Hive in Microsoft Azure HDInsight
In this article prerequisite you need is active azure account and you can try out this article steps, first you need to provision azure storage account and HDinsight cluster. Create a HDInsight cluster using the storage account created before. In Hadoop compute cluster is also the storage cluster. So create the HDInsight cluster in the same region as the Storage Account. Select the cluster and click Manage Cluster icon locate at the bottom of the page, This will bring up the Hive Page from where you can issue HiveQL statements as jobs.
Copy and paste the following HiveQL DDL statement in the text area and click submit. This will create a Hive database called suketudemo and a Hive table called incident_by_premise_type
CREATE DATABASE IF NOT EXISTS suketudemo LOCATION '/hive/warehouse' ;
CREATE TABLE IF NOT EXISTS bocsar.incident_by_premise_type(
incident_year INT,
division STRING,
incident STRING,
premise_type STRING,
incident_count INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '01';
The job status refreshes every 30s and changes from Queued, Running and Succeeded

For this article I am loading data to Hive tables using text files with columns delimited by ctrl-A which is “/001” or char (1). I used SSIS script task to convert data published by author into ctrl-A delimited text files. The Hive data files have to be copied to Azure Storage Account from your local drive. I am using Azure Storage Explorer to upload the text files. Azure Storage Explorer can be downloaded from here.
Follow these instructions to configure Azure Storage Explorer and upload the text files. Once you have added your storage account to Azure Storage Explorer, select the HDInsight Cluster then click Blobs followed by Upload button and select the three text files. Once the files are uploaded they are available at the Home directory of Azure Storage Account. You can verify this from the Hive File Browser page.
Navigate to Hive Editor and run the following Hive statements to populate the Hive table – suketudemo.incident_by_premise_type
LOAD DATA INPATH '/Arson_Sydney_TressPass_Data_By_PremiseType.txt' INTO TABLE suketudemo.incident_by_premise_type;
LOAD DATA INPATH '/TransportOffence_Sydney_Data_By_PremiseType.txt' INTO TABLE suketudemo.incident_by_premise_type;
LOAD DATA INPATH '/Tresspass_Sydney_Data_By_PremiseType.txt' INTO TABLE suketudemo.incident_by_premise_type;
Once the job is successful, you will notice that the text files have been moved from the home directory to \hive\warehouse\ incident_by_premise_type
Now that the hive table is populated, it can be queried by submitting HiveQL DML jobs
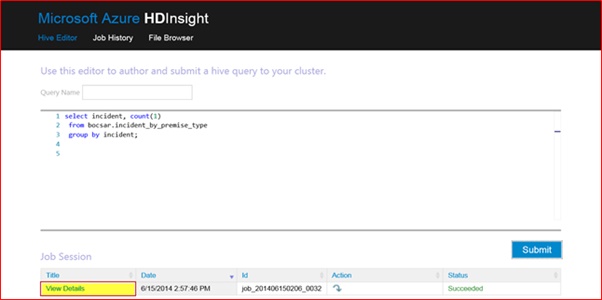
select incident, count(1)
from bocsar.incident_by_premise_type
group by incident;
Click View Details to see the query result.