T-SQL: How to Sort a Column that Contains Character-Separated Numbers
** **
DOWNLOAD |
All Codes used in this article is downloadable from this URL. |
** **
Introduction
In this article, we are going to compare two alternative solutions for sorting comma separated numbers. The first solution is an old-fashioned one applicable to SQL Server 2000 and later versions. It has some limitations. Although, the second solution is a creative use of a new data type accessible in SQL Server 2008 and later versions, but also with its own limits. We will compare and contrast these two solutions so we can make an informed choice based on our database design.
Problem
Character separated numbers is a specific type of character-separated values (CSV). It is a delimited text that uses commas or other specific characters to separate numbers. This data format has been used for many years with numerous applications. In relational databases we can use it to hold attributes like:
- Phone number
- Social Security Number (SSN)
- Bank Credit/Debit card number
- Indicator letterbox code
- IP address
- Part Number
- International Standard Book Number (ISBN)
For example, ISBN code is a unique numeric commercial book identifier which is 10 or 13 digits that separated into four or five parts based on its standard (ISBN-10 or ISBN13). These parts separated by hyphens. If we search the ISBN number 0-7356-1131-9 via search engines, we can find that it represents the book: “Code: The Hidden Language of Computer Hardware and Software” by Charles Petzold. One of the data types we can choose for such standards is using VARCHAR which will store our values as string values. This means that the SQL Server engine thinks our values are character based and treats them like strings. One issue is sorting because characters are sorted differently than numbers. We can see this demonstrated using the following sample:
Code 01
-- create a new database for test
CREATE DATABASE Sortting
GO
USE Sortting
GO
--create sample table
IF OBJECT_ID('dbo.Letters', 'U') IS NOT NULL
DROP TABLE dbo.Letters;
CREATE TABLE dbo.Letters
(
LetterID INT IDENTITY
PRIMARY KEY ,
IndicatorCode NVARCHAR(20) ,
LetterType TINYINT ,
Title NVARCHAR(500)
)
GO
--insert sample data
INSERT dbo.Letters
( IndicatorCode, LetterType, Title )
VALUES ( N'2004/9/5555/2' , 1, N'Letter 9' ) ,
( N'2004/10/5555/2', 1, N'Letter 10' ) ,
( N'2004/11/5555/2', 1, N'Letter 11' )
GO
--query 0
SELECT *
FROM dbo.Letters
ORDER BY IndicatorCode;
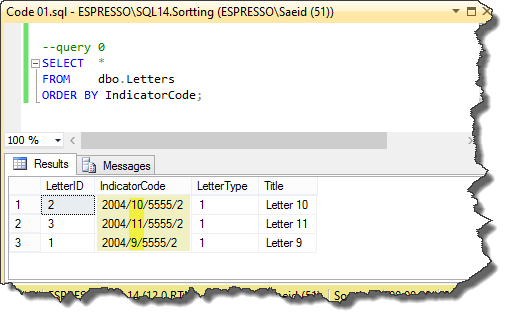
We used slash as separator character for digits in the IndicatorCode column values. As illustrated in the picture_01, the result of the query 0 in this code is not based on the numeric sorting and shows the wrong order.
Picture_01
Solution One – Using PARSENAME() Function
The first workaround for this problem is using the PARSENAME () function. This function was created to split out the four parts of a qualified database object name. We can use it to return each part of other string that may not be an object name.
The solution step by step:
First, we have to replace slash characters with dots, as we did in query 1-1 in the following code:
Code 02
--query 1-1
SELECT * ,
REPLACE(IndicatorCode, N'/', N'.') AS [New IndicatorCode]
FROM dbo.Letters
ORDER BY IndicatorCode;
Picture_02
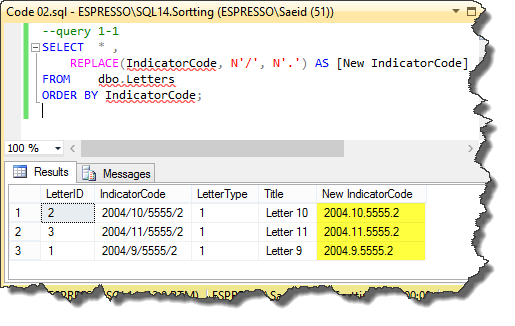
Now, we can use PARSENAME () to return the first part, for instance. The important point is we used the value 4 to get the first part. This is showed in the query 1-2 in this code:
Code 03
--query 1-2
SELECT * ,
REPLACE(IndicatorCode, N'/', N'.') AS [New IndicatorCode] ,
PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 4) AS [First Part]
FROM dbo.Letters
ORDER BY IndicatorCode;
Picture_03
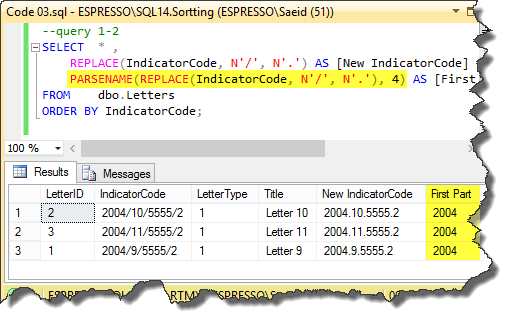
In the next step, we can see that we can use the query 1-3 to order based on each part separately. But it still is based on characters sorting rules, because the output result data type of the PARSENAME() is NCHAR(). This code shows this step:
Code 04
--query 1-3
SELECT --* ,
REPLACE(IndicatorCode, N'/', N'.') AS [New IndicatorCode] ,
PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 4) AS [First Part] ,
PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 3) AS [Second Part] ,
PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 2) AS [Third Part] ,
PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 1) AS [Fourth Part]
FROM dbo.Letters
ORDER BY [First Part] ,
[Second Part] ,
[Third Part] ,
[Fourth Part];
Picture_04
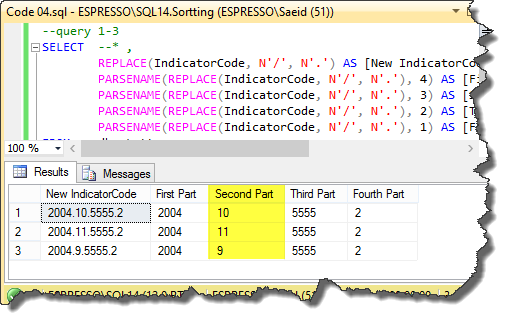
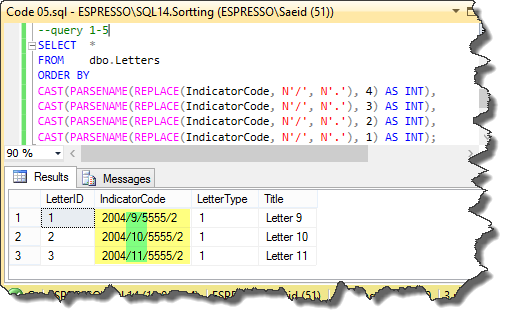
In the next code, we can see the final steps. We convert each output part to integer data type in the query 1-4. So, we can use the sorting based on the integer data type for them. The query 1-5 shows the final clean code solution.
Code 05
--query 1-4
SELECT * ,
REPLACE(IndicatorCode, N'/', N'.') AS [New IndicatorCode] ,
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 4) AS INT) AS [First Part] ,
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 3) AS INT) AS [Second Part] ,
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 2) AS INT) AS [Third Part] ,
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 1) AS INT) AS [Fourth Part]
FROM dbo.Letters
ORDER BY [First Part] ,
[Second Part] ,
[Third Part] ,
[Fourth Part];
--query 1-5
SELECT *
FROM dbo.Letters
ORDER BY
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 4) AS INT),
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 3) AS INT),
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 2) AS INT),
CAST(PARSENAME(REPLACE(IndicatorCode, N'/', N'.'), 1) AS INT);
Picture_05
Solution Review
Pros
This solution is applicable to all SQL Server versions
It can be used for Character-Separated Values (CSV) which also can have letters instead of digits
We can use this when we have multiple characters as a delimiter
Cons
This solution limits to four parts of character-separated values (CSV)
It is a relational solution for parsing character values and cannot achieve to ideal performance
Solution Two – Using HIERARCHYID Data Type
The second solution is using the HIERARCHYID data type. This data type introduced in SQL Server 2008 to represent tree and hierarchy data type attribute like the organizational chart. This data type value representation and concept are really similar to a character-separated value (CSV), but just for numeric data in each node. So, it is only applicable to sorting character-separated numbers and SQL Server 2008 and later versions.
Now, we try to achieve this solution step by step:
A value of the Hierarchyid data type represents a position in a tree. When we want to insert a value in a column with Hierarchyid data type, we insert values like this:
/1/2/3/1/
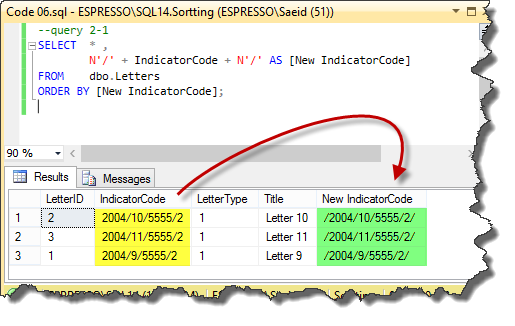
So, if we concatenate our slash-separated numbers with two slashes in the start and the end of our values, then we can convert it to Hierarchyid data type. The following code shows this. We enclosed the IndicatorCode with extra slashes in the query 2-1.
Code 06
--query 2-1
SELECT * ,
N'/' + IndicatorCode + N'/' AS [New IndicatorCode]
FROM dbo.Letters
ORDER BY [New IndicatorCode];
Picture_06
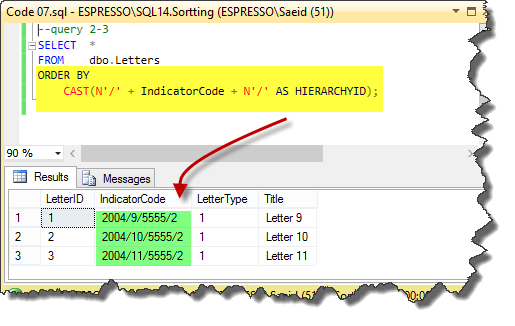
In the next code, we can see the final step. We convert IndicatorCode column values to Hierarchyid data type in the query 2-2. So, we can use the sorting based on Hierarchyid data type which in each node is based on the numeric sort order. The query 2-3 shows the final clean code solution.
Code 07
--query 2-2
SELECT * ,
CAST(N'/' + IndicatorCode + N'/' AS HIERARCHYID) AS [New IndicatorCode]
FROM dbo.Letters
ORDER BY
[New IndicatorCode];
--query 2-3
SELECT *
FROM dbo.Letters
ORDER BY
CAST(N'/' + IndicatorCode + N'/' AS HIERARCHYID);
Picture_07
Solution Review
Pros
This solution can also perform well for more than four parts of character-separated numbers.
Hierarchyid data type is a CLR-based data type and optimized for representing trees and has better performance.
We can use this solution when we have multiple characters as the delimiter.
Cons
This solution is applicable to SQL Server 2008 and later versions.
It cannot be used for Character-Separated Value (CSV) which also can have letters instead of digits
Bonus Samples
If you want to see more samples that shows the comparison between these two solutions, you can download the sample code of this article and open the file "extra samples”. Your comments and feedback will help us!
Conclusion
This article shows only two solutions to this problem. There are other solutions like using CLR functions or XML data type and so on. But, these two solutions are easy to use and the second one performs better than the first solution.
DOWNLOAD |
All Codes used in this article is downloadable from this URL. |
** **
See Also
- T-SQL: How the Order of Elements in the ORDER BY Clause Implemented in the Output Result
- Custom Sort in Acyclic Digraph
- Sort Letters in a Phrase using T-SQL
- Transact-SQL Portal