Windows Azure SQL Database Delivery Guide for Business Continuity
This delivery guide provides a primer for solution implementers who are starting a project which will (or may) use Windows Azure SQL Database. The guide is aimed at experienced architects and developers who already have a background with SQL Server and perhaps with the .NET Framework. A good familiarity with T-SQL, SQL Server features and administration, and application architectures based on the Microsoft stack is assumed. The guide familiarizes the reader with the things they need to know to get started designing and delivering solutions which include the SQL Database data platform.
Note
If you wish to contribute to this page, use the Edit tab at the top (sign-in required). If you wish to provide feedback for this documentation please either send e-mail to azuredocs@microsoft.com or use the Comment field at the bottom of this page (sign-in required).
Table of Contents
- Planning
- Developing
- Designing Data Models for SQL Database
- Designing to Limit the Impact of Latency on Remote Client Code
- Using Entity Framework to Code against SQL Database
- Using SQL Database from PHP or Java Code
- Designing for Scale Out
- Tuning and Optimizing A SQL Database Workload
- Synching Data between On-premise and Cloud
- Synching Data between Different Azure Sites
- Handling Azure-specific Error Conditions in Application Code
- Capturing the Trace Identifier
- Exposing SQL Database Data for Web Service Consumers
- Server Management Objects (SMO)
- Deploying
- Maintenance and Operations
Planning
The path to an effective SQL Database solution begins with solid planning. Early architectural decisions will affect the rest of the project and the ultimate success of the solution. Planning the data platform for your scenario involves several key decisions, starting with whether SQL Database or on-premise SQL Server is the best tool for the job. Assuming SQL Database will play a role in your solution, there are a variety of potential application architectures to choose from. Certain factors to be understood are the SQL Database Service Level Agreement (SLA), the impact of latency in the chosen architecture, availability and disaster recovery scenarios, and developer tools.
This section dives into these topics to help you make the appropriate decisions early-on.
Choosing Between On-Premise SQL Server and Cloud SQL Database
If you are developing a solution which will include one or more SQL Server relational databases, the first architectural/planning decision that must be made is whether to deploy that database to SQL Database in the cloud or to an on-premise SQL Server instance.
SQL Database offers an extremely easy-to-use relational database engine which is architected natively as a large-scale, highly available, multi-tenant cloud service.
There is an economic and operational argument for eliminating onsite hardware and software and all the upkeep that goes with it. And extending the reach of the database and possibly other application components outside the enterprise firewall can enable many new scenarios.
How to decide for SQL Database, when sometimes on-premise SQL Server appears to be the more appropriate choice? There are differences in the breadth of functionality provided by the two products. There are different capacity constraints, and some features behave differently between SQL Database and traditional on-premise SQL Server. At the end of the day, the most important consideration is what will lead to a successful solution and a satisfied customer? The choice between SQL Database and on-premise SQL Server should be made with this as the fundamental criterion.
The decision tree in Figure 1 illustrates some of the factors that should go into making the choice between SQL Database and on-premise SQL Server.
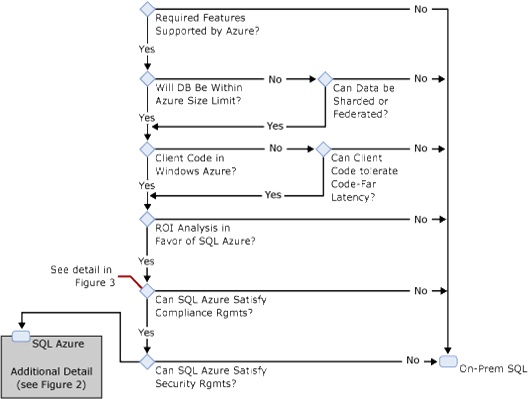
Figure 1 - Choosing Between SQL Database and On-Premise SQL Server
As Figure 1 shows, there are several decision points (technical, economic, and policy-related) which may lead you one way or the other.
It is worth noting that requirements for unstructured storage are not considered a deciding factor between the two options. With on-premise SQL Server, you have SQL’s binary and large text data types available, as well as FILESTREAM storage and all the resources available from the Windows operating system (file system, MSMQ, etc.). With SQL Database, SQL’s binary and large text data types are also available, although FILESTREAM storage is not supported. Windows Azure tables, blobs and queues round out the support for unstructured storage. So, a combination of structured and unstructured storage needs can most likely be met equally well on-premise or on the Azure platform.
Once decided that SQL Database is the right choice for your solution, you will also need to choose the edition (Web or Business), the database size (various choices between 1GB and 150GB) and the geographic location(s) at which the database(s) are hosted. (Because this guide is focused on SQL Database rather than on-premise SQL Server, no further detail is provided here about the on-premise path.)
Figure 2 provides a decision path through the edition and size options for SQL Database between the Web and Business Editions of SQL Database.
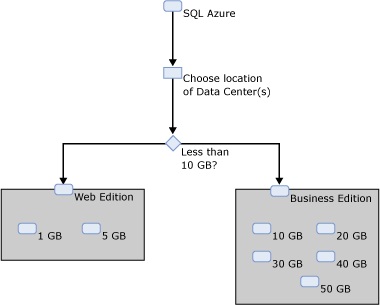
Figure 2 - SQL Database Choices
The geographic location depends on where your users are, to what degree you want to exploit geographic distribution for disaster tolerance, and what regulatory/compliance factors, if any, apply to your situation.
The following table lists the SQL Database hosting locations at the time of this writing. There is no important technical difference between the data centers, other than their location. Note that bandwidth from the Asia data centers is currently priced higher than others.
| North Central US | West Europe |
| South Central US | East Asia |
| North Europe | Southeast Asia |
Notes on Compliance
A key factor in making the data platform decision is compliance with relevant regulations or laws related to data handling. Depending on the data involved and the country, or other jurisdiction, there may be limitations on where and how data can be stored. This step from the decision tree in Figure 1 (“Can SQL Database satisfies compliance requirements?”) is expanded into greater detail in Figure 3.
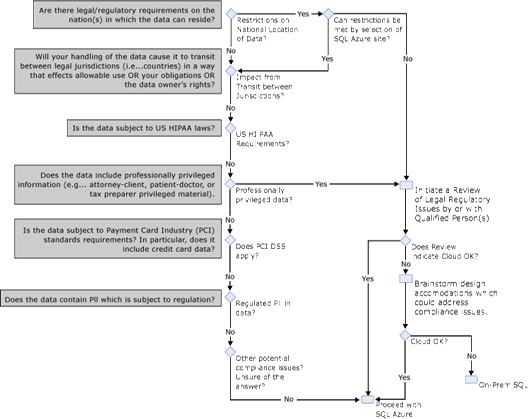
Figure 3 - Evaluating Compliance Factors Related to SQL Database vs. On-Premise Data Hosting
As Figure 3 indicates, there are a number of things which could impact how you can handle data in your solution. Additional notes on some of these considerations are provided in the table below.
| Consideration | Notes |
| Does the location (i.e., country) where the data resides matter? | In some scenarios, data must remain within a specific country. Note that the Azure terms of use do not guarantee Azure-stored data will remain in a single country, regardless of the chosen data center. |
| Would transferring the data across political/legal boundaries affect legal or regulatory status? | It may be possible that transferring certain kind of data may cause new legal requirements to attach. For example, the EU Data Protection Directive could come into effect if personal data sourced elsewhere ends up stored within the EU. |
| Is the data covered under government or industry data handling regulations (e.g. HIPAA, PCI, PII handling policies, etc.)? | These and other compliance regimes have specific limitations on data handling. If any of these apply, you will need to evaluate their impact on your data platform choice. |
| Does the data contain professionally privileged information? Would storing it in the cloud affect this status? | For example, attorney-client or patient-doctor privileged information. Placing this data in the hands of a third party (i.e., cloud provider) might loosen the protections it has. Another example in the US is tax preparation information. A tax preparer (e.g. accountant) may not share tax information with a third party without express client consent. |
| Compulsory disclosure to authorities. | Depending on the jurisdiction where the data is stored, different laws may apply concerning the cloud provider’s requirements to share data with law enforcement or government authorities. In such an event, notification to the owner may or may not be allowed/required. |
Notes on Security
The decision tree in Figure 1 also calls out security as a consideration affecting the decision to use SQL Database. The term “security” is used here in a strictly technical sense, to differentiate it from the issues related to compliance. At the technical level, there are many security features of SQL Server that are fully supported (or even mandatory, such as SSL connection encryption) in SQL Database and some which are not available.
Considering the scope of a single database, most of the security features of SQL Server are available in SQL Database. These include user and role definition and access control via GRANT/ DENY/REVOKE on objects with the database. At the server level, SQL Database allows logins to be created (with SQL Server authentication only) and provides a set of server-level roles similar to those in on-premise SQL Server.
Connections to SQL Database are SSL-encrypted by default – this cannot be disabled. And, all connectivity to SQL Database is protected by a firewall. You must create firewall rules to allow access from the location(s) where client code resides.
There are, however, some security features of on-premise SQL Server which do not apply to SQL Database. These include:
- Logging of successful and failed logons
- Logon Triggers
- Password expiration or forced password-change. SQL Database does enforce a password complexity policy, but it is not customizable.
- Windows Integrated Authentication
- The SQL Server Audit feature
- Key-based Encryption inside the database
- Transparent Data Encryption (TDE)
SQL Databases are not encrypted on disk in the Azure data center.
As part of data platform selection, you should ensure that the chosen platform meets the specific security-related requirements for your solution.
Notes on ROI Evaluation
Economic justification is a crucial aspect of choosing between SQL Database and on-premise SQL Server. In general, it is very important that an ROI evaluation compare SQL Database costs (mostly the subscription/consumption fees) to all costs associated with provisioning and running an on-premise SQL Server. On-premise costs include hardware acquisition and software licensing, of course, but also extend to the cost of rack space, hardware support contracts, electricity for servers and cooling, network equipment, and the staff costs for DBA and/or server administrators to support and patch servers. A full analysis will amortize costs over the lifecycle of the gear and/or solution to compare annual costs with a SQL Database based solution.
In broad terms, based on preliminary data, ROI analysis leans in favor of SQL Database in the following conditions:
- Customer will have to purchase new hardware or replace existing hardware to support the solution on-premise.
- The database code will be new development or can be moved to SQL Database with trivial effort.
- The solution will only need to exist for a short period (e.g., a seasonal marketing site).
- The solution’s business value to the customer does not warrant staff resources to manage, patch, and monitor on-premise servers.
- Transient bursts usage such as pizza ordering site which has usually low to moderate activity except during special occasions such as key sporting events, or promotions; important to note that the application need to be properly architected to take advantage of the scale out benefits of SQL Database.
ROI analysis has often favored on-premise SQL Server in the following conditions:
- Customer has the option to use already-purchased hardware with existing “sunk-cost” resources.
- The database or application code already exists and would require non-trivial changes or re-testing to deploy in SQL Database.
Overview of Cloud and On-Premise Architectures
As a tool in the solution architect’s toolbox, SQL Database is useful in a variety of scenarios. This section presents several common architectural patterns used by SQL Database early adopters.
SQL Database + Windows Azure Applications
As might be expected, SQL Database is a natural and highly effective choice when a Windows Azure application requires a relational data store. When SQL Database and the other Windows Azure components are deployed to the same site, code-to-database latency is essentially eliminated. Also, bandwidth in and out of SQL Database is free when the client endpoint is within the same data center as Azure application.
A typical Windows Azure architecture, using Web and Worker roles with one or more SQL Databases, is depicted in Figure 4.
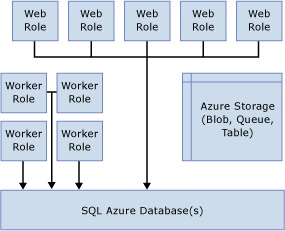
Figure 4 - Typical Windows Azure Architecture
With the recent support in Windows Azure for full IIS in web roles and custom VMs, such architecture can also include almost any other kind of presentation and business tier application code. For example, if a customer has a large legacy COM+ layer fronted by ASP.NET web pages and upgrading this code is not an option, they might still be able to deploy the application tier to Windows Azure as custom VMs, with SQL connection strings pointing to one or more SQL Databases. Such a case is depicted in Figure 5. Of course, this is just one simple example - the possibilities with custom VMs are very broad.
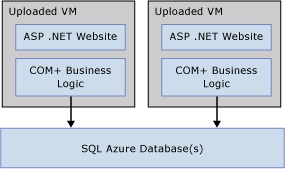
Figure 5 - Azure Custom VM's Hosting COM+ and ASP.NET Code, Hitting SQL Database
Example Customer Scenarios
- Cloud-based line of business or SaaS application
- Marketing site or other short-lifespan public web application
- Data sharing/collaboration and content distribution
Spanning Applications (Cloud + On-Premise) with SQL Database
Another great use for SQL Database is as a relational store in a “spanning application”. A spanning application, sometimes also called a hybrid application, is a solution in which some components run on-premise and some run in the cloud.
A spanning architecture can be useful for bringing together the attributes of SQL Database with the attributes of internally hosted custom code. For example, using SQL Database as a data platform can provide the benefits of high availability and a management-free hosting experience, eliminating the headaches and cost associated with running an on-premise database server. All too often, attempting to run a production database server without the proper infrastructure simply results in a poor service level to the business. Properly architected SQL Database can mitigate this.
SQL Database can also provide a data store accessible from locations dispersed across geographies and organizational boundaries, with a fraction of the effort and cost that might be required to deliver the same experience in more traditional ways.
A spanning architecture, in addition, can leave complete flexibility on how other layers of the application stack are assembled. Does the application use an assemblage of Office, Sharepoint, or other components not suited to external cloud hosting? No problem. Does the application integrate a mish-mash of multi-vendor technologies, yet need a relational SQL data store as a back end? No problem. Do application tier instances need to run on separate networks, with separate authentication methods and user directories, while connecting to the same database with a trusted sub-system model? No problem. Does the application tier require some specialized hardware or licensing accommodation, preferably combined with a standard, cost-effective, and easily managed RDBMS? In all these cases, a spanning application can be an effective approach.
Example Customer Scenarios
- Partially cloud-based line of business application
- Departmental data application or information worker data store
- Multi-organization data sharing/collaboration
SQL Database as an Extension of an On-Premise Architecture
A simpler and sometimes valuable way for SQL Database to extend the reach of an on-premise application is when acting as an extension of an on-premise solution. This differs from a spanning application in that the on-premise application is fully self-sufficient. However, it is able to provide some incremental functionality through an extension into the cloud; the cloud then hosts a “spoke” supported by the on-premise “hub”.
One example of this approach is a SQL Database used to expose partial data from an on-premise Line-of-Business (LOB) application to roaming users. For example, a frequently updated product and price list could be hosted in a SQL Database, regularly synchronized from an on-premise solution. This product/price list could then be accessed by roaming users from their laptops or mobile devices, most likely in combination with some desktop tool or with other Azure-hosted code. In fact, it would be easy for the users of this data to include employees of partner or customer companies, as well.
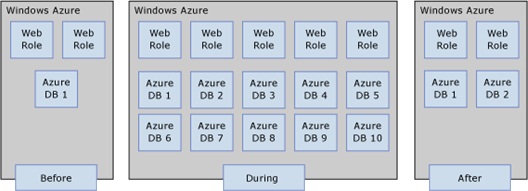
Figure 6 - Extension of Partial/Full On-Premise Data Set to External Users
Much of the same objective can be achieved with VPN and/or DMZ-hosted servers. However, there is cost and work associated with setting this infrastructure up, properly securing it, and maintaining it. By comparison, deploying the data to a SQL Database is simpler in terms of effort and cost.
Example Customer Scenarios
- On-premise line-of-business application with some cloud-based extended functionality
- Data sharing/collaboration and content distribution
SQL Database for Capacity Bursting
One of the key value propositions for cloud computing is the ability to scale up and scale down promptly and cost-effectively. Some business solutions naturally have large spikes in processing load or volume. Examples include:
- A retail organization with high seasonality. For example, a flower seller at Valentine’s Day, a toy retailer at Christmas, or a tax preparation firm during tax season.
- A corporate application which surges with certain business events, such as end of the quarter or fiscal year, employee review time, or HR benefits enrollment.
- An event-specific usage pattern, such as marketing campaign sites or ticket sales for sporting/entertainment events.
SQL Database is a great tool for supporting capacity bursts at the data tier. Databases can be created and dropped with ease. The SQL Database architecture causes databases within a single service (i.e. logical SQL Database server) to be spread across a large pool of computing resources, so the “server” will not risk be overtaxed. And, SQL Database usage charges accrue day-by-day, so adding and removing databases within narrow time windows results in granular, cost-effective billing.
Figure 7 depicts a notional Windows Azure architecture in which the data tier scales up and then down in response to some business-related surge in activity.
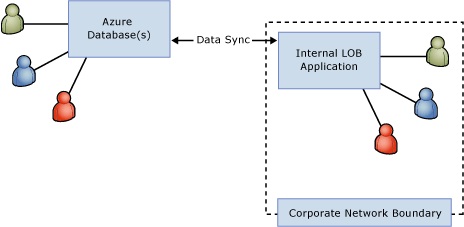
Figure 7 - Before, During, and After a SQL Database Capacity Burst
Although SQL Database provides the tools to easily support capacity bursting, some design forethought is required to allow the application to spread data across the available SQL Databases. The typical pattern for doing this involves consciously splitting data across multiple databases and ensuring the application know which connection string to use to get the information it needs. Usually it is best to split the data across databases horizontally, a technique sometimes called “sharding”.
In the sharding approach, the ‘big’ or heavily accessed tables are logically partitioned across databases. For example, in a customer-centric solution, 10% of the customers may be stored in each of 10 identically structured databases along with all their related data in other tables. Common data may be in a separate database or may be duplicated in each database.
The client code must have the awareness to connect to the proper database for the customer relevant to the current data access request. There will be more discussion of sharding, and other scale-out approaches, later in this document.
SQL Database will also be introducing a new feature called Federations to help with scale-out implementations. This will most likely become available in 2011. Previews of this feature have been shown at PDC and other technical conferences. More on Federations will also be covered later in this document.
Example Customer Scenarios
- Solutions with seasonal (or otherwise periodic) usage peaks
- Solutions with big activity surges around predictable events
- Solutions which must temporarily exceed the maximum size of a single SQL Database.
Understanding the SQL Database SLA
Before deciding to run a solution partially or entirely on the SQL Database data platform, it is important to understand the Service Level Agreement (SLA) extended by Microsoft.This SLA is an integral part of the service. When you, or your customer, buy SQL Database, you are buying the service level defined in this document.
The SLA for SQL Database is an availability SLA. It promises a specific uptime percentage. If the service fails to meet that uptime percentage in a given month, the affected customers are entitled to a partial refund of the fees for that month.
SQL Database does not currently provide any SLA for performance or for security. The most current SLA document can be found here.
Currently, the availability SLA for SQL Database is 99.9% uptime in a given month. A 10% refund is granted if availability falls below 99.9% and a 25% refund is granted if availability falls below 99%. Note that the SLA allows for up to 10 hours of scheduled downtime per calendar year, which is excluded from the availability calculation. Customers will be notified of scheduled downtime at least five days in advance.
In selecting SQL Database as a data platform, and in planning the operational details of your solution, it is important to be cognizant of this SLA, what it covers, and what it does not cover. A small number of customers need a better uptime assurance than this. On the other hand, many, many customers would be very happy to achieve three nines of availability for what SQL Database costs.
High Availability and Geo-Replication
SQL Database has a high-availability (HA) architecture built-in, it actually exposes nothing to administrators in terms of HA configuration. HA concepts from on-premise SQL Server, such as failover clustering, database mirroring, and log shipping, do not apply in SQL Database. However, SQL Database’s internal storage architecture is such that all writes are triply redundant across independent commodity servers. So, a high level of data protection is inherently provided.
The triple redundancy within the Azure data center combined with the 99.9% availability SLA essentially is the SQL Database HA story. There are no other features or ‘knobs’ exposed.
This leaves open the question of disaster recovery – how does one protect against the unlikely scenario of an entire Azure data center being unavailable or lost? There is no provision for remote replication built directly into SQL Database. There is, however, an offering which allows partial or full synchronization across SQL Database sites or between SQL Database and an on-premise SQL Server instance. This is discussed later in this document in the section on “SQL Data Sync.”
Issues SQL Database Mitigates
SQL Database is a relational database engine made specifically for the cloud. As such, it is able to deliver on many of the promises of cloud computing which relate to simpler and cost effective management. In the planning stages of a project which will use SQL Database, some categories of operations and infrastructure planning can essentially be skipped.
A partial list of the issues that are mitigated by SQL Database:
- Hardware refresh planning and expenses
- Hardware support contracts
- Software licenses for operating system, DBMS, anti-virus, etc.
- Downloading, testing, and applying patches for the operating system or DBMS.
- Server backups
- The need for hardware redundancy, power conditioning and battery or generator backup
- Obtaining rack- or floor-space for servers
- Air conditioning
- Staff resources to backup, monitor, secure, and otherwise manage databases. This is especially attractive for small, departmental data applications which don’t warrant professional DBA’s.
- For enterprises: IT cost loading related to database servers
SQL Server Features Not Included in SQL Database
Although SQL Database mitigates a broad swath of issues that go along with running on-premise database servers, today, it does not cover the full breadth of features in on-premise SQL Server. First, it should be noted that SQL Database is roughly equivalent to the Database Engine in SQL Server. Other components of SQL Server – namely Analysis Services and Integration Services – are not provided by SQL Database. A Windows Azure-based Reporting Services offering was announced in late 2010; that offering is not included in this guide.
Within the Database Engine, the following are unsupported by SQL Database:
- Replication
- Full-text Search
- Backup/Restore
- Database Attach/Detach
- Service Broker
- Linked Servers and four-part names
- Table Partitioning
- Distributed Transactions
- Server and Database Level Collations (column- and expression-level are supported)
- Audit
- Encryption
- Trace/Profiler
- Logon Triggers and certain other server-level DDL triggers
- Windows Authentication
- Data Compression
- CLR Integration
- Extended Stored Procedures
- Change Data Capture
- Extended Events
- FILESTREAM Data
- Resource Governor
- Sparse Columns
- SQL Server Agent
- Policy-based Management
- Performance Data Collection
- The “use” directive for switching database context
- Three-part names when the database name is not the current database or tempdb
- Some dynamic management views
It is important to note that SQL Database is a constantly changing product and new features are continuously being rolled out. For latest information on feature differences, see the SQL Database documentation, especially Guidelines and Limitations and the Transact-SQL Reference.
Tools for Administering and Developing
Support for SQL Database has been included in most of the latest-generation development tools from Microsoft. The following tools are recommended for working with SQL Database.
- SQL Server Management Studio 2008 R2. This ships with SQL Server 2008 R2 and is also available as free download (SQL Server Management Studio Express 2008 R2). Previous versions of SSMS allow query window connections to SQL Database, but cannot connect Object Explorer to SQL Database. SSMS 2008 R2 addresses this and also provides Generate Script options expressly aimed at SQL Database.
- The Windows Azure Platform Management Portal, at https://windows.azure.com/.
- The Database Manager for SQL Database at https://manage-ch1.sql.azure.com/. This was formerly known as Project “Houston”.
- The sqlcmd command line utility.
- Visual Studio 2010. The 2010 release of Visual Studio supports SQL Database in the Server Explorer window; previous versions do not. VS 2010 Data-tier applications (DAC) can be used with SQL Database; VS 2010 Database and Server projects do not work with SQL Database.
Developing
In most respects, building relational SQL databases for SQL Database is essentially identical to building them in on-premise SQL Server. As with any tool, however, there are certain unique factors which come in to play when developing for SQL Database.
This section covers many of those topics to prepare you for effective development. Most of concepts about SQL Server development will apply to SQL Database and this guide won’t revisit them. Certain things that are different, or where you may need to make different decisions, are covered in this section.
Designing Data Models for SQL Database
In broad terms, the design of a data model for SQL Database is no different than it would be for an on-premise SQL Server deployment. There are some lower-level technical details which differ, but they don’t change the essentials of how a data model is built. That said this section enumerates some of the technical details to be aware of in designing your SQL Databases.
All tables must have a clustered index. In on-premise SQL Server, tables may be created without clustered indexes (such tables are referred to as heaps). For internal reasons related to SQL Database’s redundant/replicated storage, heaps are not allowed. A CREATE TABLE statement that does not specify a clustered index can be executed, but an error will be thrown if an INSERT is attempted before a clustered index is added to the table.
No filegroup may be specified for tables or indexes. This is a simple consequence of the fact that SQL Database eliminates physical management of database files. When a table is created, SQL Database manages where it goes, as well as where/how database files are laid out on disk.
Table partitioning is not supported. Do not include partitioning in your SQL Database data model designs.
Data Type support is slightly limited compared to on-premise SQL Server. The most common data types are all fully supported. Geography and geometry data types are also supported.
- Because CLR integration is not supported, CLR user defined types are not allowed.
- The xml data type is supported, but typed xml using schemas is not.
- Uniqueidentifier is supported, as is the NEWID() function. The NEWSEQUENTIALID() function is not supported.
- Legacy large object types (text, ntext, image) are supported. However, deprecated functions for manipulating these types (READTEXT, WRITETEXT, UPDATETEXT) are not supported. In any case, varchar(max), nvarchar(max), and varbinary are the preferred data types for large string or binary data.
Details of data type support can be found in the SQL Database documentation on Data Types and in the discussion of supported/unsupported features in the Azure Transact-SQL Reference.
Designing to Limit the Impact of Latency on Remote Client Code
One of the chief architectural challenges of a spanning application which combines on-premise code with Azure-hosted databases is the network latency between application code and the Azure database(s). For applications hosted entirely in Windows Azure (at least within one Azure site), this is largely a non-issue. For more geographically distributed solutions, care should be taken in the code design to minimize the impact of network latency.
Achieving this goal usually means focusing on two things. The first is keeping the number of round trip calls to SQL Database as minimal as possible. The second is keeping the volume of data transferred as small as possible.
Consider the following simple example which shows three different ways of coding to accomplish the same end result. For the sake of illustration, assume you have a single table of messages for your ‘followers’ stored in a SQL Database. Sample 1 shows the DDL for this table and for two stored procedures which insert data into it.
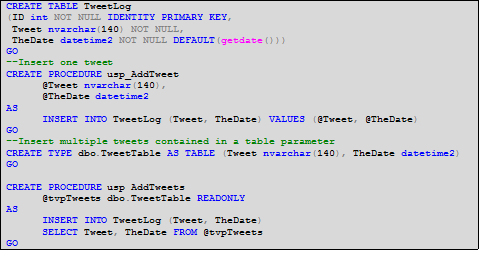
Sample 1 - Create table and stored procedures
The first stored procedure (usp_AddTweet) is a simple, very typical way of inserting one record. The second stored procedure (usp_AddTweets) accepts a parameter of type table and inserts all items in the table parameter within a single stored procedure call.
Let’s take a look at three ways to add 100 tweets to the TweetLog table.
Sample 2 shows a C# method which inserts 100 tweets by creating an ADO.NET SqlCommand and executing it in a for loop. The content of the tweet is irrelevant, so we just use a meaningless string.
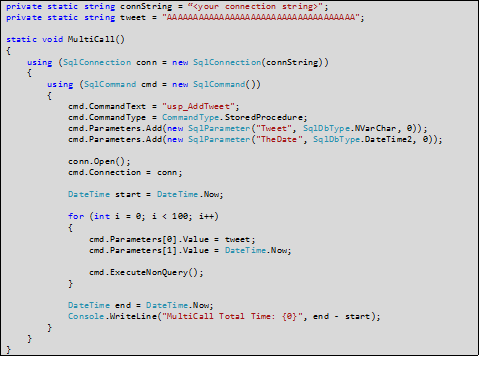
Sample 2 - C# Application Code to Insert 100 Records (In a Loop)
As you might expect, there will be a lot of unnecessary overhead simply performing the round trips to the SQL Database service to invoke the stored procedure 100 times.
Another approach might be to construct a batch of SQL text and submit it to the database in one call. The code in Sample 3 does this, stringing together 100 INSERT statements and then executing the batch in one execution of a SqlCommand.
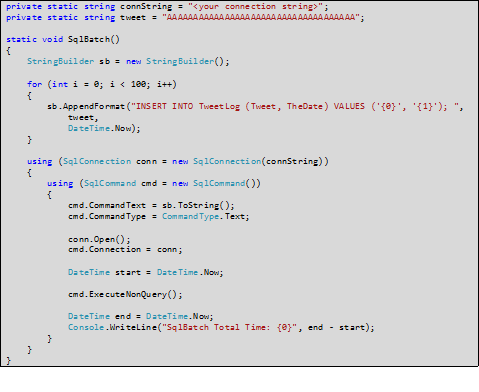
Sample 3 - C# Application Code to Insert 100 Records (In a Single Batch)
Yet another approach is to use table parameters, a feature introduced in SQL Server 2008. Here, we can call a stored procedure one time with all the data stuffed into a single, structured parameter. In this case, the stored procedure we call is usp_AddTweets, defined earlier in Sample 1.
A key part of making this work is the object we assign to the ADO.NET SqlParameter for the table parameter. This can be a DataTable, a DataReader, or a custom C# class like the one in this example. Sample 4 provides the code for this approach.
As with the SQL batch example, we are making only one call to the SQL Database in this method.

Sample 4 - C# Application Code to Insert 100 Records (With a Typed Table-valued Parameter)
How do these three examples perform? The table below shows times reported by these code snippets when run from the Eastern United States against the North Central US SQL Database site. Of course, your results will likely vary based on your location, the target Azure site, and network conditions. The conclusion, however, should keep similar proportions.
| Sample | Avg. Total Time |
| 100 Stored Proc Executions ( Sample 2) | 3805 ms |
| One Batch of SQL Inserts ( Sample 3) | 263 ms |
| 1 Stored Proc Execution, with Table-valued Parameter ( Sample 4) | 61 ms |
The poor performance of the 100 stored procedure calls is not surprising. Perhaps more informative is the superior performance of Sample 4 over the batch of SQL text in Sample 3. Obviously, both benefit from using a single round trip. Sample 4, however, seems to benefit from more compact payload on the wire and plan optimizations provided by the stored procedure.
Experienced developers will recognize that this is nothing new. It is long held best practice in client server and distributed systems development to minimize round trips between application code and a remote database server. Working over the Internet with cloud hosted data, however, makes this best practice more important than ever. In fact, it can make or break the viability of an architecture.
Although the example is trivial, the contrast of these three approaches is a useful illustration of options to consider in designing your own code. In particular, stored procedures with table parameters are a very effective technique. Note that there can be multiple table parameters on a stored procedure. So, for example, a complete header-detail INSERT transaction could be achieved in one procedure call.
Using Entity Framework to Code against SQL Database
The ADO.NET Entity Framework is a part of the .NET Framework which provides a rich set of classes for creating distributed data-sharing applications. Entity Framework fully supports SQL Database, and is a good option for productively creating data access code which will interact with SQL Database.
Be aware that, when using Entity Framework (EF) with SQL Database, the choice between Lazy Loading and Eager Loading of related objects can be very impactful if your code will run remotely from SQL Database. Similar to the discussion of latency in the previous section, forcing EF to minimize round trips with Eager Loading can benefit performance. Of course, the best choice may vary based on the amount of data in your database and the client access patterns.
The following MSDN Magazine article, found here, offers more information on lazy v. eager loading in EF with SQL Database.
Using SQL Database from PHP or Java Code
SQL Database supports connections from PHP using the Microsoft Drivers for PHP for SQL Server. Connecting to SQL Database requires providing a connection string which references a SQL Database data source. See MSDN for the latest information and downloads for this driver.
SQL Database access from Java code, using the Microsoft JDBC driver, has been possible but not supported for some time. As of Feb 2, 2011, an updated version of the SQL Server JDBC 3.0 driver is available here with full support for SQL Database.
Web services are another important option to consider for Azure access from cross-platform stacks. Probably the best place to start on this path is WCF Data Services (a.k.a. [[OData]]). With Windows Azure, you can host any type of web service layer (ASMX or various WCF channels, for example) to expose SQL Database data.
Designing for Scale Out
A key architectural option to consider with SQL Database is scaling out. “Scaling out” means spreading data and processing workload across multiple databases.
There are two main reasons scale-out is especially interesting for SQL Database. The first is that with the current version of SQL Database the maximum size of a database is 150GB. For applications which require more data, the option is to divide the data into multiple databases which remain within the size limit.
The second reason is that elasticity, a key pillar in cloud-computing’s value proposition. To fully realize this benefit, an application which uses SQL Database can be designed to distribute its data across several physical databases. When the need for storage capacity and/or processing power is minimal, the number of databases can be ramped down. When the need is high, the number of databases can be ramped up. Ideally, an application could transparently interact with the data regardless of the number of databases in use. The practical reality today is that this takes work to implement regardless of the architecture, on-premises or cloud-computing.
The current story with respect to scaling out across multiple SQL Databases is to implement a sharded database design. It is in the plan for future releases of SQL Database to introduce a feature called Federation to make such implementations easier.
Sharding
A ”sharded” database design is one which divides data “horizontally” across databases. If you are familiar with the concept of distributed partitioned views, then you have the basic idea of sharding.
A very thorough discussion of sharding principles and techniques can be found on the SQL Database TechNet Wiki here.
SQL Database Federation
SQL Database November 2011 release offers Federations in SQL Database. This is intended to provide engine-level support for horizontally scaled databases. Some of the tasks it makes easier are:
- Connecting to the right database to work with a specific section of data.
- Splitting shards to handle changes in data or workload, without impacting data availability. (Merging will be provided in future versions.)
For early information on this emerging feature area, see the following links:
- Building Scalable Database Solution with SQL Database - Introducing Federation in SQL Database
- Apps that will love SQL Database Federations? Here are a few…
- SQL Database Federations: Robust Connectivity Model for Federated Data
Tuning and Optimizing A SQL Database Workload
The tools for tuning and optimizing a SQL Database workload have some important differences vs. on-premise SQL Server.
Let’s address first those tools that are no longer necessary as the DBMS is hosted on Microsoft-managed servers in the cloud, there is no need to have access to Windows perfmon to peek into the activity on your database. SQL Profiler is unavailable with SQL Database, and some of the performance related DMVs in on-premise SQL are not exposed by SQL Database.
Several key performance-related DMVs are available, however. These include:
- sys.dm_exec_sql_text
- sys.dm_exec_query_stats
- sys.dm_exec_requests
- sys.dm_exec_sql_text
A downloadable whitepaper, Troubleshooting and Optimizing Queries with SQL Database, provides more information on the available DMVs.
SQL Server Management Studio can be used to view estimated and actual execution plans for queries in SQL Database. The standard IO and CPU statistics in Management Studio are also available. The SET STATISTICS IO and SET STATISTICS TIME options return server information; the Client Statistics (Query > Include Client Statistics) provide network traffic and latency information.
Synching Data between On-premise and Cloud
A common need for solutions which mix on-premise and cloud data stores is the ability to synchronize data between on-premise and cloud databases. SQL Database currently addresses this need with the Microsoft Sync Framework. Sync Framework is a .NET-based development framework for synchronizing arbitrary data sources. The Sync Framework Developer Center is a good starting point for resources on this technology.
The bottom line is simple: Sync Framework is the tool recommended to synchronizing on-premise data with SQL Database. Project teams will require .NET development skills to implement data synchronization functionality. Microsoft is investing in expanding and improving the capabilities of Sync Framework when used with SQL Database. Hence, there are some features that SQL Database does not support, such as SQL Replication or Linked Servers. Distributed transactions are also not supported with SQL Database.
While a DBA or SQL-focused developer can configure Replication and other SQL-centric technologies, Sync Framework is currently squarely focused on the .NET developer.
You can also use BCP.exe or SSIS packages to synchronize data between on-premise SQL Server and SQL Database. These may or may not be practical depending on the nature of sync. There are situations where data in SQL Database needs to be sync’d back to SQL Server on premise and all data in SQL Database wiped out; BCP and SSIS are great tools in those scenarios.
As of first half of calendar year 2011, there is a more complete service by invitation-only CTP (click here to register) called SQL Data Sync, which will do both on-premise-to-cloud and cloud-to-cloud synchronization. This is built, of course, atop the Sync Framework. But it removes the need to write code to initiate, configure, and schedule synchronization, instead providing a complete user interface for these tasks. For more information, check out this blog entry here.
Sample 5 shows a minimal code example for performing synchronization between an on-premise SQL Server database and SQL Database using the current version of Microsoft Sync Framework. Two key things to be aware of early when looking at Sync Framework are:
- All synchronized tables must have a primary key
- Some SQL Server data types (e.g., user defined types) are not supported for synchronization.
Much more extensive samples are available at the Sync Framework Developer Center.

Sample 5 - Basic Synchronization with Microsoft Sync Framework 2.1
One point to note with Microsoft Sync is that the technology creates/adds some tracking tables to your databases in SQL Database as part of its synchronization and this eats into the database space usage of SQL Database. So you should test your scenario before deciding this approach.
Synching Data between Different Azure Sites
With databases deployed in remote data centers, a natural question, especially for enterprise customers, will be how to perform geo-replication of data across distinct data centers. Key motivations for this include disaster tolerance and placing data closer to users in different regions. With SQL Database the story is based on the Microsoft Sync Framework.
Fundamentally, the Sync Framework can synchronize between two Azure-hosted databases, wherever they are, in exactly the same way it works between an on-premise and an Azure database. The only difference is the connection strings. There are three potential approaches to doing this. They are distinguished only by how and where the code which uses Sync Framework is hosted.
- Synchronization code can be hosted on-premise and invoked by a scheduler or some business or operational event. The code shown previously in Sample 5, for example, will work just fine if both connection strings point to Azure databases, each in a different Azure data center.
- The synchronization code can be packaged by you for deployment to a Windows Azure worker role. Residing there, it can run as needed to sync two Azure databases.
- CTP 1 of “SQL Data Sync” (http://www.sqlazurelabs.com/) can be used to build and schedule synchronization. Under the covers, this preview tool generates a synchronization package that uses the Microsoft Sync Framework and runs it in Windows Azure.
In the latter half of 2011 SQL Data Sync will become generally available with the features that were released in CTP1 and CTP2, i.e synchronizing between SQL Databases and synchronizing between SQL Database and on-premises databases.
Handling Azure-specific Error Conditions in Application Code
Most SQL error handling practices are no different with SQL Database as compared to on-premise SQL Server. There are a few error conditions, however, which are unique to SQL Database.
Throttling: As a multi-tenant data platform service, SQL Database has safeguards in place to prevent runaway resource usage, which would affect other users. In the case of excessive usage of CPU, memory, tempdb, transaction log, or IO, SQL Database will “throttle” the offending connection by throwing error 40501 and terminating the connection. The text of the error message will include a reason code that can be parsed to determine the throttled resource.
Connection Termination: SQL Database may also terminate a connection with other error codes due to extended inactivity, long-running transactions, etc.
Database size limits: if a database reaches its maximum configured size, any operation which will add more data fail with error 40544. You can resolve this error by reducing the amount of data in the database or using the ALTER DATABASE statement to increase the maximum size (up to the service maximum of 150GB). Bear in mind that growing the database into the next size tier will increase the daily cost of that database.
Since many of these Azure-specific error conditions may result in connection termination, custom code which uses SQL Database should implement a connection retry mechanism in its exception handling code.
For a complete error code reference, see Error Messages (SQL Database) in the online documentation.
Capturing the Trace Identifier
To aid in troubleshooting and support, SQL Database assigns a session trace id for every connection. This id is a GUID, and can be retrieved using the Transact-SQL CONTEXT_INFO() function. For example:
SELECT CONVERT(NVARCHAR(36), CONTEXT_INFO())
Besides usefulness in your own debugging, this id can also be provided to Microsoft customer support to help track down problems. It is a good idea to capture this as a matter of course in your custom data access code.
CONTEXT_INFO can also be read from the sys.dm_exec_sessions and sys.dm_exec_requests DMVs, which can allow visibility of the trace id for other active sessions.
Exposing SQL Database Data for Web Service Consumers
The relational database engine provided by SQL Database is a great tool for storing, querying, and managing data in the cloud. A SQL TDS connection may not, however, be the ideal connectivity model for expected consumers of your data. For many scenarios, web service is a better way to expose data to its consumers, even if the data is stored in SQL Database. Usually, Windows Azure is the best host for the web services code itself.
Any form of .NET based web service – WCF or ASMX – can be hosted in a Windows Azure web role to serve as an access point for SQL Database data. Besides providing a flexible protocol (i.e., HTTP vs. TDS) this can also provide more authentication options than just SQL logins with username/password.
Open Data Protocol (OData) is an especially interesting option for web service access to SQL Database data. OData is a standards-based protocol for querying and updating data. OData is supported in the .NET Framework through WCF Data Services and is easily consumed by .NET Framework code, Silverlight, Javascript, PHP, and Objective-C, among others.
As this blog entry illustrates, it is a simple matter to hang an OData service in front of SQL Database data. Keep in mind that if the Windows Azure web role is hosted in the same data center as the SQL Database, bandwidth between the two components is free of charge (see the session Data Transfers).
Another, even easier way to put an OData face on your SQL Database data is with the pre-release SQL Database OData Service at SQL Database Labs.
Server Management Objects (SMO)
Server Management Objects (as of SQL Server 2008 R2) is partially enabled for use with SQL Database. Guidance from the product team is that SMO is not currently intended for use by applications. Rather, it has the limited support necessary to manage SQL Database through SSMS 2008 R2.
SMO can be used for basic interrogation, management, and scripting of SQL Databases. Keep in mind, though, that there are limitations on SMO support for SQL Database.
For additional info see the section on SMO at Tools and Utilities Support (SQL Database) in the online documentation.
Deploying
The fact that SQL Database resides ‘in the cloud’ in a Microsoft data center naturally changes some of the techniques and considerations for deploying and securing databases. This section addresses deployment and security for SQL Databases.
Security
Firewall Configuration
After a server is created in SQL Database, that server is, by default, not accessible for any external connections. One or more firewall rules must be configured to allow outside connection to the server’s databases.
A firewall rule consists of a rule name and an IP address range. The range can cover multiple addresses (e.g., 71.178.20.1 - 71.178.20.255) or just a single address (e.g., 71.178.20.32 - 71.178.20.32). Rules can be added via the Windows Azure Management Portal or with stored procedures. Note that, currently, the first rule must be added from the portal, since the ability of a program to access SQL Database and invoke the stored procedures presupposes access through the firewall.
To add a rule using the management portal, select the server for the subscription of interest and locate the Firewall Rules button in the server information section of the central pane (see Figure 8).
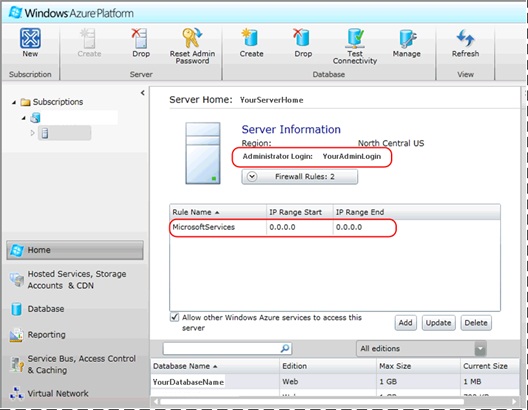
Figure 8 - Firewall Rule Management in the Windows Azure Management Portal
Click the button to expand the firewall rules table and click the Add button. The Add Firewall Rule dialog, shown in Figure 9, will pop up. Provide a name and the start and end IP addresses for the range which will be allowed to access the server. Click OK and the rule will be created.
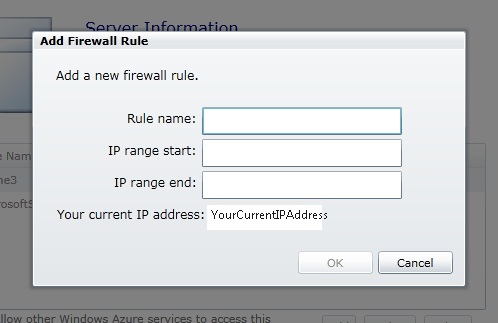
Figure 9 - Defining a Firewall Rule
The rule may take a few minutes to become effective on the Internet facing Azure firewalls.
Firewall rules may also be added, changed, or deleted with T-SQL using the system stored procedures sp_set_firewall_rule and sp_delete_firewall_rule. For example, the following command would create a firewall rule for a certain range of addresses:
exec sp_set_firewall_rule 'PhoenixOffice', '123.123.123.1', '123.123.123.128'
Note that access to your SQL Database server from other Windows Azure services – code in a Windows Azure web role, for example – is also disallowed by default. To allow access from within Windows Azure, you can check the box labeled “Allow other Windows Azure services to access this server” on the management portal (see Figure 8) or add a rule with an IP address range of 0.0.0.0 – 0.0.0.0
exec sp_set_firewall_rule 'Windows Azure', '0.0.0.0', '0.0.0.0'
Authentication and Authorization
Unlike on-premise SQL Server, SQL Database does not support Windows authentication. Traditional SQL authentication based on username and password is the only supported authentication type. This due to the fact the SQL Database servers are in the cloud with no trust relationship to a specific AD forest’s domain controllers.
Nevertheless, dependence on SQL authentication can be inconvenient in some scenarios. You may wish to explore some type of username/password broker component in your solution that leverages AD single-sign-on to provide a client with SQL Database username and password. For multi-organizational solutions, Windows Azure AppFabric as a federated identity authority might be useful. In such a scenario, authentication against AppFabric may be used to get access to login credentials for SQL Database.
Server Level Roles.
SQL Database does not have the fixed server roles found in on-premise SQL Server. Instead, there are two special database roles present in the master database which impart special administrative permissions.
| Role Name | Description |
| dbmanager | Provides permission for creating and managing databases. Equivalent to the on-premise SQL Server dbcreator server role. |
| loginmanager | Provides permission for creating and managing logins. Equivalent to the on-premise SQL Server securityadmin server role. |
Note that there is no sysadmin role. The closest equivalent to this role in SQL Database is the “server level principal login”, which is analogous to sa in on-premise SQL Server. This principal is set up when the SQL Database account is provisioned.
Database Level Roles
The fixed database roles in SQL Database are identical to those in on-premise SQL Server.
Discretionary Access Control
Within an individual database, the discretionary access control model for GRANT-ing (or DENY-ing) specific permissions on objects or statements is essentially the same as it is in on-premise SQL Server.
Defining and Securing Connection Strings
Connecting to SQL Database from ADO.NET, ODBC, or PHP requires the standard connection string format used by the respective library. There are a few fine points to constructing a connection string for SQL Database, however. Depending on the configuration on the client machine and the tools used, it may not always be required to adhere to all of them – but, it will not hurt.
| Attribute | Recommendation |
| Server Name | · Use the fully-qualified name of your SQL Database server. For example: servername.database.windows.net · Prepend the server name with “tcp:” to ensure use of the TCP/IP sockets net library · Only port 1433 is supported for SQL Database access. To ensure this port is used, append “,1433” to the server name.A full example might be: tcp:servername.database.windows.net,1433 |
| Database | If this is not specified, a connection will be made to the master database. To get a specific database, provide the database name. Keep in mind that the ‘use’ keyword is not supported by SQL Database for switching database context after the connection is established. |
| User Id | Because of differences in how some tools implement TDS, it may be necessary to append @servername to the user id. For example, if the user id is ‘johnsmith’, the value used in the connection string would be ‘johnsmith@servername’. |
| TrustServerCertificate | Include this attribute in the connection string, with a value of ‘False’. |
| Encrypt | Include this attribute in the connection string, with a value of ‘True’. |
The Windows Azure Management Portal provides a handy method to get a proper connection string for connecting to your SQL Database. From within the portal, select SQL Database (the Database icon in the left-hand pane) and highlight the database for which you need a connection string. The Properties viewer in the right-hand pane (see Figure 10) will include an item for “Connection Strings.” Click the ellipsis button and a pop-up will provide fully formed connection strings for ADO.NET, ODBC, and PHP.
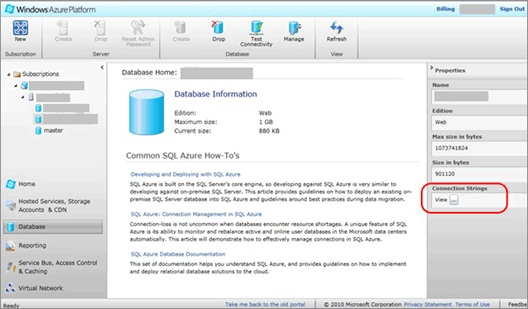
Figure 10 – Connection Strings Provided by the Management Portal
As with any use of SQL Server, connection string details should always be managed securely. The connections string or it constituent details should be secured so that only authorized principals may access it. Where feasible, encryption should also be used to protect the connection string information.
Auditing Access
Options for auditing access to SQL Databases are currently limited. Successful and/or failed logins cannot be audited. The SQL Server Audit feature is not supported. Also, SQL Trace is not supported by SQL Database.
Standard DML triggers on tables (i.e., INSERT, UPDATE, DELETE triggers) are supported and can be used to track changes to data. Also, a subset of server and database DDL triggers are supported. These also can be used to audit certain administrative or application actions.
Managing passwords
If it becomes necessary to change the password for an existing login, the only currently supported method is T-SQL. The syntax to change the password for an existing login is as follows:
ALTER LOGIN login_name WTH PASSWORD =
new_password
This command can only be executed within the master database.
Scripting an On-Premise Database for Deployment to SQL Database
In many cases the development of a solution will be done with on-premise SQL Server, prior to production deployment to SQL Database. Or, an existing solution may need to be ported from on-premise SQL to SQL Database. Moving the schema and code to SQL Database can be accomplished by scripting the database with SQL Server Management Studio 2008 R2 (SSMS).
Special care, however, is required to ensure the script will work on SQL Database. Since there are small differences in the T-SQL syntax supported by SQL Database and on-premise SQL Server, SSMS must be told to generate a script which is compatible with SQL Database.
As shown in Figure 11, this is done from the Set Scripting Options page in the SSMS Generate Scripts wizard. On that page, click the Advanced button to display the Advanced Scripting Options dialog box. On this dialog, set the “Script for the database engine type” option to “SQL Database”. Note that this option is only available in the R2 version of SQL Server 2008 Management Studio.
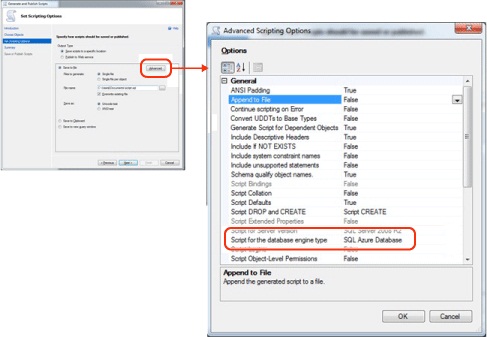
Figure 11 - Selecting SQL Database as the Engine Type to Script For
You can also use the Generate Scripts wizard to script data to be loaded into your SQL Database. Also in the Advanced Scripting Options dialog is an option named “Types of data to script” (Figure 12).
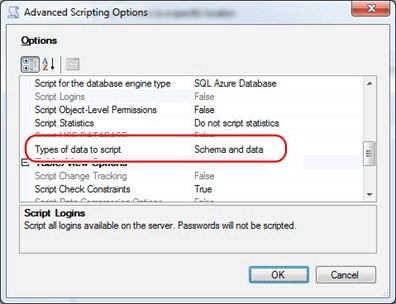
Figure 12 - Scripting Schema and Data for Transfer to SQL Database
If this option is set to “Schema and data”, SSMS will include INSERT statements for all records in the generated script. While this is handy for smaller databases, it becomes inefficient and unwieldy for large databases. For large databases, it is usually better to use the options described in the following section “Moving Data into SQL Database”.
Moving Data into SQL Database
It is often necessary to load large amounts of data into a SQL Database, for example during the initial deployment of a database with initialization data.
SQL Database supports the following tools for efficient data loading into a SQL Database:
- The Bulk Copy tool (bcp.exe)
- SQL Server Integration Services (SSIS)
- Custom code using the ADO.NET SqlBulkCopy API
- Import Export Service or Import Export Client tools
One of these options is usually the best choice for loading significant amounts of data into SQL Database from an on-premise source. Good information on best practices for using these tools with SQL Database can be found in the following blogs and articles:
Finally, a good end-to-end demonstration of using these techniques can be found at the following link:
Import Export can be used as a client side tool, or as a cloud service. There are open source samples showing how to perform both on premise to cloud, and cloud back to on premise.
Migrating Access 2010 Databases with SQL Server Migration Assistant
The SQL Server Migration Assistant 4.2 was updated in 2010 to support migration of Microsoft Access databases (version 97 or later) to SQL Database, as well as to on-premise SQL Server 2008. This tool has a migration wizard for transferring the structure and data from a local Access database to an existing SQL Database. For Access objects which cannot be directly migrated (for example, certain kinds of Queries) SSMA produces a report detailing the items which require manual attention.
SSMA 2008 for Access 4.2 is a tool for performing migrations of the data store from small departmental applications to SQL Database. It can be downloaded here. Note that only the SSMA 2008 installer includes support for SQL Database.
A clear and simple, end-to-end walkthrough of using SSMA 22008 for Access with SQL Database can be found at this link: Migrating Microsoft Access Applications to SQL Database.
Also, note that there is another version of SSMA 2008 aimed at MySQL, which can be used for migration from MySQL databases to SQL Database. It can be downloaded here.
Using Data Tier Applications (DAC) with SQL Database
Data Tier Applications (“DAC” for short) are a construct introduced in SQL Server 2008 R2, with developer tool support in Visual Studio 2010. They are useful for packaging the schema, code, and configuration requirements of a database for deployment to another server (for example, a staging or production server).
The Azure SQL Import Export service uses DAC technology to build the artifact for moving data and schema to the cloud. The extension is .BACPAC for data + schema.
Maintenance and Operations
Once your SQL Database is in production, there are certain tasks required for ongoing maintenance. As discussed in the Planning section of this document, SQL Database inherently eliminates a broad swath of traditional maintenance issues. However, there are some standard tasks, like index and statistics maintenance, that apply in SQL Database just as in on-premise SQL Server. Other typical tasks still apply must be handled differently.
In some cases, entirely new aspects of maintenance or operations come into play with SQL Database. Tracking usage and billing using Azure DMV’s is one example.
Backing up SQL Database Data
For the latest information on SQL Database backup and restore strategy and disaster recovery techniques, see Business Continuity in Windows Azure SQL Database article in the Windows Azure SQL Database MSDN library.
Native backup and restore as provided by on-premise SQL Server is not currently supported by SQL Database. This is however on the roadmap and a preview of this feature is expected by middle of calendar year 2011.
The Azure SQL Database Import Export service allows you to make a complete copy of your database and place it into your blob storage. This service is provided at no additional cost to customers. You do have to pay for the storage used in your storage account.
Database Copy
SQL Database natively supports a Database Copy capability. This creates a new database in SQL Database which is a transactionally consistent copy of an existing database. This is accomplished using special syntax within the CREATE DATABASE command:
CREATE DATABASE destination_database_name AS COPY OF
[source_server_name.]source_database_name
As the optional server name in the syntax implies, this can be used to create a copy of a database on the same server, or on a new server. The new server can be owned by another Azure account, but for the copy to work some special rules must be adhered to (see the documentation, referenced below).
The user executing this statement must be in the dbmanager role on the target server (to create a new database) and must be db owner in the source database.
For full discussion of this feature, see Copying Databases in Windows Azure SQL Database.
Other Tools
The data in a SQL Database can be backed up on-premise, or to another SQL Database, using BCP, SSIS, or the .NET SqlBulkCopy API. Obviously, these approaches do not backup the structure and objects in the database, so you will need to generate build scripts to accompany the data if you wish to bootstrap the database into a new environment.
For a thorough discussion of the options for moving data in bulk out of (or into) a SQL Database, see this blog post from Microsoft SQL Customer Advisory Team, and this this discussion of BCP specifically.
Defragmenting Indexes and Other Routine Maintenance
In SQL Database, as with on-premise SQL Server, indexes can become fragmented over time. They should be periodically checked and, if necessary, rebuilt. The syntax for the ALTER INDEX statement is restricted in SQL Database, as compared to on-premise SQL Server, but the syntax for rebuilding indexes is identical. Reorganizing indexes is not supported by SQL Database.
Both online and offline index rebuilds are supported by SQL Database.
Another routine maintenance task in SQL Server is keeping statistics current. There are no significant differences in statistics management between SQL Database and on-premise SQL Server. The following are supported:
- UPDATE STATISTICS
- sp_updatestats
- sp_autostats
The ALTER DATABASE statement, however, cannot be used to change the database-level settings automatic statistics creation and updating. These settings both default to True (ON) for SQL Databases and they cannot be changed. If you truly find it necessary to suppress auto stats updates, use the sp_autostats stored procedure to control this behavior at the table/index level. In the vast majority of circumstances, you can just leave the auto update behavior unchanged.
Tracking Usage and Billing
Depending on the subscription model used by your customer, SQL Database may be billed on a consumption basis. This makes it valuable to track consumption of bandwidth and space on an ongoing basis. Although there are reports within the Azure billing portal which help track this, customers often wish to do some kind of customized tracking of usage expense. SQL Database provides DMV’s to enable this.
Bandwidth usage from your SQL Database account is available in a DMV called sys.bandwidth_usage. This DMV is only available in the master database. Since three-part names are invalid in SQL Database, you will need to be connected to the master database to query the sys.bandwidth_usage view. An example of the resultset returned by this view is shown below in figure 13. The quantity column is in kilobytes.
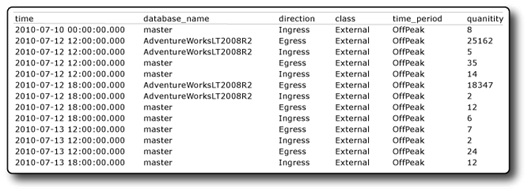
Figure 13 – Result set from sys.bandwidth_usage. Quantity column in KB
Database usage is available in a DMV called sys.database_usage. This DMV is also available only in the master database. An example result set is shown in Figure 14.
Note that the quantity here is rolled up across databases. For example, in the sample listing below, the quantity of 1 was reported for one 1GB database. The quantity of 2 is reported for a two 2GB databases. If, on a certain day there was one 5GB database in use, the DMV would report a quantity of 5.

Figure 14 - Result set from sys.database_usage
These bandwidth_usage and database_usage DMV’s are helpful, but they only report past usage. You may want to use T-SQL to check the size of a SQL Database as it is right now. Unfortunately, the sp_spaceused stored procedure is not available in SQL Database. Also, sys.database_files is among those DMV’s not exposed by SQL Database. Another DMV, sys.dm_db_partition_stats, can help here though. The following T-SQL query will report the approximate size of the database.
SELECT (8.0 * SUM(reserved_page_count)) / 1024 AS 'Database Size (MB)'FROM
sys.dm_db_partition_stats
This query reports on the current database only, so you will need to run it while connected to the specific database you are interested in. Note that permission on sys.dm_db_partition_stats is denied in the master database, even for administrators.
Monitoring Windows Azure Service Availability
Server and database level monitoring capability is not currently exposed by SQL Database. Status at the data center level is available, however, for SQL Database and all other Windows Azure services. To monitor data center availability and status, visit the Windows Azure Platform Service Dashboard. At this link, you can also subscribe to RSS feed for specific services and data centers of interest to you.
Blocking Analysis
A common need in production SQL Server systems is finding the root cause of blocking problems. In SQL Database some of the familiar tools for doing this – sp_who2, SSMS Activity Monitor – are not available. The DMVs exposed by SQL Database can, however, help fill this need.
This blog entry demonstrates a DMV query for identifying blocked/blocking processes.
This whitepaper discusses the available DMVs for performance for troubleshooting.
Also see Monitoring Windows Azure SQL Database Using Dynamic Management Views.
Scheduling Maintenance Tasks
Scheduling maintenance (e.g., index reorganization) will sometimes be required, especially for large or heavily accessed SQL Databases. Unfortunately, SQL Server Agent, the on-premise SQL Server scheduling engine, is not part of SQL Database. This means there is no Azure-hosted method for scheduling tasks to occur.
For the time being, the only way to address this requirement is with an on-premise or non-Azure scheduling tool. A natural choice is, of course, an on-premise instance of SQL Server Agent. This works perfectly well and will make SQL Server DBA’s comfortable.
Using on-premise SQL Agent is OK for customers with existing SQL Server infrastructure. Those with no existing SQL licenses, however, may wish to avoid buying database software just to get a scheduling engine. In this case, Windows Task Scheduler can be used to invoke sqlcmd scripts, Powershell scripts, or custom executables which reach out to SQL Databases to perform maintenance tasks.
Finally, there is no reason third-party task scheduling cannot be used, if the customer already has it and is comfortable with it.
A References section with links to SQL Database MSDN, SQL Database team blogs, customer case studies is a good way to end the WP.
Other Languages
This article is also available in other languages, including Russian.
Wiki: Руководство по доставке Windows Azure SQL Database