SQL Server: Demystifying TempDb and recommendations
Introduction
TempDb is an integral part of SQL Server under system databases whose architecture is designed to be shared for SQL Server instance. TempDb is related to connection and sessions and, thus, SQL Server reset TempDb when restart. That means, TempDb state is not persistent like other databases. When SQL Server restarts, TempDb is copied from model database. Technically, it never gets deleted & recreated, TempDb gets cleared and copied when instance restarts. It is important to note that when on restart TempDb data file size it reset to the initial size defined (or 8 MB, if kept default).
You can create tables in TempDb like you do in other databases and it does perform faster in TempDb because most of the internal operation doesn't generate log in TempDb as rollback is not required. The real issue with TempDb is missing "D" from ACID property which indicates
" That the database won't be able to keep track of pending changes by which server can recover from an abnormal termination "
So, even if you use TRANSACTION and server restarts you won't be able to recover it.
TempDb is an important part of SQL Server database as it manages a temporary object which includes:
1**. Internal Objects**
Objects created internally by SQL Server to process SQL queries.
- Hash join and Hash Aggregates
- Temporary LOB objects
- CTE
- Sort and Spools
- May get used in GROUP BY, ORDER BY or UNION
- Index rebuild
- System Tables and Indexes
2. User Objects [Temporary]
Created by users explicitly
- Temp Table [global or local]
- Temp variables
- Cursor
- Temp procedure
3. Version stores
A version store is a collection of data pages that hold the data row that are required to support features that uses row versioning.
- Row version which are generated by data modification transactions for features
- AFTER trigger
- Multiple Active Result Sets (MARS)
- Online indexes
- INSTEAD OF Trigger
- Row version which are generated by data modification transaction for databases
Database which is using Snapshot isolation
Database which is using read-committed isolation
Note : Above specified list is a broad way specification of objects used by or in TempDb.
Few important facts about TempDb
There are misconception about TempDb working and configuration, so below are few important point which shows the fact about TempDb
- There can be only one TempDb per database instance.
- TempDb is recreated every time SQL Server is started. Which means that configuration changes to TempDb needs restart.
- You cannot backup or restore TempDb database
- You cannot enabled Change data capture in TempDb
- You cannot drop TempDb
- Database owner for TempDb is sa, which cannot be changed
- TempDb use the same database collation as your server. So, it cannot be changed
- You cannot change the RECOVERY mode of TempDb. It will always be SIMPLE.
- Cannot enabled auto shrink on TempDb
- TempDb is always ONLINE, you cannot make it OFFLINE.
- TempDb will always works on MULTI_USER mode.
- TempDb does not support ENCRYPTION.
- TempDb will not allow deleting primary data file or logging file.
You can check properties of database by using sys.databases catalog view; sys.databases contains one row for each database and database_id ideally represents TempDb
USE [MASTER]
SELECT * FROM sys.databases WHERE database_id = 2
Similarly, you can use sys.master_files catalog view to get the files related to TempDb database
USE [MASTER]
SELECT * FROM sys.master_files WHERE database_id = 2
With the help of below DMV, you can check how much TempDb space does your session is using. This query is quite helpful while debugging TempDb issues
SELECT * FROM sys.dm_db_session_space_usage WHERE session_id = @@SPID
Memory = TempDb
Memory is directly or indirectly related to TempDb. As mentioned in introduction part of this article TempDb is used both for internal and user objects. Poor written query can cause high memory utilization which is one of the most common scenario while dealing with performance.
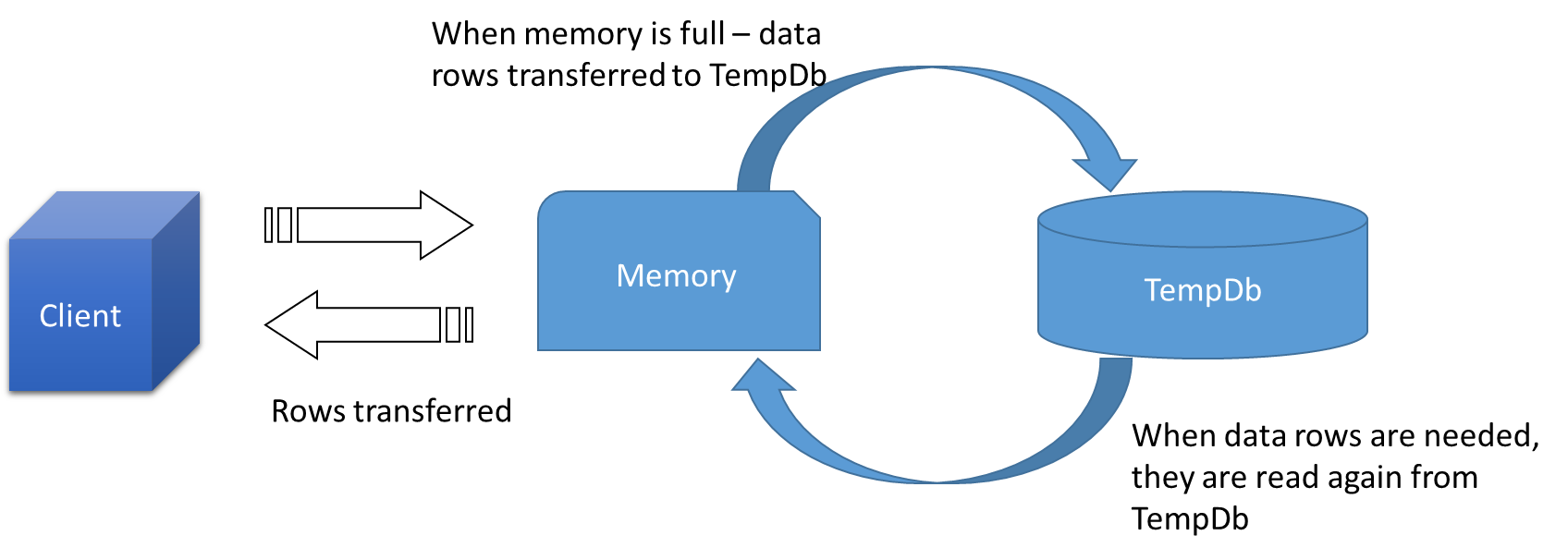
When rows comes from client they stores in memory, when memory is full then SQL will transfer the data on memory to TempDb to free the memory for new upcoming rows. When the data is needed it gets fetched from TempDb again which is a slower operation than reading the data from memory.
Usually, the problem occurs due to the long running transaction or bad cardinality estimator. The best way to solve it by building statistic but if still they don't work then changing the join type may help reducing the overhead on TempDb.
Temporary object in Cache
SQL Server cache temporary object like temporary tables, in memory. They will be cached under memory until
- Statements like CREATE INDEX or CREATE STATISTICS are not run after table is created
- Temporary object is created under UDF, Stored procedure, Trigger
- Object is not created using dynamic SQL
- Named constraints are not created
Identify long running transaction
To check database level transaction related to TempDb; by below query we can get the list of transaction which are opened and consuming TempDb.
SELECT transaction_id ,
database_transaction_begin_time ,
DATEDIFF(SECOND, database_transaction_begin_time, GETDATE()) AS 'Transaction Time(Seconds)',
CASE database_transaction_type
WHEN 1 THEN 'Read/write'
WHEN 2 THEN 'Read-only'
WHEN 3 THEN 'System'
END AS 'Type',
CASE database_transaction_state
WHEN 1 THEN 'The transaction has not been initialized.'
WHEN 2 THEN 'The transaction is active.'
WHEN 3 THEN 'The transaction has been initialized but has not generated any log records.'
WHEN 4 THEN 'The transaction has generated log records.'
WHEN 5 THEN 'The transaction has been prepared.'
WHEN 10 THEN 'The transaction has been committed.'
WHEN 11 THEN 'The transaction has been rolled back.'
WHEN 12 THEN 'The transaction is being committed. In this state the log record is being generated, but it has not been materialized or persisted.'
END AS 'Description',
database_transaction_log_record_count AS [Number of Log Records],
database_transaction_begin_lsn,
database_transaction_last_lsn,
database_transaction_most_recent_savepoint_lsn,
database_transaction_commit_lsn
FROM sys.dm_tran_database_transactions
WHERE database_id = 2
Trouble shooting TempDb issues are critical aspect of improving SQL Server performance. Below operators are solely dependent upon TempDb
- Spool - Full input row set will be stored
- Sort - Full row set
- Hash Join or aggregation - Hash table might store in TempDb
Best practice to configure TempDb
There are several best practices which are recommended to be used for configuring and maintaining TempDb. These settings and configuration are recommended to be checked on regular interval.
**Configuring Data file **
TempDb data files have some basic thumb rules
- Each data file should have same initial size [ Auto growth may cause fragmentation]
- Each data file should have same auto growth [you can skip this by setting correct initial size for each data file]
- Number of data file should be equal to number of processors [arguable, see below discussion]
You actually don't need to have files per core of CPU's. This means, that if you have 80 logical CPU's then you don't have to create 80 data files for TempDb. That will actually reduce performance.
Assume following parameters,
M = Space in GB available on your storage.
N = Number of data files needed
L = Number of log file needed
C = Number of logical CPU
From below query we can get the number of data files required. If N > 8 then we will start with 8 files & then gradually increase it based on the requirement and performance.
SELECT cpu_count/4 AS N FROM sys.dm_os_sys_info
Note: Do not start by creating more than 8 data files. You can increase it later if you observe TempDb contention. 8 is the general cap for MAXDOP setting.
Formula:
Number of data file(s) required (N) =C/4
Each data file size (W) = (M*.9)/ (N+2)
Log file size(X) =W*2
So, for example you have M = 100 GB and C = 12
Number of data file(s) required (N) =12/4=3
Each data file size (W) = (100*.9)/ (3+2) =18GB
Log file size(X) =18*2 = 36 GB
So, total size would be 3 * 18 + 36 = 90 GB and leave 10 GB for log file auto growth
This will help you to figure out the size requirement of data file and approximate log file size. However, log file size should also need more attention for proper functioning and based on available memory. Below section will cover the log file requirement for TempDb database.
**Configuring Log files **
Though, most of the operations are logged into TempDb & there is still variety of operation that does require TempDb like Temporary table, sorting etc. Log file is an important part of any database included TempDb. It is important to note that writing to log file is a sequential process and adding multiple log file doesn't work in parallel. This means that you can have 1 log file for TempDb [if it gets enough space to auto grow]
CHECKPOINT for TempDb has lower priority than other databases, i.e. it will fire when TempDb log is 70% filled. Now, if there is a long running transaction which has consumed 70% of log file but because TempDb checkpoint has lower priority so it will be queued behind databases checkpoint. This will cause in log file size keep on increasing. To avoid this, you can fire indirect CHECKPOINT when log file grow more than 80% which has higher priority.
There are few helpful tips to consider the size of TempDb log file
- Calculate the largest index size on the database.
- Monitor current space usage of log file
- Estimated number of rows (n) written on TempDb for largest transaction per minute
Formula:
Project log file size = Estimated size of log file (E) + 10% E = n * (Number of minutes query executed) * (Row size)
So, if your temp data row size is 20 KB and it was executed for 30 min with 1000 rows per minute then your expected log file size will be = 1000 * 30 * 20 = 600000 KB ~ 585 MB + 58 MB = 643 MB
Note: Above formula is just a rough estimation there are other factors too which needs to be considered. Ex.: Parallel query executions, memory available on server, maximum memory allocation on SQL Server etc.
Tips for troubleshooting TempDb issues
- Remove SQL Server related files from antivirus check
- Keep TempDb files on the fast IO system; preferably RAID 0 or RAID 10
- Avoid using drive for TempDb which is already being in use by other database files.
- Run index management(i.e. rebuild index) and monitor TempDb usage
- Check if SORT_IN_TEMPDB is set ON for rebuilding indexes. Default and preferred value is OFF.
- Monitor disk Avg. Sec/Read and Avg. Sec/Write
- Less than 10 milliseconds (ms) = Very good
- Between 10-20 ms = Borderline
- Between 20-50 ms = Slow, needs attention
- Greater than 50 ms = Serious IO bottleneck
- Check Server level parameter Ex. MAXDOP
- Enable TF 1118 - There is no downside effect for enabling trace flag 1118 on SQL Server version greater or equal to 2000.
- Though, I recommend to not set auto growth for data files. But if you do so, then enable IFI (Instant File Initialization) on Windows Server to improve the performance.
- If you have set data file to auto grow then enable trace flag 1117 to ensure uniform data grow for all data files.
- Waits which could be related to TempDb
PAGELATCH_EX
PAGELATCH_UP
CXPACKET
- Identify TempDb contention
Below query will identify TempDb contention
SELECT * FROM sys.dm_os_waiting_tasks
WHERE resource_description IN ('2:1:1','2:1:2','2:1:3')
AND wait_type Like 'PAGE%LATCH_%'
If there are large number of page latch for resource type 2:1:1 or 2:1:2 or 2:1:3 (i.e. database Id: File id: page number), this means that TempDb contention is happening due to one of the reasons
- Disk I/O issue, use better disk
- Configure multiple data files
- Equalize data file size
There are two ways to quickly remove database contention:
- Add data files to TempDb
- Reuse temporary objects
- Monitor file space usage
SELECT
SUM (user_object_reserved_page_count)*8 as usr_obj_kb,
SUM (internal_object_reserved_page_count)*8 as internal_obj_kb,
SUM (version_store_reserved_page_count)*8 as version_store_kb,
SUM (unallocated_extent_page_count)*8 as freespace_kb,
SUM (mixed_extent_page_count)*8 as mixedextent_kb
FROM sys.dm_db_file_space_usage
Attribute |
Meaning |
Higher number of user objects |
More usage of Temp tables , cursors or temp variables |
Higher number of internal objects |
Query plan is using a lot of database. Ex: sorting, Group by etc. |
Higher number of version stores |
Long running transaction or high transaction throughput |
Sp_WhoIsActive is a nice script to check which query is consuming your TempDb space. Alternatively, below query can provide a quick glance to the SQL text causing overhead on TempDb
SELECT TST.session_id AS [Session Id],
EST.[text] AS [SQL Query Text], [statement] = COALESCE(NULLIF(
SUBSTRING(
EST.[text],
ER.statement_start_offset / 2,
CASE WHEN ER.statement_end_offset < ER.statement_start_offset
THEN 0
ELSE( ER.statement_end_offset - ER.statement_start_offset ) / 2 END
), ''
), EST.[text]),
DBT.database_transaction_log_bytes_reserved AS [DB Transaction Log byte reserved]
, ER.Status
,CASE ER.TRANSACTION_ISOLATION_LEVEL
WHEN 0 THEN 'UNSPECIFIED'
WHEN 1 THEN 'READUNCOMITTED'
WHEN 2 THEN 'READCOMMITTED'
WHEN 3 THEN 'REPEATABLE'
WHEN 4 THEN 'SERIALIZABLE'
WHEN 5 THEN 'SNAPSHOT'
ELSE CAST(ER.TRANSACTION_ISOLATION_LEVEL AS VARCHAR(32))
END AS [Isolation Level Name],
QP.QUERY_PLAN AS [XML Query Plan]
FROM
sys.dm_tran_database_transactions AS DBT
INNER JOIN sys.dm_tran_session_transactions AS TST
ON DBT.transaction_id = TST.transaction_id
LEFT OUTER JOIN sys.dm_exec_requests AS ER
ON TST.session_id = ER.session_id
OUTER APPLY sys.dm_exec_sql_text(ER.plan_handle) AS EST
CROSS APPLY SYS.DM_EXEC_QUERY_PLAN(ER.PLAN_HANDLE) QP
WHERE DBT.database_id = 2;
Shrinking file is not recommended as it may fragment data and slow down your server performance. Even if you try to shrink data file it will only shrink user objects.
Conclusion
TempDb performance is critical for SQL Server behavior and memory management. If it is configured incorrectly, performance can be affected dramatically. We can easily change the behavior of TempDb by monitoring on the right area. Try to avoid auto growth for both data and log file by correctly assigning the size of it.
See Also
- Troubleshooting Insufficient Disk Space in tempdb
- Active Transactions with Request Data by Olaf Helper
- Capacity planning for tempdb
- Optimizing tempdb Performance
Credits
I would like to thank Olaf Helper MVP for reviewing this article.