Durable Task Framework – Episode II: Clustered Singletons, Failover and Competing Consumer
Introduction
When implementing services, you will at least on Windows typically implement the service und run it in Service Control Manager (SCM). Another option would be implement a job, which will be scheduled by System Task Scheduler, which is built in the operative system. However if the program has to run for long time (it is a service), you will most likely implement it as Windows Service.
Microsoft had also a great option of WCF service, which can act as services if you use AppFabric. Unfortunately AppFabric is in longer term deprecated.
Steps
Anyhow, we can still use today SCM. But there is one problem with SCM or any other similar kind of host. If your service is designed to run as a singleton, it means there must be a single running instance of the service only. Unfortunately when this instance crashes, there is no failover mechanism. To make failover possible, you can start second instance of the service in parallel. But in this case both instances have to somehow talk to each other to coordinate their work. This is sometimes a more complicated task then the implementation of the business logic itself.
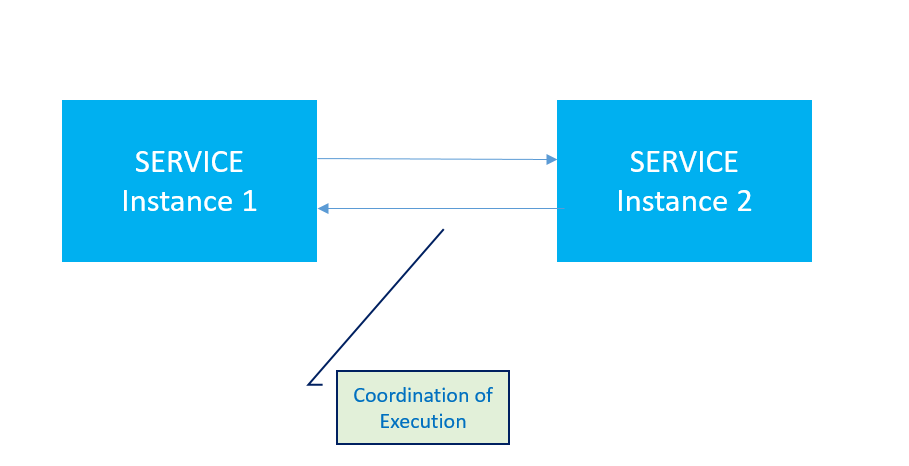
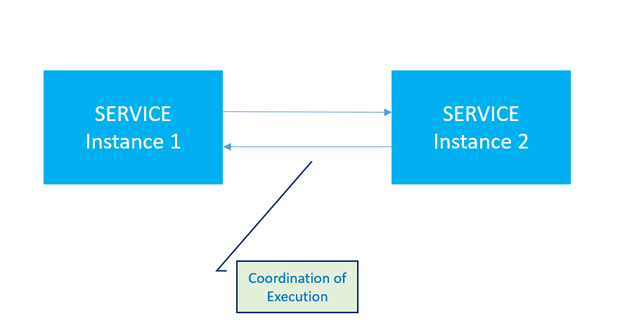
Following picture shows simplified bidirectional communication between instances.
http://developers.de/cfs-file.ashx/__key/CommunityServer.Blogs.Components.WeblogFiles/damir_5F00_dobric/image_5F00_thumb_5F00_2747268F.png
{kind=link}
{kind=link}
Once you start implement such behaviors you are in the space of parallel computing, which is far more complex that typical kind of software, which we broadly used in industry.
To make things easier most developers decided in such cases to run a single instance of the service only and hoped to avoid the crash. That means if the first instance fails, there is no second one, which can automatically continue execution. In that case failover is done by human interaction (administrator). As long we have human resources available for this task and SLA are far behind cloud standards with >99.00% uptime, this is more or less a practicable and cost saving execution.
Solution
The correct solution for this scenario would be to provide a Failover of the Singleton Service, which is logically running as a single instance (singleton) and physically as many instances (>1) .
In that case we have two options:
Failover
We can run both instances of the service, but only one is executing actively. We call this typically Active-Passive cluster. If that one fails for any reason the second one will continue execution by using of failover (passive) instance. This can be done by human interaction or it can be automated. If you want to automate it, you will figure out that this is not an easy task.
Competing Consumer
We can start multiple instances of the service physically and scale out execution horizontally. In this case the service is no more a singleton, because every instance will have its own state. Usually we use singleton to ensure a single state. To make it a singleton, you have to implement some kind distributed variables, which are synchronized. Most developers in such cases use database. That is easy solution for this problem, but it does not scale well, due many database locks.
To implement such scenarios we typically use some kind of messaging system. This could be for example Azure Service Bus or any other message system like IBM MQ or similar. We will in usually provision the queue and running service instances of the service would “compete” for message. Because of that, we call such patterns “Competing Consumer”. For every message in the queue one service would receive it and perform any kind of job on the message.
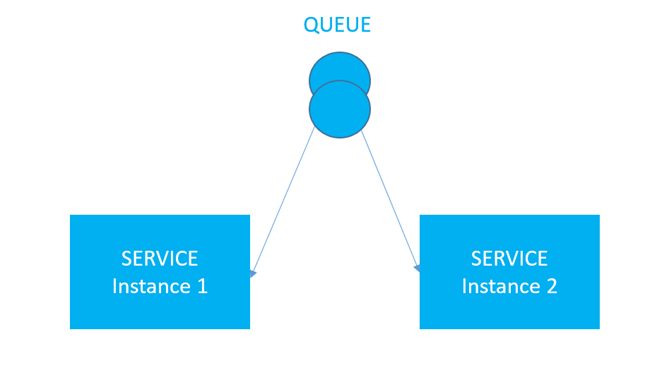
Following picture shows two physically running instances of a single logical singleton service.
http://developers.de/cfs-file.ashx/__key/CommunityServer.Blogs.Components.WeblogFiles/damir_5F00_dobric/image_5F00_thumb_5F00_26DAF39A.png
{kind=link}
{kind=link}
If we now stop one instance, only one remaining instance will continue execution, If that one crashes we can simply start the second one by human interaction or automatically. As you see by using of “Competing Consumer” pattern we can achieve a special case called “Failover”. We call this sometimes On-Off pattern, which is mostly used for system maintenance.
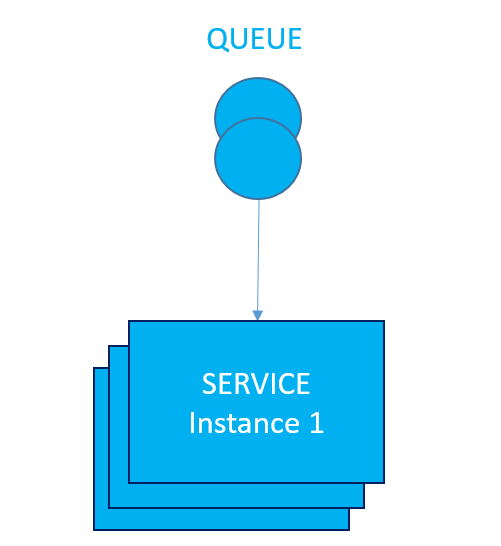
Even better, to make more of Competing Consumer pattern we can theoretically run as many instances of the service as we want. In that case, we do not talk anymore about failover. We rather talk about load balancing, which by default provides failover, over multiple (not only two) instances of the service. Following picture shows a clustered singleton service with queue load balancing.
http://developers.de/cfs-file.ashx/__key/CommunityServer.Blogs.Components.WeblogFiles/damir_5F00_dobric/image_5F00_thumb_5F00_3B604318.png
{kind=link}
{kind=link}
As you have probable noticed, queue can be used to realize a pattern “Competing Consumer”, which can be used for failover, load balancing or both. Queue is in this case used for scheduling of execution of any of running instances. Even if there is no running instance, queue will keep messages until first instance goes online.
As you see, implementation of singleton in cluster is very complicate task. Interestingly, this requirement is not new one, but we never had an easy-way to implement it. If you remember WCF singleton behavior, makes your SOAP service singleton, but on one node only. Friends of REST and WebApi usually do not think about such issues, because scenarios behind REST are typically not Long-Running task and they are usually executed in Request-Response manner. To implement a true singleton in cluster (running on multiple nodes) we will have to implement synchronization between states shared across multiple instances. This is pretty complex task. For this reason Microsoft shipped Service Fabric, which exactly targets this issues.
Operative system does not offer such building blocks at that high-level at all. With more and more popular cloud solutions we are starting to think about such scenarios more often and they are truly becoming a reality of all developers and not only integration guys.
Recap
In this article we described the how complicate might be to implement a service which has failover and can scale well. In fact operative system does not offer such building blocks at that high-level. This is why many products when running in cluster are typically very complex to implement and to maintain. But we also described how easy is in some point to achieve most of described requirements by using of a messaging system like Azure Service Bus.
But one thing is still open. To implement a true singleton in cluster (running on multiple nodes) we will have to implement synchronization between states shared across multiple instances. This is pretty complex task. For this reason Microsoft shipped Service Fabric, which exactly targets this issues.
See also
Episode I
The Problem of robust execution
Episode II
Clustered Singletones, Failover and Competing Consumer