SQL Server: Internals of a change of the size of a fixed data type
Introduction
Real world requirements change. It is all too common for that the meta data of an existing relation has to change due to new requirements to the business process, more data, etc. The MS SQL Server database administrator or developer can change this meta data (DDL) by using ALTER TABLE ... ALTER COLUMN. With only a few records in the table this data definition change is quite simple but it need careful planning if a table contains millions of records.
This article describes the work process of Microsoft SQL Server in detail so the reader may understand precisely what happens inside the SQL Server engine when changing the data size of a fixed length data type.
Note
The underlying code is using partially undocumented commands like fn_dblog,
sys.system_internals_partition_columns. Please keep in mind that these commands are not officially supported by Microsoft. It is recommended NOT to use these commands on production database.
Environment for test
For the demonstration of the work process inside Microsoft SQL Server a table structure with three columns (all fixed length for better demonstration) will be used. This table has 10,000 records stored:
-- if the table already exists it will be dropped first
IF OBJECT_ID('dbo.demo_table', 'U') IS NOT NULL
DROP TABLE dbo.demo_table;
GO
-- Creation of test table for demonstration
CREATE TABLE dbo.demo_table
(
Id INT NOT NULL,
c1 CHAR(2001) NOT NULL DEFAULT ('A'),
c2 DATE NOT NULL
);
GO
-- Clustered Index on date column c2
CREATE UNIQUE CLUSTERED INDEX ix_demo_table_c2 ON dbo.demo_table (c2)
GO
The test table uses a clustered index on the attribute [c2]. Every data record has a fixed size of 2,015 bytes. Every data page contains 4 data records. With 10,000 records the table allocates ~2,500 data pages in the leaf level of the index (See more details concerning index structures here: Index structures).
-- allocated data pages by demo table
SELECT OBJECT_NAME(p.object_id) AS table_name,
au.type_desc,
au.total_pages,
au.used_pages,
au.data_pages
FROM sys.partitions AS P INNER JOIN sys.allocation_units AS AU
ON (p.partition_id = au.container_id)
WHERE p.object_id = OBJECT_ID('dbo.demo_table', 'U');
GO

Based on the definition of the clustered index key a record will be stored with the following format on a data page:
-- internal structure of a data record on a data page
SELECT c.name AS column_name,
c.column_id,
pc.max_inrow_length,
pc.system_type_id,
t.name AS type_name,
pc.leaf_offset
FROM sys.system_internals_partition_columns pc INNER JOIN sys.partitions p
ON (p.partition_id = pc.partition_id) LEFT JOIN sys.columns c
ON (
column_id = partition_column_id AND
c.object_id = p.object_id
) INNER JOIN sys.types AS T
ON (pc.system_type_id = t.system_type_id)
WHERE p.object_id=object_id('dbo.demo_table');

All data types are fixed length data types. The attribute [leaf_offset] stores the offset of each column value of a record. Every data record starts at position 0x4 because the record header consumes 4 bytes. After the date column ([c2]) (3 Bytes) the next column [Id] starts at offset 0x07 with a length of 4 bytes. The content of column [c1] will be stored at offset 0x0B (11).
Independend of the structure of meta data the clustered keys will ALWAYS be stored at the begin of the record structure if the data type of the clustered key is a fixed length data type!
ALTER TABLE ... ALTER COLUMN
The existing data structure of the demo table will be changed for the column [Id]. The existing data type INT (4 bytes) will be changed to BIGINT (8 bytes). Because of the conversion of the data type the new value has to store the double amount of bytes. Because of maximum 8,060 bytes for data on a data page the affected records will not all fit on one page. Because of this phenomenon expensive page splits will happen when changing the data type.
BEGIN TRANSACTION;
-- change of the data type INT to BIGINT
ALTER TABLE dbo.demo_table ALTER COLUMN [Id] BIGINT NOT NULL;
-- How often do we have page splits and how many records are affected?
SELECT Operation, COUNT_BIG(*) AS Num
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE Operation IN
(
'LOP_DELETE_SPLIT',
'LOP_MODIFY_COLUMNS'
)
GROUP BY
Operation;
COMMIT TRANSACTION;

The result of the operation is modification of 10,000 records. Due to the fact that the expansion of the data type for [Id] has doubled the required amount a lot of page splits have occured in the database. Nearly EVERY existing data page in the leaf level was part of an - expensive - page split.
Internal process
The change of the data type is - because of the page splits - a quite expensive operation and would be a much more expensive operation if Microsoft SQL Server would overwrite existing data for the new allocation of space. So Microsoft SQL Server is using another - interesting - process to optimize the process of space allocation for changed data types. The next extract shows the data record information from a data page BEFORE the modification of the data type:
Slot 0 Offset 0x60 Length 2015
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 2015
Memory Dump @0x0000000015E9A060
Slot 0 Column 3 Offset 0x4 Length 3 Length (physical) 3
c2 = 1953-01-01
Slot 0 Column 1 Offset 0x7 Length 4 Length (physical) 4
Id = 2447
Slot 0 Column 2 Offset 0xb Length 2001 Length (physical) 2001
c1 = P46Q7LE7JCKDLJPWX5JRZYKO0297SN5A8TTI3F9SWZTK1JGL66CNZN1R...
<... SNIP ...>
Slot 0 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (0950748c2d13)
After the operation of adjustment of the data type for the attribute [ID] the structure of the record looks quite different:
Slot 0 Column 3 Offset 0x4 Length 3 Length (physical) 3
c2 = 1953-01-01
Slot 0 Column 67108865 Offset 0x7 Length 0 Length (physical) 4
DROPPED = NULL
Slot 0 Column 2 Offset 0xb Length 2001 Length (physical) 2001
c1 = P46Q7LE7JCKDLJPWX5JRZYKO0297SN5A8TTI3F9SWZTK1JGL66CNZN1R...
Slot 0 Column 1 Offset 0x7dc Length 8 Length (physical) 8
Id = 2447
Slot 0 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (0950748c2d13)
The above extract from the page shows the way Microsoft SQL Server processes the request for changing a fixed length data type to a bigger fixed length data type. Based on transactional perspective a "move" of offset would be a disaster. If Microsoft SQL Server would handle the request that way it has to move the data in data page for each single record. The following pictures show the costs Microsoft SQL Server has to handle if the process would be as complicate as described.
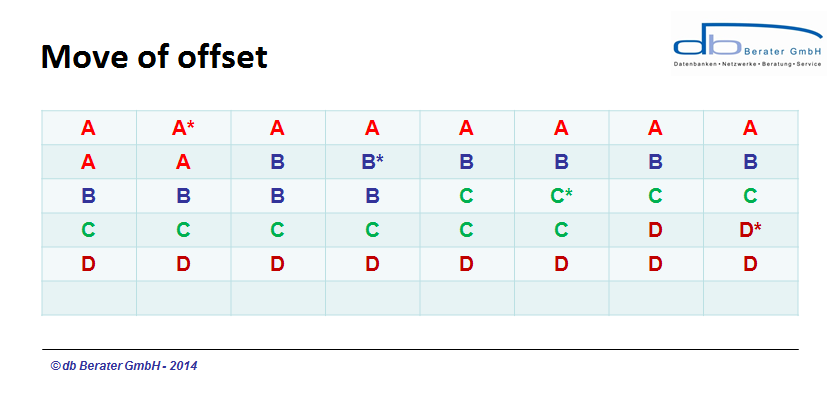
The above picture shows 4 data records on a data page. The offsets marked with * are representing an attributes with a fixed data type (let's say INT) which will be changed to a bigger fixed data type (let's say BIGINT). The new data type need double of the space than the original data type. If Microsoft SQL Server would really allocate space at the existing position of the data page all following records need to be moved forward to free the space.
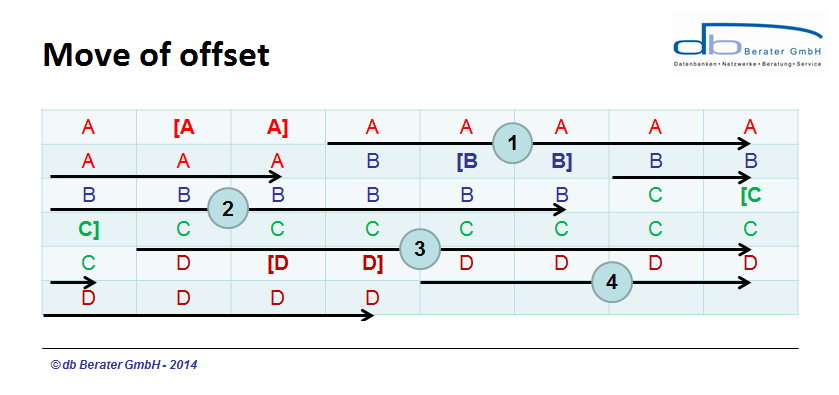
To increase the first record (red), Microsoft SQL Server would be moving partial data from the first record and all other following records to a new position. To change the data size of the second record (blue) Microsoft SQL Server has to touch 2nd record, 3rd record and 4th record again. Same behaviour for the 3rd and the 4th record. If Microsoft SQL Server would really move all existing data the expansion of the column would cause a move of 38 "units" for record A, 28 "units" for the record B, 18 "units" for record C and 8 units for record D; 92 units in total (the "units" are only a fictive measure for demonstration!). Because to avoid such a huge amount of "work and time" and transactional data Microsoft SQL Server is using a different - more effective - strategy.
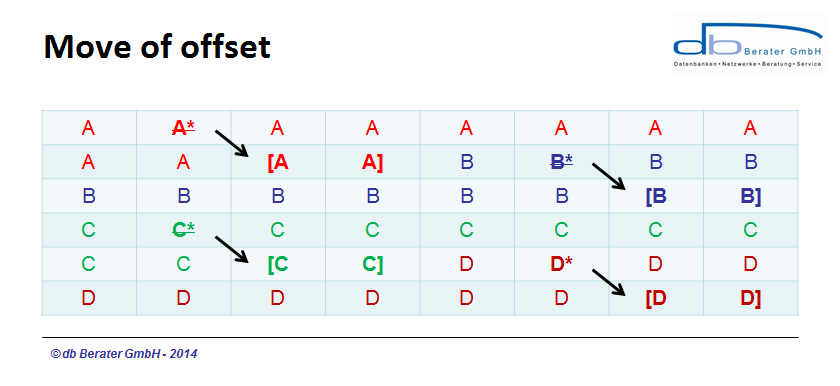
Instead of moving all data to a new location Microsoft SQL Server allocates new space at the end of the existing record. The original allocated space will be marked as "DROPPED". The new space for the column will be allocated at the end of the fixed length data portion of the record. If the records doesn't fit on the page a page split will occur. By usage of this kind of process Microsoft SQL Server will avoid transactional overhead. By investigation of the record on the data page the process can be tracked.
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 2023
Memory Dump @0x0000000015E9A060
Slot 0 Column 3 Offset 0x4 Length 3 Length (physical) 3
c2 = 1953-01-01
Slot 0 Column 67108865 Offset 0x7 Length 0 Length (physical) 4
DROPPED = NULL
Slot 0 Column 2 Offset 0xb Length 2001 Length (physical) 2001
c1 = 7O9E4PMJ0SEX8N6PN2GPC54XBNY65LOQG1TU4LXJKIKPLYY4JAB...
<;... SNIP...>
Slot 0 Column 1 Offset 0x7dc Length 8 Length (physical) 8
Id = 2447
Slot 0 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (0950748c2d13)
The above extract of the data page contains lots of information about the process. First - important - point is the growth of the record by 8 bytes instead of - estimated - 4 bytes! The change of the data type INT (4 bytes) to BIGINT (8 bytes) should result in a growth of 4 bytes, shouldn't it? The reason for that difference is the deactivation of the original position of the value (red marked). The physical amount of space will not be freed but only be deactivated. The existing record will get another 8 bytes for the newly added attribute (blue marked) which represents the column 1 of the table. The original physical order of the columns was [c2], [Id], [c1]. By the the extension of the data type this physical position has changed to the following order.
-- Internal structure of the data page
SELECT c.name AS column_name,
c.column_id,
pc.max_inrow_length,
pc.system_type_id,
t.name AS type_name,
pc.leaf_offset
FROM sys.system_internals_partition_columns pc INNER JOIN sys.partitions p
ON (p.partition_id = pc.partition_id) LEFT JOIN sys.columns c
ON (
column_id = partition_column_id AND
c.object_id = p.object_id
) INNER JOIN sys.types AS T
ON (pc.system_type_id = t.system_type_id)
WHERE p.object_id=object_id('dbo.demo_table');

The original position of the column [Id] has been released/deactivated by Microsoft SQL Server but the amount of space has not been freed. The record still consumes the 4 bytes of data at position 0x07. The column [Id] has been recreated at the end of the fixed length data portion of the record which is the fourth position. The offset of the new data portion of the record starts at 0x07DC (2012) and consumes additional 8 bytes for the storage of the data.
How to release the allocated free space?
To release the formerly allocated space in the records an INDEX REBUILD will help. The INDEX REBUILD will free the allocated space and arrange the columns to its original order.
ALTER INDEX ix_demo_table_c2 ON dbo.demo_table REBUILD;

Conclusion
Changes of meta data are always fully logged transactional operations. Therefore a meta data change should be a detailed planned process in case of huge data amounts. The following topics should be checked before the implementation of the changes:
- well sized transaction log file to avoid autogrowth operation while changing the data type
- Analysis of the number of allocated data pages for all indexes which use the affected column
- Analysis of the record size to calculate the maximum number of records on a data page
- REBUILD of affected indexes before the meta data change with an appropriate FILLFACTOR to avoid page splits
Example for calculation of appropriate FILLFACTOR
An index stores 100,000 data records. One data record has a size of 400 bytes. Based on that information 20 data records fit on one data page. The change of a data type INT to BIGINT requires 20 * 8 = 160 bytes additional space on the data page! A FILLFACTOR of 5% is a good starting point for the transaction.
The complete process of meta data change is separated into four steps:
- growth of transaction log to appropriate size
- rebuilding of index(es) with a FILLFACTOR of 5%
- change of the data type
- rebuilding of index(es) without FILLFACTOR
See also
Pages and Extents architecture: http://technet.microsoft.com/en-us/library/cc280360.aspx
Anatomy of a data page (Paul Randal): http://www.sqlskills.com/blogs/paul/inside-the-storage-engine-anatomy-of-a-page/
Anatomy of a data record (Paul Randal): http://www.sqlskills.com/blogs/paul/inside-the-storage-engine-anatomy-of-a-record/