Create your own web scraper using Node.js and get data in JSON format
Want to make you own scraper to scrape any data form any website and return it in JSON format so you can used it anywhere you like? If yes, then you are at right place.
In this article I will guide you how to scrape any website to get desired data using Node.js and to obtain the data in JSON format which can be used e.g. make any app which will run on live data from the internet.
I will be using Windows 10 x64 and VS 2015 for this article and will scrape from a news website i.e.
First of all set up the IDE, go to https://nodejs.org/en/download/ and download the Nnode.js pre build installer. For me it will be windows installer 64-bit.
https://3.bp.blogspot.com/-ooBWOiDDBi8/VmQKh0qnI_I/AAAAAAAAASE/8rRnduYPThc/s640/Node1.JPG
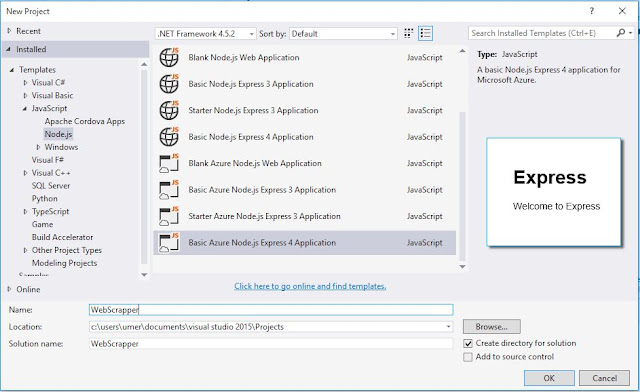
After installing it, open your Visual Studio and create a new project Templates>JavaScript>Node.js>Basic Node.js Express 4 Application
https://4.bp.blogspot.com/-fkED18bttfo/VmQKiNiHxuI/AAAAAAAAASQ/B4j5IsnzBEw/s640/Node2.JPG
Now I have to add two packages in npm folder, i.e. ‘Request’ and ‘Cheerio’.
https://3.bp.blogspot.com/-c2bMSlwT3OQ/VmQKjx47t5I/AAAAAAAAATA/uzvq-EigD-0/s640/Node3.gif
And uninstall ‘Jade’ by doing a right click as we don’t need it now and I have to host my JSON to Azure cloud service so Jade gives an exception. If you want to consume JSON directly in your application or hosting using other service than you don’t have to uninstall Jade.
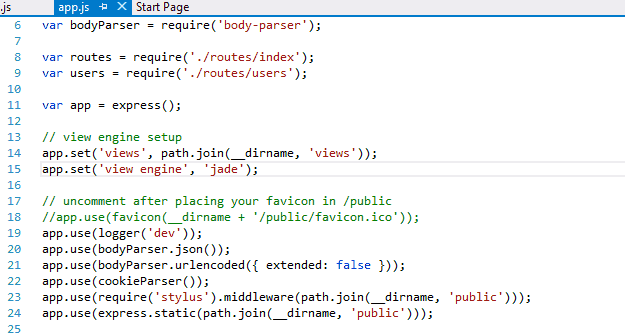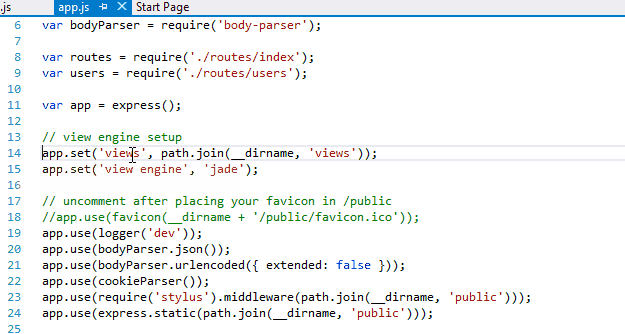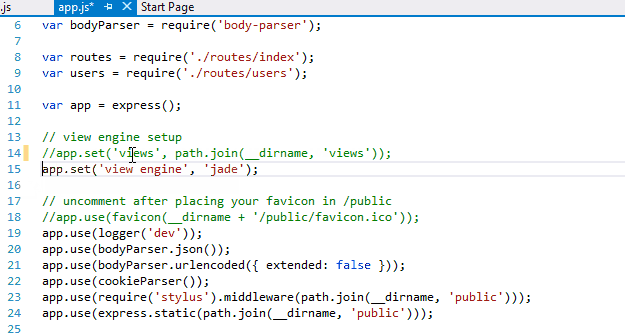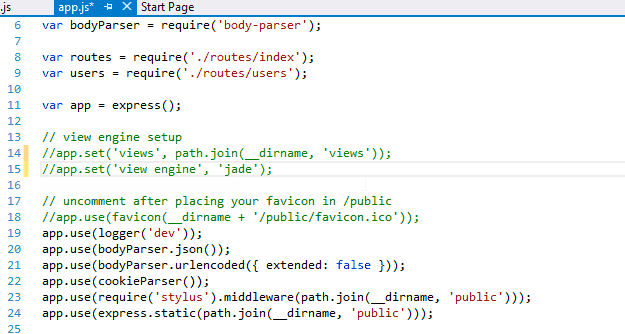
Now go to app.js and comment out the line numbers 14 and 15 as we are not using ‘Views’
https://4.bp.blogspot.com/-4EvzYw1yu0Q/VmQKlao_NSI/AAAAAAAAAS8/-H9IUXd3X1I/s640/node4.gif
Also comment out ‘app.use('/', routes);’
Change app.use('/users', users); to app.use('/', users);
Now go to users.js as now we will do the main thing here. First of all add the files ‘cheerio’ and ‘request’.
https://4.bp.blogspot.com/-LU96r6AX05k/VmQKllKTE9I/AAAAAAAAATE/RrOl8u_M4Ho/s640/node5.gif
Create a variable to save the URL of the link:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
var url = "http://www.thenews.com.pk/CitySubIndex.aspx?ID=14";
- Modify the router.get() function as following:
router.get ('/', function (req, res) {
request (url, function (error, response, body) {
if (!error && response.statusCode === 200) {
var data = scrapeDataFromHtml(body);
res.send(data);
}
return console.log(error);
});
});
https://2.bp.blogspot.com/-OYxZo1mabII/VmQKlyzykDI/AAAAAAAAATI/PeHXsfstPZ4/s640/node6.gif
{kind=link}
{kind=link}
Here comes the main and difficult part. Now we have to write the main logic of scraping our website. You have to customize your function according to your website and the data you want to fetch. Let’s open the website in browser and develop the logic for it.
https://1.bp.blogspot.com/-NIAhSbe6KvM/VmQKzBFOEwI/AAAAAAAAATg/AoC4BNVviXY/s640/node7.gif
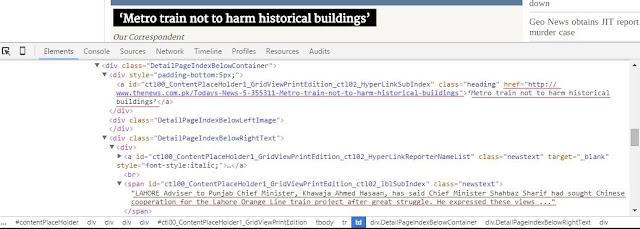
I want to scrape out the following data, news headline, its description and the link to open the detail of the news. This data is changed dynamically and want to fetch the latest data
https://4.bp.blogspot.com/-dphZbFXf34o/VmQKn1jVddI/AAAAAAAAATQ/xKvM3xha-U0/s640/node8.JPG
To fetch this data I have to study its DOM so I can write its JQuery to fetch it easily.
https://2.bp.blogspot.com/-GQMZGUv6pFo/VmQKrjWq_rI/AAAAAAAAATY/ZYCMOkdQceI/s640/node9.JPG
I made a DOM tree so I can the write the logic to traverse it easily
https://1.bp.blogspot.com/-5gJly90CgVQ/VmQKkb_qoBI/AAAAAAAAASk/oPCXsT69akg/s640/node10.JPG
The text in red are the nodes I have to reach in a loop to access the data from the website
https://2.bp.blogspot.com/-2q2jSZd-GRs/VmQKkAlxKOI/AAAAAAAAASg/O2JQIrITkF8/s640/node11.JPG
I will write a function named as scrapedatafromthtml as following:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
var scrapeDataFromHtml = function (html) {
var data = {};
var $ = cheerio.load(html);
var j = 1;
$('div.DetailPageIndexBelowContainer').each(function () {
var a = $(this);
var fullNewsLink = a.children().children().attr("href");
var headline = a.children().first().text().trim();
var description = a.children().children().children().last().text();
var metadata = {
headline: headline,
description: description,
fullNewsLink : fullNewsLink
};
data[j] = metadata;
j++;
});
return data;
};
This function will reach the ‘div’ using the class ‘.DetailPageIndexBelowContainer’ and will iterate its DOM to fetch the ‘fullNewsLink’, ‘headline’ and ‘description’. Then it will add these values in the array called ‘metadata’. I have another array called ‘data’ and will come the values from metadata on each iteration so in the end I can return my ‘data’ array as JSON. If you only want one thing form a website you don’t need to have loop for it or to create you other array. You can directly access them by traversing it and return the single array.
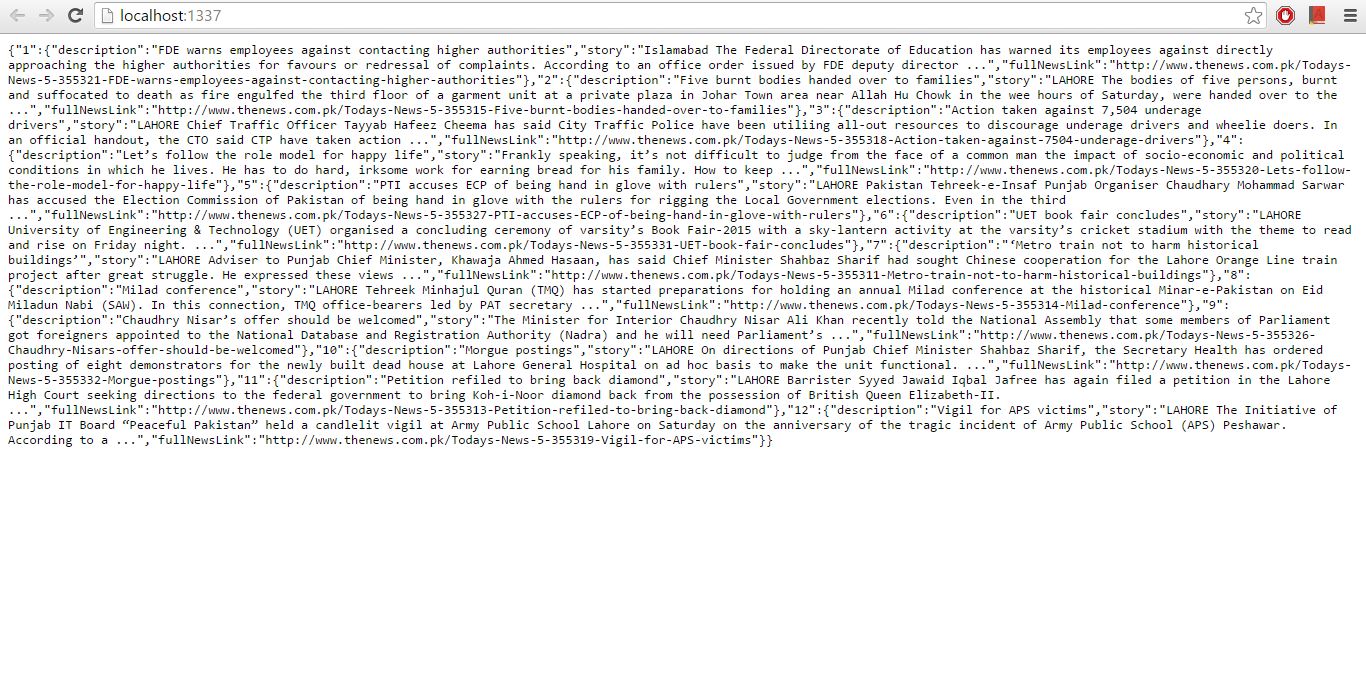
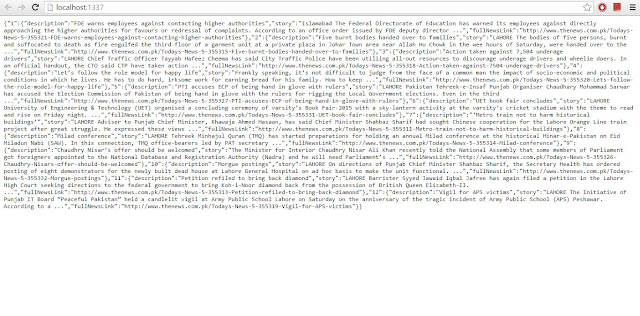
Now run it and check the output
https://4.bp.blogspot.com/-XPhdStWXmxE/VmQKlA-xrfI/AAAAAAAAAS0/apTW4v-8UZ8/s640/node12.JPG
{kind=link}
{kind=link}
And yes! It’s running perfectly and returning you the required data in JSON format.
PS: If the site that i am using as an example, removes the page, changes the layout, changes the css files or their names etc then we would not get the desired result. For that you have to write the new logic. but i have explained the logic and how to traverse the DOM tree of any website.
Source Code: https://github.com/umerqureshi93/webscrapper