An app that reads out text for you
Download: To download the source code for this article's application, you can go to this MSDN gallery page.
Introduction
In this article, I would show you how to create an application in WPF that makes a good use of Speech APIs in .NET framework to generate spoken responses for the written messages that we provide it with. Also, as a bonus, I would show how to change the voices and the rate of their speaking.
Today was my last day in Bachelor for Computer Science programme, yesterday I was thinking that I should try my luck in some sort of literature or something like that, but there was only one thing on my mind... How am I going to read all those textbooks? All of a sudden, I thought why not create a software to read the text for me, that I have entered so that I can enjoy someone else reading it for me. Thus, I created the app and wanted to share it with others. :)
The application's source code contains the assemblies and other tools required to build this very intuitive application that reads out the message passed to it. The source code demonstrates how you can change the speaking rate, voice of the audio and how to stop the speaking process if you want to stop the audio playback.
http://www.codeproject.com/KB/dotnet/1001536/Screenshot__2808_.png
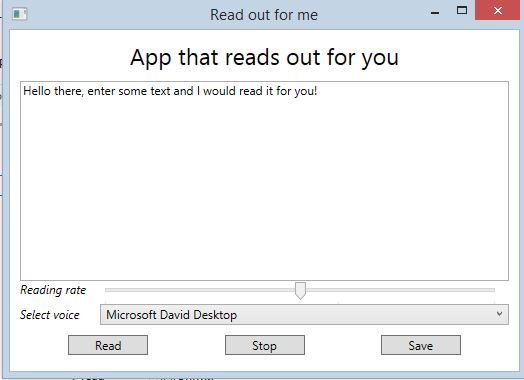
*Application's interface. Contains a sample text in the TextBox, default rate (zero), first
Installed voice selected and three buttons for three different functions.
*
{kind=link}
Requirements
The requirements to read the article are, an internet connection and a web browser. But to use the application, you need to build the application first as I have removed all of the binaries and object files so that you can use the source code and build it on your own platform. My environment was,
- Microsoft Visual Studio 2013 (Ultimate edition); You can also use any other edition or version of Visual Studio IDE 2013+
- .NET framework 4.5 (.NET framework 4.5.1 or 4.6 would also work)
You can surely do try out the application's source code in your own IDE and environment. At most it just won't compile, nothing big!
Getting started...
First of all, we need to know what our application is going to do, or what is the program actually going to do for us. Well, the program is a simple Input/Output program, where input is the string text, and the output is the speech that we are going to listen as output for that message that we have provided the application with.
Getting the text
Input is just the message, or entire essay that we want to listen to. Of course it would be a string type data, and we want to enter the message (paragraph or what ever) ourself, we would be using the TextBox control in our application to hold the content of the message to be read. A simple TextBox control is enough, if we want, we can add other attributes to it, to make it a perfect fit for our application. For our application, the following XAML markup is enough to generate the text box to get the input from the user.
<TextBox Name="text" Height="200"
Text="Hello there, enter some text and I would read it for you!"
TextWrapping="Wrap"></TextBox>
This input part is pretty much easy, and short. The most time-consuming part is the speech part, and the events to begin speaking, stop speaking or to change the output of the application. In this article, I would show you two types of outputs,
- Speaking the output through default device; in most cases it is the speaker, handsfree or other device if you have configured them in your control panel. Good to read the text at the moment.
- Saving the output in a Waveform format file (.wav) as audio, to play it later. Good for sharing the Text-to-speech file through network or to play them later.
Keep reading, the source code would be most intuitive so that you can understand the process through reading the source code.
Generating the Speech
First of all, let us talk about the input section. The input can by anything, but most specifically, since we are going to use System.Speech namespace, we would try to stick to as much namespace specific best approaches and best way to solve the problems as much as we can. Also, since we are going to recognize any input, and our input is only going to be a plain-string-type message, we can only include the System.Speech.Synthesis namespace that holds the objects required to speak an output to the user. Now that we have an idea of our context; namespace (System.Speech.Synthesis) and the application development framework (Windows Presentation Foundation), we can now continue to the input and output section.
One thing you should know before continuing reading the article is that we are going to use only one object from the namespace to create entire application, SpeechSynthesizer. This object inherits from IDisposable interface, thus enabling us to call the function Dispose on it as soon as we are done working with it. Or in other words, we can use the using block along with this object. In the following manner,
using (var reader = new SpeechSynthesizer()) {
// Use the object, .NET framework automatically clear the resources.
}
But, do not write it this way. We are going to use the object in Windows Presentation Foundation which uses only one thread to execute the business logic and update the user-interface. If you write your application in a most efficient way, like below,
using (var reader = new SpeechSynthesizer()) {
// Get the message value
reader.Speak(message); // Speak it out!
}
Above code would take care of resources itself, clear them out as soon as there is no more need of them, it would also speak the message out. The application would do its work as expected. But, the application would freeze. In most scenarios Windows Presentation Foundation would freeze, because another function or thread is currently processing and has not returned to the handler for the event. Button events, network resource access, long loops and similar to these our Speak function would freeze the application, speak the message and then return the control to the thread to update the user-interface.
What if I use the SpeakAsync instead of Speak
SpeechSynthesizer exposes two functions, Speak and SpeakAsync which can be used to speak out the message that we have passed. If one uses SpeakAsync instead of Speak, he cannot even listen to anything (if using the above code sample). That is because, as soon as the code hits the SpeakAsync the code returns to from where it was called instead of executing the complete function and then continuing, instead it (executes the next, then the next and then) calls the Dispose function on the object reader. Which makes it inaccessible for other threads, because the object has now been disposed.
Remember: SpeakAsync cannot be awaited.
Which leaves you to create your own functions to maintain the application to speak asynchronously, while allowing the user to still access the buttons and other functions. Continue reading the article, in the end we will be able to create the back-end code that is asynchronous (that is, it does not freeze the UI thread) and also is accessible so that the audio can be stopped, and the output can be changed and so on and so forth.
For a complete overview of how SpeakAsync works, have a look at the following image.
http://www.codeproject.com/KB/dotnet/1001536/AsyncFunction.png
Above image demonstrates how a user can write a fully efficient and memory-friendly code to speak a general text but still gets into trouble. Steps guide how and why there is no output.
{kind=link}
One more thing... Prompt vs String
SpeechSynthesizer allows us to use string-type values, or Prompt objects to generate speech response for our users. We can use the both of them, and the response would be same.
The string is a data type in .NET framework, every developer has understanding of a string-type data. And, if you use string-type data such as plain literal constant string, you will be able to generate the speech the same way it would be by using Prompt objects. Prompt, on the other hand, is an object (class) type present in System.Speech.Synthesis.
string message = "Hello, world";
Prompt prompt = new Prompt("Hello, world");
reader.Speak(message);
reader.Speak(prompt);
Both of the above functions would generate the same output, then where is the difference? The difference in then is that string is just plain-text that is spoken, on the other hand prompt is an object which can be generated using a PromptBuilder object, and can contain definitions for paragraphs, prerecorded audio files, changing the voices and/or the rate at which the speech is rendered and spoken.
If you want to generate an application, like for example, which reads out the dialogue between two people, you should use the PromptBuilder (instead of creating a Prompt each time). For example,
“Now he is here,” I exclaimed. “For Heaven’s sake, hurry down! Do be quick; and stay among the trees till he is fairly in.”
I must go, Cathy,” said Heathcliff, seeking to extricate himself from his companion’s arms. I won’t stray five yards from your window…
“For one hour,” he pleaded earnestly.
“Not for one minute,” she replied.
“I must–Linton will be up immediately,” persisted the intruder.”
In this case, you would require a lot of prompts, or a single PromptBuilder (along with the definitions of paragraphs, audio samples, voices and other Say-as stuff) passed to a Prompt constructor which then creates a new Prompt object for our rendering purposes.
Passing the above passage (or dialogue) directly as a string would not be a good idea, neither would be a good idea to change the output or input type, or voices many times an efficient solution. In such contexts, passing Prompt is the efficient way. Whereas, if you are going to read only plain-text, like an essay or a paragraph, then string would serve you enough. :)
Building the application
In above sections, I have made the application's background a little bit easy for you to understand. Now it is time to use the objects, and build up an application that can generate audio output for our text input.
Creating the Window
In WPF framework, you create Windows or Pages to render the controls for your user-interface. We need a few controls,
- TextBox control
to get the input text from the user. - Slider control
to get the speaking rate of the speech. (Range from -10 to 10) - ComboBox control
to get the voice for speaking. (We would bind it to the currently installed voices) - Button controls
to trigger different functions. (Three in our application:
1. Read ― Used for reading the text, spoken.
2. Stop ― For stopping the reading process.
3. Save ― For saving the output in a Waveform format file.
XAML markup in my application was,
<Window x:Class="ApplicationToRead.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Read out for me" Height="380" Width="525">
<Grid Margin="10">
<StackPanel>
<TextBlock FontSize="23" HorizontalAlignment="Center" Margin="0, 0, 0, 10">
App that reads out for you
</TextBlock>
<TextBox Name="text" Height="200" Text="Hello there, enter some text and I would read it for you!" TextWrapping="Wrap"></TextBox>
<TextBlock FontStyle="Italic">Reading rate</TextBlock>
<Slider Minimum="-10" Maximum="10" Margin="80, -15, 0, 0"
Ticks="2" HorizontalAlignment="Left" Width="400"
TickFrequency="5" TickPlacement="BottomRight"
Name="slider"
></Slider>
<TextBlock FontStyle="Italic">Select voice</TextBlock>
<ComboBox Margin="80, -18, 0, 0" Name="comboBox" ItemsSource="{Binding}"></ComboBox>
<Grid Margin="10">
<Grid.ColumnDefinitions>
<ColumnDefinition />
<ColumnDefinition />
<ColumnDefinition />
</Grid.ColumnDefinitions>
<Button Width="80" Name="read" Click="read_Click">Read</Button>
<Button Width="80" Name="stop" Click="stop_Click" Grid.Column="1">Stop</Button>
<Button Width="80" Name="save" Click="save_Click" Grid.Column="2">Save</Button>
</Grid>
</StackPanel>
</Grid>
</Window>
The GUI has already been shared in the Introduction section of this article. You can view it there.
Back-end code
Now the part comes to write the back-end code, so that our application can actually do something useful for us. We need a few objects to save our state of application.
- A variable to store the state of application, whether the reader is reading or not.
private bool reading { get; set; } - We also need to stop the speech when we want to. So, we would create a private handle-like variable to currently spoken prompt.
private Prompt activePrompt { get; set; } - We also need the SpeechSynthesizer object.
private SpeechSynthesizer reader { get; set; }
As already discussed, we would require the object throughout our application's life because we need it to render the response and provide us with audio sample to be heard. But if we would create the object every time we would be left with two scenarios.
- In first scenario, we would have to use Speak method (not SpeakAsync). Which would do what we want it to, it would make sure the text is spoken fully, before anything else is done. But that leads us to another problems, that is, that our application would freeze until entire text has been spoken. Bad way to write application.
- In second one, we create a new object (as in the above image for SpeakAsync) and use it to speak the text asynchronously, that solves the problem for our application getting frozen. But it leads to another problem, the user doesn't hear a thing. That has been explained above in the image, please read it.
So, we are left with a scenario where we need to create an object that can be accessed through different functions. Thus a private object is a good suitable candidate. Also remember that having less variables is a good and memory-efficient solution, but a solution that creates too many objects and deletes them after one or two statements is not a good program also, because it takes a lot of CPU to manage the memory also. CPU is also a resource, less RAM + less CPU is a good solution, managing memory only and wasting a lot of CPU is also worst pattern to follow. Manage them together to create a good application.
Note that we can always call the .Dispose function on the object, thus we do not necessarily require the using block, using block is just a shorthand that would let us forget about clearing the memory resources and focus on how to use the object. Thus we remove the using block and create a private object that can be accessed through different functions, and gets disposed when the application is closing.
// Dispose the object manually when the app is closing.
System.ComponentModel.CancelEventHandler closingHandler = (sender, e) =>
{
reader.Dispose();
};
this.Closing += closingHandler;
Above code attachs a closingHandler (which indeed is a lambda expression) as event handler for the Closing event of WPF's Window object. Then it calls Dispose function so that the object is disposed when no longer needed. Thus this would be a "Buddy, please!" for memory-efficient freaks. :) You can later remove the closingHandler using -+ operator.
Now we need the functions (as the event handlers for the Button controls) to do what we want them to and a few more tinkering to make our application work.
Selecting installed voices
First, we need to list the voices that we have right now. Note that voices are installed as a software, library, or utility. You can only use the voice that has been installed, not the ones you expect or want to hear. For this, we would select the voices.
// Binding the Combobox to the names
List<string> names = new List<string>();
// For every voice installed
foreach (var voice in reader.GetInstalledVoices())
{
// Only add Enabled voices, otherwise it is of no use
if (voice.Enabled)
{
names.Add(voice.VoiceInfo.Name);
}
}
comboBox.DataContext = names; // Set the DataContext for binding purposes
comboBox.SelectedIndex = 0; // Select the first one
Note that there is a field Enabled in InstalledVoice object that tells you whether a voice is enabled (ready for use) or not. If a voice is not enabled, then it won't be used. That is why I am having a condition to load only enabled voices to be used. In my case, they were equal to the those with Enabled flag true. The list is then bound to the comboBox we are having, so that our ComboBox would now display the names of the voices installed.
In the first image, you will see Microsoft David Desktop, that is an installed voice (I did not, .NET did perhaps or Microsoft.Speech library, I am not sure) along with 2 others, Microsoft Hazel Desktop and Microsoft Zira Desktop. Also, Microsoft David Desktop is selected automatically, because of our code; e.g. see the last line of above code block.
Reading out the text
In this function, I would show you the code that can be used to generate the speech response that can read out the text to the user.
See the following code block and read the comments added,
private void read_Click(object sender, RoutedEventArgs e)
{
// Call the speak function
string message = text.Text;
string voiceName = "";
// Voice must be selected
if (comboBox.SelectedIndex != -1)
{
voiceName = (comboBox.SelectedItem).ToString();
}
// Rate for the rendering
int rate = (int)slider.Value;
reader.Rate = rate;
// Name must be full-qualified string
reader.SelectVoice(voiceName);
// Reads one paragraph or passage at a time. Why read two?
if (!reading)
{
reader.SetOutputToDefaultAudioDevice();
}
else
{
MessageBox.Show("Previous reader is currently reading. Press 'Stop' to try stopping it and try again.");
return; // return and stop doing anything
}
reading = true;
// Get the prompt that is being read out right now; for stopping it later.
activePrompt = reader.SpeakAsync(message);
// Handle the event, remove when not required
EventHandler<SpeakCompletedEventArgs> handler = (sander, ev) =>
{
reading = false;
};
reader.SpeakCompleted += handler;
}
Thus when user would press Read button, it would set up the speaking configurations, and then changes the output type to default audio device; that can be changed through Control panel, look for the option. In most cases default device is speaker, otherwise headphone (if attached) or other similar device.
I did say in this article, I would show you how to generate speech to hear through speakers (or default device) or to generate the audio samples in Waveform format file to share over network or to listen to it later or any other purpose. For this sake, I have implicitly changed the output to speakers in this function, because we will change the output type to file in a later function. Keep reading...
Stopping the speech
In the above code, you will see that each time the speech is initiated, a handle is capture to the current Prompt object. That is later used to stop the speech process.
The following event handler does the thing,
private void stop_Click(object sender, RoutedEventArgs e)
{
// Stop the reading process
if (reading)
{
reader.SpeakAsyncCancel(activePrompt);
}
}
The prompt is passed, and is cancelled. If you (somehow) want to allow to speak multiple prompts, then you can also call SpeakAsyncCancelAll() that would cancel every instance of prompts running.
Generating a Waveform file
Another use of this library is that you can generate audio samples, for your Text-to-speech output. It can be shared over network, streamed down to your users, stored in file system for later use. Perhaps many other uses for the file generated.
I would show, only how to create the file, you can then use System.Diagnostics.Process.Start("file-path.wav"); to listen to it programmatically, or open it through your Windows Explorer.
The following code does the thing,
private void save_Click(object sender, RoutedEventArgs e)
{
string message = text.Text;
// Store the audio
if (!reading)
{
reader.SetOutputToWaveFile("E:\\MyAudioFile.wav");
reader.SpeakAsync(message);
}
else
{
MessageBox.Show("Previous reader is currently reading. Press 'Stop' to try stopping it and try again.");
}
}
It would change the output to a file, (Remember: File would be held by the program and would not be accessible by other programs, until the program is referencing the file for output) and would write the audio to the file. You can listen to the file later, when ever you want to.
You can also get the output as Streams, please read the SpeechSynthesizer object documentation on MSDN for more details.