T-SQL: Improve the Performance for LIKE Wildcard by Changing the Collation
DOWNLOAD |
All Codes used in this article is downloadable from this URL. |
** **
Introduction
Do you want to improve the performance of the T-SQL queries that have LIKE Wildcard in their WHERE clause? This article offers a simple solution to this issue, but like many other solutions, this one also has its limitations. ** **
Problem
Running queries to find all the matches’ strings with the given string in huge tables usually have a poor performance. Why are these queries slow? The answer is Sargability! If you want to know more about it, you can see Sargability: Why %string% Is Slow written by Brent Ozar. By the way, we still can try to tune up the performance of such queries in some situations.** **
Solution
One solution to this problem is changing the column collation. If we use the Binary collation instead of SQL or Dictionary collation, we can improve the performance of the LIKE wildcard queries on that column. But this improvement varies in different situations.** **
Case Study
The following code inserts 10 millions of rows into the sample table which its name is NewTable. I used one of the solutions that provided by Ronen Ariely (pituach), from his T-SQL: Random String article. If you want to use a faster and far better solution to produce random values, you can use his other article: SQL Server: Create Random String Using CLR.
Code 01
--drop & craete table
IF OBJECT_ID('NewTable', 'U') IS NOT NULL
DROP TABLE NewTable ;
GO
CREATE TABLE NewTable
(
Id INT IDENTITY
PRIMARY KEY ,
Code NVARCHAR(30) COLLATE SQL_Latin1_General_CP1_CI_AS
);
GO
--insert ten million rows
DECLARE @StringMaxLen int = 30;
WITH Nums AS ( SELECT n
FROM ( VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9) ) AS T(n) )
INSERT dbo.NewTable
( Code )
SELECT
LEFT (REPLACE(CAST (NEWID () AS NVARCHAR(MAX)),'-','') , ABS (CHECKSUM (NEWID ())) % @StringMaxLen + 1)
FROM Nums AS a
CROSS JOIN Nums AS b
CROSS JOIN Nums AS c
CROSS JOIN Nums AS d
CROSS JOIN Nums AS e
CROSS JOIN Nums AS f
CROSS JOIN Nums AS g ;
The above code may take a few minutes to execute. Because this table has random values, we don’t know what values are in the table right now. But, we can use a sample next code to take a look at a few rows of it.
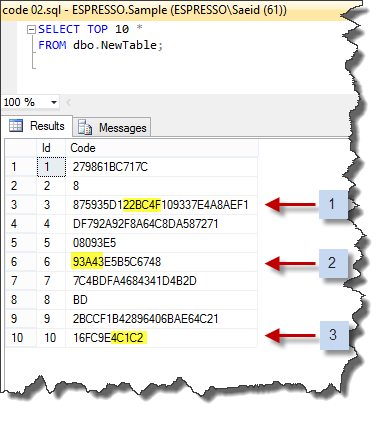
Code 02
SELECT TOP 10 *
FROM dbo.NewTable;
Pic 01
** **
Performance Tests and Results
We can pick up three random pattern strings from the above sample result set for testing the solution. Those patterns that I chose are the following:
- 22BC4F
- 93A43
- 4C1C2
Your values will be different. Now, we can run the next three queries as our test code.
Code 03
-- query 1
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'22BC4F' + N'%'
-- query 2
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'BD' + N'%'
-- query 3
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'C1C2' + N'%'
We want to test the performance of these three different queries:
- Query 1 - after restart SQL Server (CHECKPOINT + DBCC DROPCLEANBUFFERS)
- Query 2 - with a cold buffer cache (DBCC DROPCLEANBUFFERS)
- Query 3 - with the warm cache
It is time to test and compare the results between Binary and non-binary collations.
** **
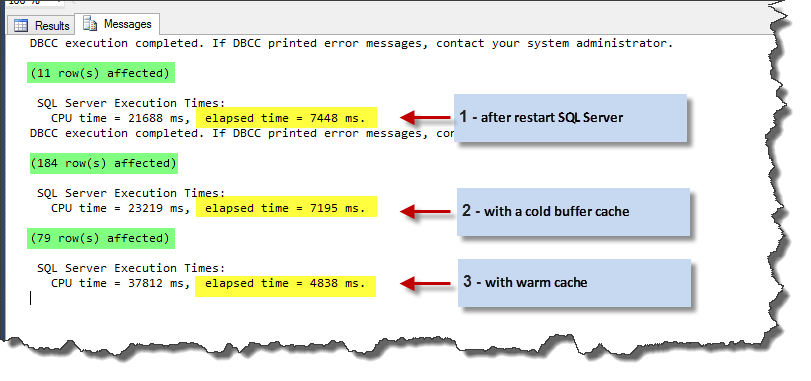
Non-Binary Collation
To apply above conditions, we can change the former test code to the following code. The result of this code in our test machine is shown in the next screenshot.
Code 04
--[Query 1 after restart SQL Server (CHECKPOINT + DBCC DROPCLEANBUFFERS)]
CHECKPOINT;
GO
DBCC DROPCLEANBUFFERS;
GO
SET STATISTICS TIME ON;
-- query 1
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'22BC4F' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
--[Query 2 with a cold buffer cache (DBCC DROPCLEANBUFFERS)]
DBCC DROPCLEANBUFFERS;
GO
SET STATISTICS TIME ON;
-- query 2
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'93A43' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
--[Query 3 with warm cache]
SET STATISTICS TIME ON;
-- query 3
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'4C1C2' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
Pic 02
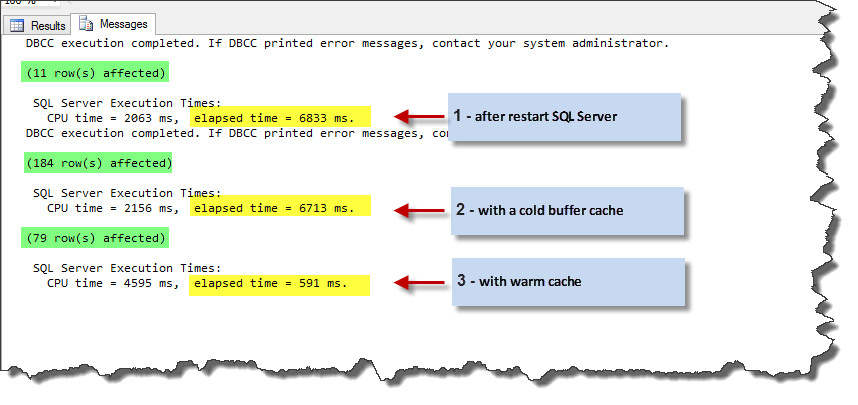
Binary Collation
Now, we have to apply a binary collation for this section. We can simply do this by using the next code:
Code 05
ALTER TABLE dbo.NewTable
ALTER COLUMN Code NVARCHAR(30) COLLATE Latin1_General_BIN;
We can run the same test code again. The results in our test machine are illustrated in the next picture. The following code is the same former test code.
Code 06
--[Query 1 after restart SQL Server (CHECKPOINT + DBCC DROPCLEANBUFFERS)]
CHECKPOINT;
GO
DBCC DROPCLEANBUFFERS;
GO
SET STATISTICS TIME ON;
-- query 1
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'22BC4F' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
--[Query 2 with a cold buffer cache (DBCC DROPCLEANBUFFERS)]
DBCC DROPCLEANBUFFERS;
GO
SET STATISTICS TIME ON;
-- query 2
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'93A43' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
--[Query 3 with warm cache]
SET STATISTICS TIME ON;
-- query 3
SELECT Code
FROM dbo.NewTable
WHERE Code LIKE N'%' + N'4C1C2' + N'%'
--OPTION (RECOMPILE);
SET STATISTICS TIME OFF;
------------------------------------------------------------
Pic 03
** **
Summary

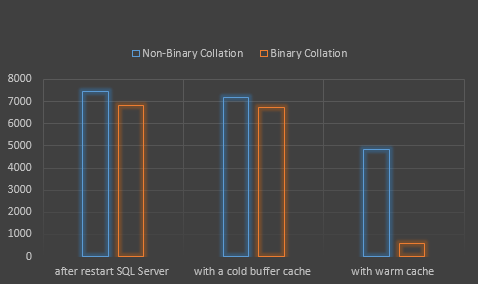
These results show slight improvements in the two first situations, but the huge improvement in the last situation. If you have a big table with frequent LIKE wildcard queries on it, you might want to consider changing the column collation to its equivalent Binary collation.
Usage and Limits
Well, is it always possible to change the column collation? It is based on the database design, application software and the column values itself. For example, if we have codes, barcodes, national security codes etc. which we stored them in the VARCHAR () or NVARCHAR () columns, we can usually change the column collation without any problem. Moreover, we cannot use SQL Server Full-Text in such columns, because full-text is based on the worlds. But, we usually store the combination of letters and characters in such columns. So, in the lack of a feature that could improve our performance, changing the collation will improve the performance very well.
Conclusion
This article showed one solution to improve the performance of the SQL Server LIKE wildcard queries. We saw the benefits, limits, few usages and the performance tests of using Binary collations on behalf of the SQL or Dictionary collations.
DOWNLOAD |
All Codes used in this article is downloadable from this URL. |
** **
See Also
- Transact-SQL Portal
- Wiki: Development Portal
- T-SQL: Random String
- SQL Server: Create Random String Using CLR
Other Resources