BizTalk Server: Processing large files (streaming)
Introduction
Sometimes we will need to receive and process messages containing large files with BizTalk. For this example we will use a message containing information about an invoice, as well as the PDF of the invoice in a base64 encoded string, making this a message of 15MB in total. As BizTalk stores it messages in SQL, and loads the messages while processing, we would want to avoid to have these large messages go through BizTalk. For this, we will be storing the data itself in a temporary location, and using a reference to this data in our message, so BizTalk only has to process a message of 1KB. Once the message had finished processing inside BizTalk, we will place the contents back inside the message. A complete implementation of this sample with all code can also be found on the MSDN Code Samples.
Receive Pipeline Component
To create my custom pipeline components, I love to use the BizTalk Server Pipeline Component Wizard, which takes care of all the plumbing for us. Patches are also available to make this work with the latest BizTalk versions. Start by creating a new project, and follow the wizard to set up your project.

Make sure to make it a receive pipeline component, which operates in the decoder stage, so we can make stripping the data from the message the first action we will do.

We will want to make the path where the data is temporarily stored configurable, so we can set this up on the ports per environment. Also, to make this a generic component, we will add a property where we can specify the node which holds the large data.
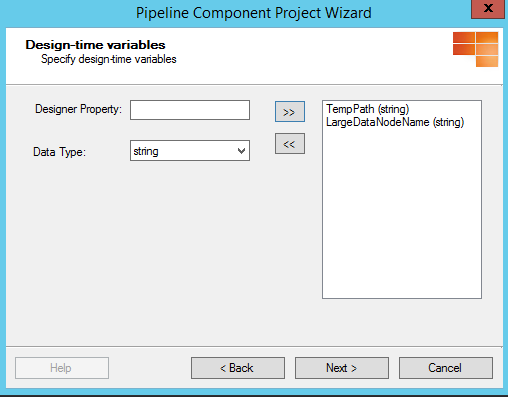
Once we have finished the wizard, it will create our class for our pipeline component with all the plumbing. We now just have to implement our custom logic in the Execute method. We will start by creating the filename of the temporary file. In case no output path was defined on the port, we will use the default Temp path. Be careful with this though if you have multiple BizTalk servers in your group, as the receive might be done on one server, and sending on another, in which case the temporary file can not be found. Therefore, you should always set the path in this case, and use a file-share which all servers in your group can access.
XmlTranslatorStream
To optimize our performance, we will use a streaming approach to work with our messages. To do this, we will make use of a custom class overriding the XmlTranslatorStream class. For more information on the code, check the MSDN Code Sample.
using System.IO;
using System.Text;
using System.Xml;
using Microsoft.BizTalk.Streaming;
namespace Eldert.Samples.ProcessLargeMessage
{
/// <summary>
/// XmlTranslatorStream used to extract contents from a node, and save them in a temporary location.
/// </summary>
public class ExtractLargeDataTranslatorStream : XmlTranslatorStream
{
/// <summary>
/// Boolean indicating if we are processing the node with the data.
/// </summary>
private bool _atLargeDataNode;
/// <summary>
/// Path where we want to store our temporary file.
/// </summary>
public string TempPath { get; set; }
/// <summary>
/// Name of the node with the data we want to extract.
/// </summary>
internal string LargeDataNodeName { get; set; }
/// <summary>
/// Constructor.
/// </summary>
public ExtractLargeDataTranslatorStream(XmlReader reader) : base(reader)
{
}
/// <summary>
/// Constructor.
/// </summary>
public ExtractLargeDataTranslatorStream(XmlReader reader, Encoding encoding) : base(reader, encoding)
{
}
/// <summary>
/// Constructor.
/// </summary>
public ExtractLargeDataTranslatorStream(XmlReader reader, Encoding encoding, MemoryStream outputStream) : base(reader, encoding, outputStream)
{
}
/// <summary>
/// Override, will fire when processing a start element.
/// </summary>
protected override void TranslateStartElement(string prefix, string localName, string nsURI)
{
// Check if this is the node with the data we are looking for
if (localName == LargeDataNodeName)
{
// Set boolean, so next time we enter TranslateText we know we are in the data node
_atLargeDataNode = true;
}
// Continue processing as we normally would
base.TranslateStartElement(prefix, localName, nsURI);
}
/// <summary>
/// Override, will fire when processing a text node.
/// </summary>
protected override void TranslateText(string s)
{
// Check if we are processing the data node
if (_atLargeDataNode)
{
// Create output file name
// In case no path was specified, we will use the default temp path
// Make sure to always specify a path in case of a group with multiple servers
var outputFileName = Path.Combine(string.IsNullOrWhiteSpace(TempPath) ? Path.GetTempPath() : TempPath, Path.GetRandomFileName());
// Write the file
File.WriteAllText(outputFileName, s);
// Replace the large data with a pointer to the temporary file
base.TranslateText(outputFileName);
// We have finished processing the node with the large data
_atLargeDataNode = false;
}
else
{
// Process normal
base.TranslateText(s);
}
}
}
}
Execute Method
Now that we have our custom XmlTranslatorStream in place, we can set up the Execute method of the pipeline component we just created. Make sure to pass in the name of the node as well as the temporary path as specified on the port.
public Microsoft.BizTalk.Message.Interop.IBaseMessage Execute(Microsoft.BizTalk.Component.Interop.IPipelineContext pc, Microsoft.BizTalk.Message.Interop.IBaseMessage inmsg)
{
inmsg.BodyPart.Data = new ExtractLargeDataTranslatorStream(XmlReader.Create(inmsg.BodyPart.GetOriginalDataStream())) { LargeDataNodeName = _LargeDataNodeName, TempPath = _TempPath };
return inmsg;
}
Send Pipeline Component
We now have our pipeline component in place for extracting the large data, however, we also need to create a send pipeline component which will insert the data back into the message once BizTalk is done with processing. For this, we will again use the BizTalk Server Pipeline Component Wizard.

In this case, we will need to specify one property on the port, which will specify the name of the node where the data should be inserted into. In the case of mappings, make sure to map the path we have set in the receive pipeline to this node as well.

XmlTranslatorStream
We will use another custom XmlTranslatorStream here to insert the data in a streaming manner as well. The constructors, properties and override of TranslateStartElement are mostly the same as we had specified for our receive pipeline component.
using System;
using System.IO;
using System.Text;
using System.Xml;
using Microsoft.BizTalk.Streaming;
namespace Eldert.Samples.ProcessLargeMessage
{
/// <summary>
/// XmlTranslatorStream used to insert the contents we previously extracted back into a node.
/// </summary>
public class InsertLargeDataTranslatorStream : XmlTranslatorStream
{
/// <summary>
/// Boolean indicating if we are processing the node with the data.
/// </summary>
private bool _atLargeDataNode;
/// <summary>
/// Name of the node with the data we want to extract.
/// </summary>
internal string LargeDataNodeName { get; set; }
/// <summary>
/// Constructor.
/// </summary>
public InsertLargeDataTranslatorStream(XmlReader reader) : base(reader)
{
}
/// <summary>
/// Constructor.
/// </summary>
public InsertLargeDataTranslatorStream(XmlReader reader, Encoding encoding) : base(reader, encoding)
{
}
/// <summary>
/// Constructor.
/// </summary>
public InsertLargeDataTranslatorStream(XmlReader reader, Encoding encoding, MemoryStream outputStream) : base(reader, encoding, outputStream)
{
}
/// <summary>
/// Override, will fire when processing a start element.
/// </summary>
protected override void TranslateStartElement(string prefix, string localName, string nsURI)
{
// Check if this is the node with the data we are looking for
if (localName == LargeDataNodeName)
{
// Set boolean, so next time we enter TranslateText we know we are in the data node
_atLargeDataNode = true;
}
// Continue processing as we normally would
base.TranslateStartElement(prefix, localName, nsURI);
}
/// <summary>
/// Override, will fire when processing a text node.
/// </summary>
protected override void TranslateText(string s)
{
// Check if we are processing the data node
if (_atLargeDataNode)
{
// Get data from temp file
var data = File.ReadAllText(s);
// Replace temporary file path with actual data in node
base.TranslateText(data);
try
{
// Delete temporary file
File.Delete(s);
}
catch (Exception)
{
// ignored
}
// We have finished processing the node with the large data
_atLargeDataNode = false;
}
else
{
// Process normal
base.TranslateText(s);
}
}
}
}
Implementing Pipelines
Now that we have our custom pipeline components in place, we can use these to create the pipelines which will do the extracting and insertion of the data.
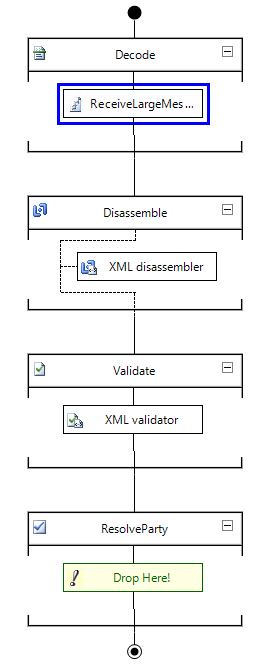
And finally, we have to create our ports which use these pipelines. Make sure to set the correct properties in the pipeline configuration.
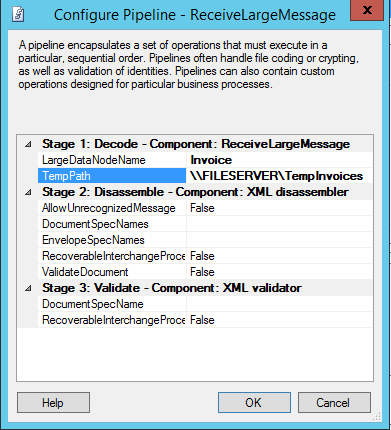
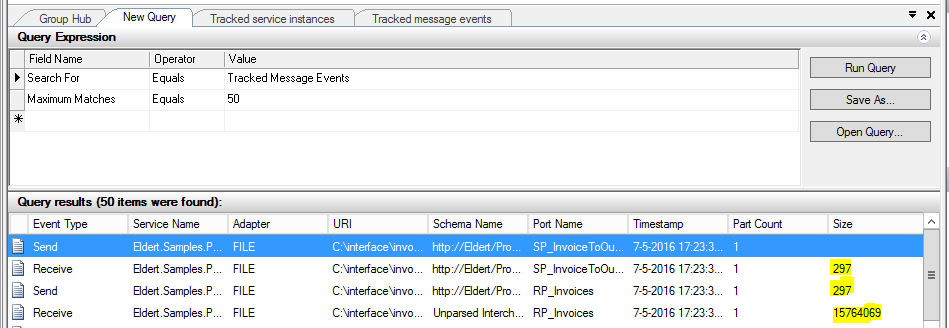
Now when we receive a message our receive pipeline extracts the data, places it in a temporary file, and BizTalk starts its processing. This can include any normal BizTalk processing including orchestrations etc., which would have had a major performance impact if we would have left the data in the message. Only once BizTalk has finished all its processing, and the message is being sent out, the data is placed back into the message, without having ever been in the message box, allowing for much better performance.
See Also
For more information on using a streaming approach in your pipeline components, I found this blog series very helpful.
Another important place to find an extensive amount of BizTalk related articles is the TechNet Wiki itself. The best entry point is BizTalk Server Resources on the TechNet Wiki.