manually modified the MDX to use full path. No idea if we can extract full path of the member from Essbase directly. But we had both parent child and generations/level based hierarchy output files loaded into SQL database, and used them to build the full path.
Example:
1. Essbase MDX formula:
[Inbound Freight]+[Other Material Costs]+[Labour Related Cost]+[Machinery Related Cost]+[Other Production Overheads]
Has been rewritten to SSAS MDX formula as it follows:
[Accounts].[Accounts Hierarchy].&[Inbound Freight]+[Accounts].[Accounts Hierarchy].&[Other Material Costs]+[Accounts].[Accounts Hierarchy].&[Labour Related Cost]+[Accounts].[Accounts Hierarchy].&[Machinery Related Cost]+[Accounts].[Accounts Hierarchy].&[Other Production Overheads]
2. Essbase MDX formula:
CASE When ( Is([Accounts].CurrentMember,[PRS Sales Volumes]) OR Is([Accounts].CurrentMember,[Sales Volumes Driver])) Then
([Manufacturing]).Value + ([Inventory Holding locations]).Value
Else
([Manufacturing]).Value + ([Inventory Holding locations]).Value + ([Plant Unassigned]).Value + ([Global Overheads MSS]).Value
END
Has been rewritten to SSAS MDX formula as it follows:
CASE
When ( [Accounts].[Accounts Hierarchy].CurrentMember.name='PRS Sales Volumes' OR [Accounts].[Accounts Hierarchy].CurrentMember.name='Sales Volumes Driver') Then
[Plant].[Plant Hierarchy].&[Manufacturing] + [Plant].[Plant Hierarchy].&[Inventory Holding locations]
Else [Plant].[Plant Hierarchy].&[Manufacturing] + [Plant].[Plant Hierarchy].&[Inventory Holding locations] + [Plant].[Plant Hierarchy].&[Plant Unassigned] + [Plant].[Plant Hierarchy].&[Global Overheads MSS]
END
Note: Members involved in the formula may be from different levels.
d. UDA
A user-defined attribute (UDA) describes a characteristic of the members that are assigned a UDA and is used to return lists of members that have the specified associated UDA or in MDX formula to identify member(s) with specific characteristic. There is additional use with UDA but they are not used in PRS/DCOS project.
UDAs can be modeled as columns and value can be checked via Properties property.
When([Accounts].[AccountsHierarchy].CurrentMember.Properties('UDA')='NoUnitCost') Then
Note: Modeling this on a level/generations based dimension is not practical as every generation would need a dedicated attribute column and checking if a member has a specific UDA value would require to know the member's generation number.
4 Conclusion/Summary
We were able to resolve all above issues by modelling the cube in SSAS compared to Essbase. Comparison of reports in EV and Excel is performed and they look identical. We will continue to work on other cubes (<5 years) and share our learnings. We have got great feedback from business users about data visualization and performance was also accepted for both PRS and DCOS applications. It was a great learning for us and we hope it will be useful for others who has decided to migrate OR in dilemma of whether SSAS can provide similar experience as Essbase cube.