Transact-SQL: Join Order
Background
You can divide the task of "executing a query process around T-SQL" into two groups: (1) Processes that occur in the relational engine, and (2) Processes that occur in the storage engine.
The relational engine is responsible for several processes: (1) parsing the query text, (2) processing the information using the Query Optimizer, which is responsible to generate the Execution plan, and (3) sending the plan (in a binary format) to the storage engine.
The storage engine retrieves or updates the underlying data. The storage engine includes processes such as locking, index maintenance, and transactions.
This article discusses the execution plan, which is generated by the Query Optimizer, while executing queries with Join operations. We will focus on one specific issue: in what order our Join operations will be executed, and how we can control it. We will show you techniques that you can put in your toolkit!
Our Case studies
We will discuss several different specific cases, from the simple query to more complex situations where the execution plan will depend on a lot of variables, such as the table's size and number of rows, the availability of statistics, indexes, key distribution, etc. In the last paragraph, we will try to summarize the golden rules that explain most of the common issues that you'll face.
Default behavior of simple JOIN queries
For this demonstration, we will create three tables. We will populate two tables with a very low number of rows (100 and 500) and the third table with a large number of rows (1000000).
/************************************************************/
/********* Join Order, By Ronen Ariely *********/
/************************************************************/
USE master ;
GO
CREATE DATABASE JoinOrderDB
ON
( NAME = Sales_dat,
FILENAME = 'G:\SQL\Databases\JoinOrderDB.mdf',
SIZE = 2 GB,
MAXSIZE = 3GB,
FILEGROWTH = 250MB )
LOG ON
( NAME = Sales_log,
FILENAME = 'G:\SQL\Databases\JoinOrderDB.ldf',
SIZE = 1GB,
MAXSIZE = 2GB,
FILEGROWTH = 100MB ) ;
GO
use JoinOrderDB
GO
/**************************************************** DDL - Create tables */
IF OBJECT_ID('T1', 'U') IS NOT NULL DROP TABLE T1;
IF OBJECT_ID('T2', 'U') IS NOT NULL DROP TABLE T2;
IF OBJECT_ID('T3', 'U') IS NOT NULL DROP TABLE T3;
CREATE TABLE T1 (
ID INT IDENTITY CONSTRAINT PK_T1 PRIMARY KEY,
MyValue bigint
)
CREATE TABLE T2 (
ID INT IDENTITY CONSTRAINT PK_T2 PRIMARY KEY,
MyValue bigint
)
CREATE TABLE T3 (
ID INT IDENTITY CONSTRAINT PK_T3 PRIMARY KEY,
MyValue bigint
)
GO
/**************************************************** DML - Populate Tables*/
SET NOCOUNT ON;
insert T1 (MyValue)
select top 100 CAST(CHECKSUM(NEWID()) AS bigint)
from dbo.Numbers
GO
insert T2 (MyValue)
select top 500 CAST(CHECKSUM(NEWID()) AS bigint)
from dbo.Numbers
GO
insert T3 (MyValue)
select top 1000000 CAST(CHECKSUM(NEWID()) AS bigint)
from dbo.Numbers
GO
Let's examine the influence of the Join order in the query, to the Join operation order in the execution plan. First, we will check the JOIN using two small tables.
Please execute the next queries and examine the Execution plan.
SELECT T1.ID, T2.MyValue
FROM T2
INNER JOIN T1
ON T1.ID = T2.ID
GO
SELECT T1.ID, T2.MyValue
FROM T1
INNER JOIN T2
ON T1.ID = T2.ID
GO
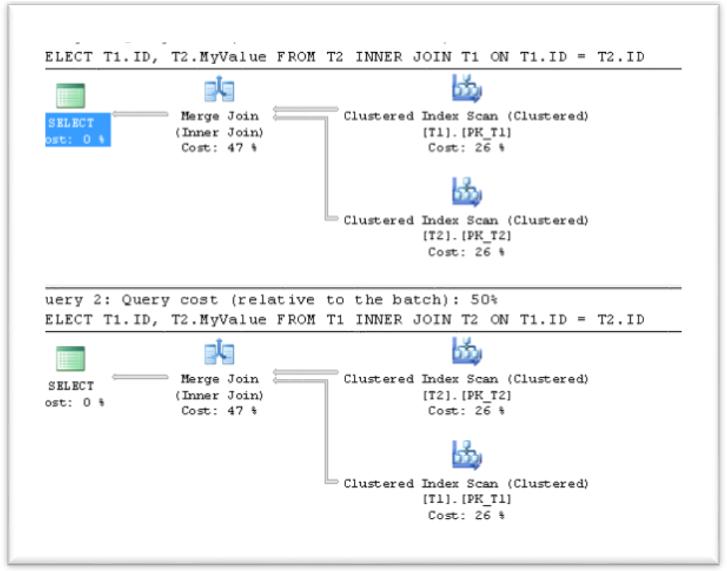
Note
>> You can repeat the execution of each query in this article with the setting "SET SHOWPLAN_ALL ON". This causes Microsoft SQL Server not to execute Transact-SQL statements. Instead, SQL Server returns detailed information about how the statements are executed and provides estimates of the resource requirements for the statements.
Notice that while joining the two small tables of the same size order, the join order in the execution plan fits to the join order in our query. Will it be the same if we join tables that have a substantial difference in their amount of rows?
SELECT T1.ID, T3.MyValue
FROM T3
INNER JOIN T1
ON T1.ID = T3.ID
GO
SELECT T1.ID, T3.MyValue
FROM T1
INNER JOIN T3
ON T1.ID = T3.ID
GO
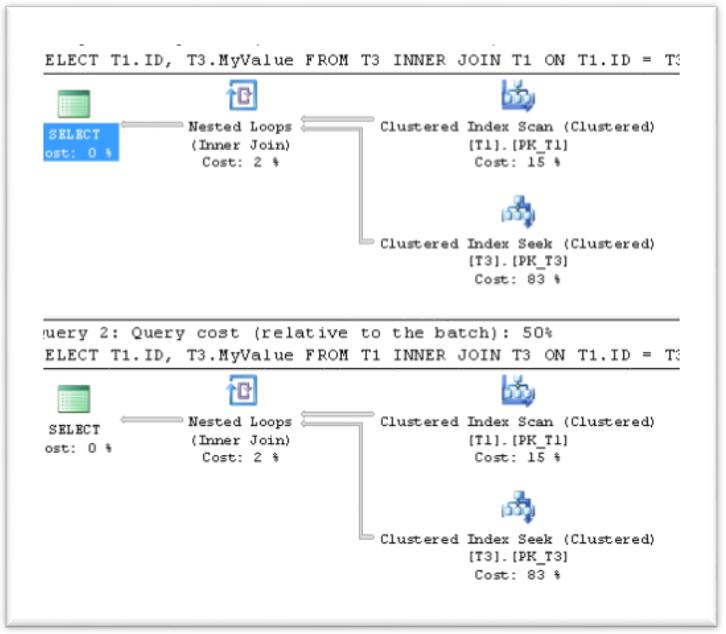
It's obvious that in this case the Query Optimizer chooses to use the small table first, and in both cases we get the same Execution plan, regardless of the join order in the query. Let's now join three tables together and examine the execution plan:
select T1.MyValue, T2.MyValue, T3.MyValue
from T3
join T2 on T2.ID = T3.ID
join T1 on T1.ID = T2.ID
GO
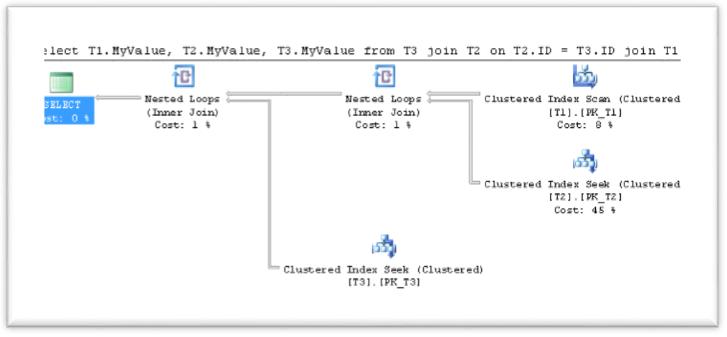
Notice that the Query Optimizer has changed the join order from T3->T2->T1 into T1->T2->T3. This behavior fits our preview conclusion in Demo_01, that the execution order fits to the number of rows in our tables and our join operations are ordered from the smallest to the largest SET.
Basic Controlling of the Join order
The query optimizer should be intelligent enough to figure out the best order in which to execute the steps necessary to translate your logical instructions into a physical result. It uses the stored statistics that the database maintains on each table to determine what to do (what type of join logic to use for example), as well as what order to perform the operations in, in order to minimize Disk IOs and the processing costs.
In some cases, we will need to have the Query Optimizer keep our query order of operations.
Query Optimizer Rules and Query Hints
The query optimizer uses different rules when exploring different plans to evaluate. For example: SelectToFilter, AppIdxToApp , JoinToIndexOnTheFly, JoinCommute, and so on. We can turn rules off using the rule name and the QUERYRULEOFF hint. The rule called JoinCommute is responsible to the join order in our case, and we can actually turn it off.
Note
The execution plan doesn’t expose the ability to selectively enable or disable rules available to the optimizer. We can, however, use a couple of undocumented DBCC commands and the undocumented dynamic management view (sys.dm_exec_query_transformation_stats) to explore the way the optimizer uses rules. (Check the "Resources and More Information" section, Inside the Optimizer: Constructing a Plan, by Paul White). The execution plan doesn’t expose the ability to selectively enable or disable rules available to the optimizer.
Force Order Hint
It specifies that the join order indicated by the query syntax is preserved during query optimization. Using FORCE ORDER does not affect a possible role-reversal behavior of the query optimizer. We can examine the use of the "FORCE ORDER" hint on our queries.
Let's execute the same query, which uses the big table first, but in this case we will use the "FORCE ORDER" hint:
SELECT T1.ID, T3.MyValue
FROM T3
INNER JOIN T1
ON T1.ID = T3.ID
OPTION (FORCE ORDER)
GO
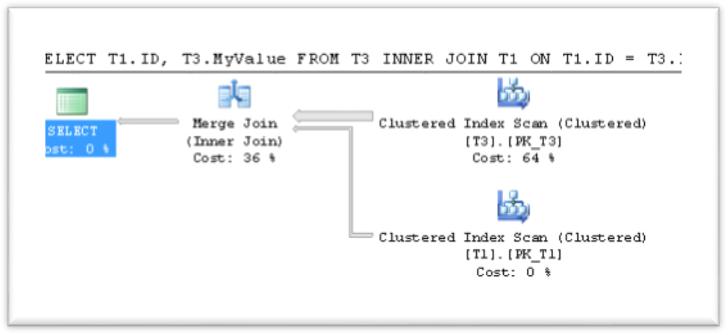
Using Force Order in our three-tables join:
select T1.MyValue, T2.MyValue, T3.MyValue
from T3
join T2 on T2.ID = T3.ID
join T1 on T1.ID = T2.ID
OPTION (FORCE ORDER)
GO
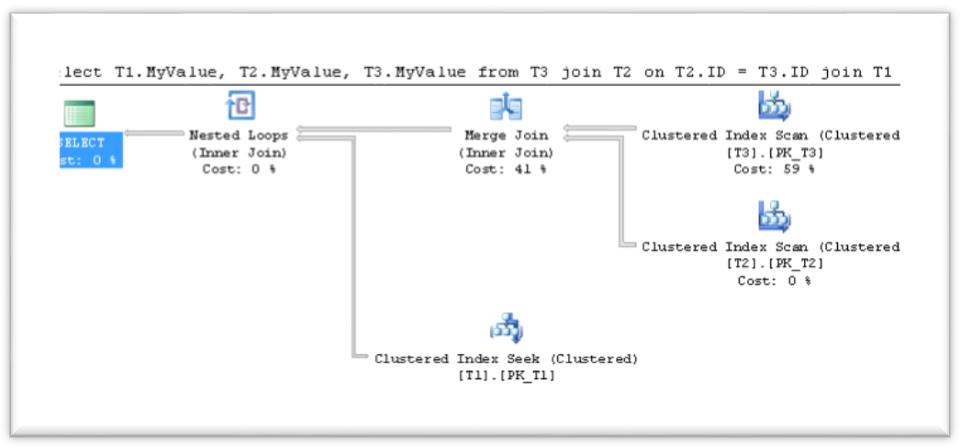
As expected, using the Force Order hint, both queries executed in the order that the queries were written.
Complex JOIN queries & Controlling the Join order
In this section, we are going to examine the behavior of three tables in relation to one another. We will start with DDL + DML, and then we will move to discuss several JOIN cases related to those tables.
/************************************************************/
/********* Join Order, By Ronen Ariely *********/
/************************************************************/
/**************************************************** DDL - Create tables */
IF OBJECT_ID('Entities', 'U') IS NOT NULL DROP TABLE T1;
IF OBJECT_ID('Countries', 'U') IS NOT NULL DROP TABLE T2;
IF OBJECT_ID('EntityOrders', 'U') IS NOT NULL DROP TABLE T3;
GO
CREATE TABLE Entities
(
EID INT NOT NULL IDENTITY PRIMARY KEY,
ENAME NVARCHAR(10) NOT NULL
)
GO
CREATE TABLE Countries
(
CID INT NOT NULL IDENTITY PRIMARY KEY,
CNAME VARCHAR(50) NOT NULL
)
GO
CREATE TABLE EntityOrders(
EOID INT NOT NULL IDENTITY PRIMARY KEY,
EntityID INT NOT NULL,
CountyID INT NOT NULL,
EOPrice DECIMAL(18,3) NOT NULL
);
GO
-- Foreign Key Constraints
ALTER TABLE EntityOrders
ADD CONSTRAINT FK_Entity FOREIGN KEY(EntityID) REFERENCES Entities(EID);
GO
ALTER TABLE EntityOrders
ADD CONSTRAINT FK_Country FOREIGN KEY(CountyID) REFERENCES Countries(CID);
GO
/**************************************************** DML - Populate Tables*/
INSERT INTO Entities (ENAME) VALUES ('E-1'),('E-2'),('E-3');
INSERT INTO Countries (CNAME) VALUES ('IL'), ('US'), ('FR');
INSERT INTO EntityOrders(EntityID, CountyID,EOPrice) VALUES (1, 1, 20),(2, 3, 200);
GO
Query 1: Execute a simple Join query using the relations:
-- Here we try to use: [Entities] JOIN [EntityOrders] JOIN [Countries]
SELECT *
FROM Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN Countries AS c ON b.CountyID = c.CID;
-- but we get: [EntityOrders] JOIN [Entities] JOIN [Countries]
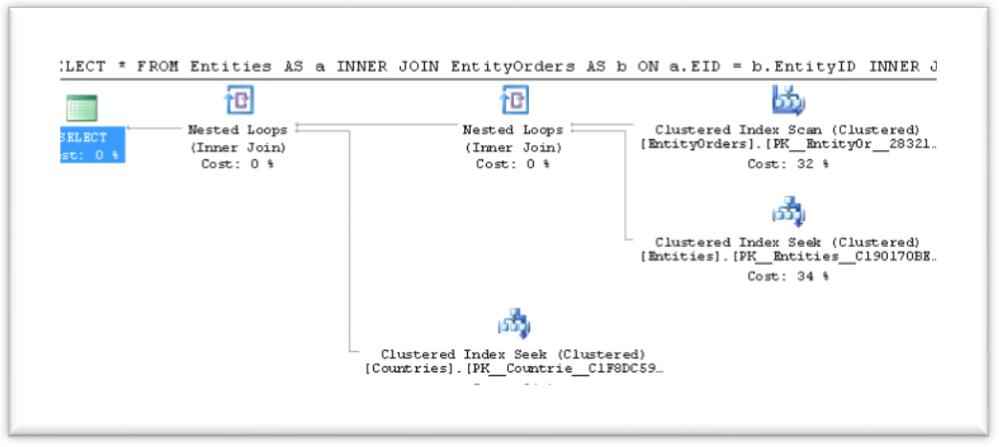
Query 2: Execute the same Join query with a QUERYRULEOFF JOINCOMMUTE hint:
SELECT *
FROM Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN Countries AS c ON b.CountyID = c.CID
OPTION ( QUERYRULEOFF JoinCommute);
-- Now we get: [Entities] JOIN [EntityOrders] JOIN [Countries]
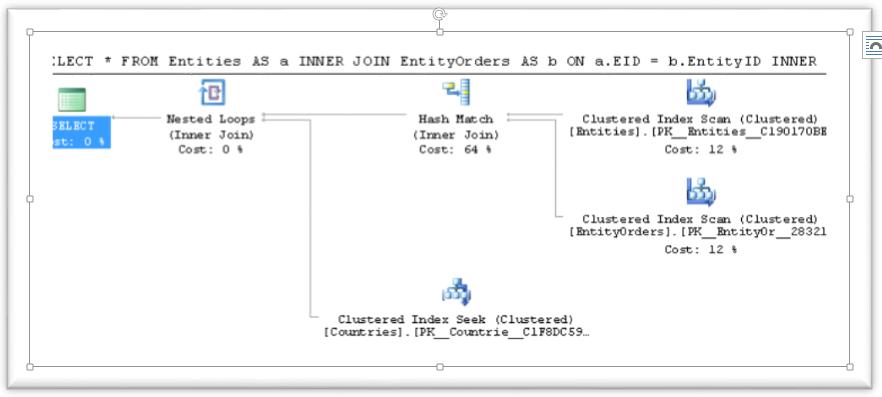
Query 3: Execute the same Join query with a FORCE ORDER hint:
SELECT *
FROM Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN Countries AS c ON b.CountyID = c.CID
OPTION ( FORCE ORDER);
-- Now we get: [Entities] JOIN [EntityOrders] JOIN [Countries]
* The execution plan is the same as in the preview query.
Query 4: Execute the same Join query with a JOIN type hint:
SELECT *
FROM Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN Countries AS c ON b.CountyID = c.CID
OPTION (MERGE JOIN);
-- Now we get: [Countries] JOIN [Entities] JOIN [EntityOrders]
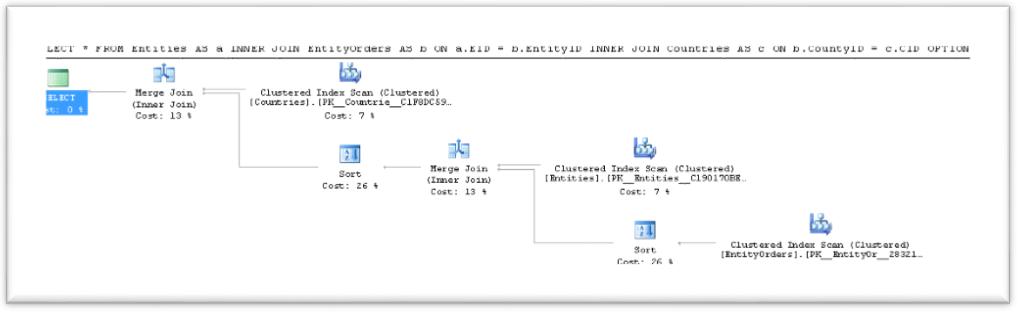
Query 5+6: Execute the same Join query using Brackets and Filter to control the JOIN order:
SELECT *
FROM Entities AS a
INNER JOIN (
select *
from EntityOrders as b
INNER JOIN Countries AS c ON b.CountyID = c.CID
where c.CID < 10
) T on a.EID = T.EntityID
-- Now we get: [EntityOrders] JOIN [Countries] JOIN [Entities]
* in this query we use a filter which actually do not filter any row out. It is only used for re-ordering the JOIN order.
Same solution can be done using this query:
SELECT *
FROM
Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN (
select *
from Countries c
where c.CID < 10
) T ON b.CountyID = T.CID
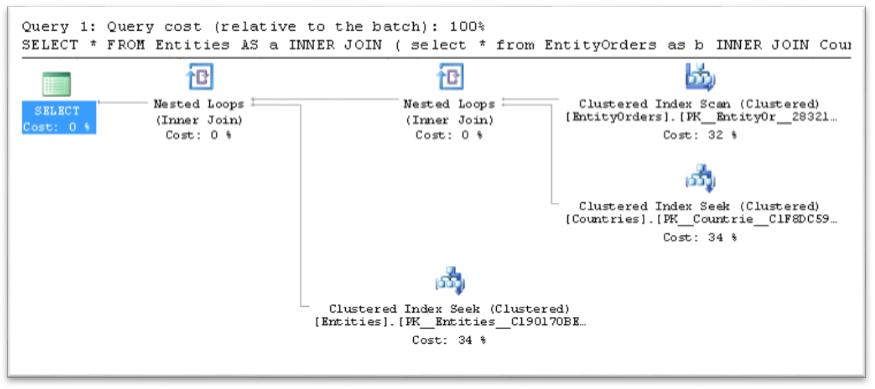
Query 7: Execute the same Join query using GROUP BY to control the JOIN order:
SELECT *
FROM
Entities AS a
INNER JOIN EntityOrders AS b ON a.EID = b.EntityID
INNER JOIN (
select MIN(c.CID) CID,CNAME
from Countries c
group by c.CNAME
) T ON b.CountyID = T.CID
We can force the optimizer to process a derived table by simply placing a GROUP BY in your derived table. The optimizer is then obligated to resolve the GROUP BY aggregate before it can consider resolving the join between the two tables.
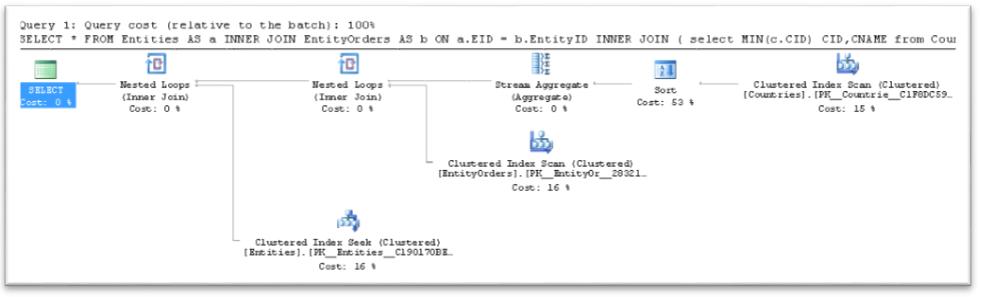
* We can find many more ways to influence the order of operations. As long as we control the understanding of order of operations on the server, then we have a way to change this order. To start out, it would be good to look up the order in which Query Optimizer basically build the execution plan:
- FROM clause
- WHERE clause
- GROUP BY clause
- HAVING clause
- SELECT clause
- ORDER BY clause
Note
* This article is based on SQL Server 2014 Enterprise edition, using a small virtual machine with 2 CPUs and 4 GB of shared memory, on Windows Server 2012 R2.
* We can't always predict the join order, and you might get different results from those shown in this article!
Conclusions and General Rule of Thumb
We saw that the execution plan depends on lot of variables, such as table size and number of rows, availability of statistics, indexes, key distribution, etc. Moreover, we have a lot of options to change order of operation or even the whole Execution plan by using hints and/or writing the same query with a slightly different format.
This list summarize several options we can put in our toolkit for future use:
- By default, JOINs are done in left to right order.
- Tables with less amount of rows pushed to the beginning of the process.
- In extreme situations with complex JOIN query, The Optimizer may fail to find the best solution, and it build an Execution Plan with order of operation almost similar to the original query.
Since the Execution plan depended on huge amount of variables which part of them we can control or know but lot of them we have no way to control or even know about, this is impossible to write rules that will be applied always. Remember that same query on different database can result in different execution plan, and different order of joins. We can however write some General Rule of Thumb (Golden rules) which work in most cases:
- We can try to change the order of JOINs in the query.
- We can control the Join Order using hints as QUERYRULEOFF JOINCOMMUTE, FORCE ORDER, etc.
- We can use different Join hints to control the type of join, which have side effect of changing the join operations order as well.
- We can control order of operation by using Brackets, Filters, GROUP BY, and so on.
Resources and More information
Code
- The full code with all the scripts can be downloaded from the Gallery
http://gallery.technet.microsoft.com/Transact-SQL-Join-Order-e1175937
Resource
More information
- Execution Plan Basics:
https://www.simple-talk.com/sql/performance/execution-plan-basics/
* Very nice blog, clear and intuitive explanation. - More Undocumented Query Optimizer Trace Flags:
http://www.benjaminnevarez.com/2012/04/more-undocumented-query-optimizer-trace-flags/ - Inside the Optimizer: Constructing a Plan - Part 2, by Paul White:
http://sqlblog.com/blogs/paul_white/archive/2010/07/29/inside-the-optimiser-constructing-a-plan-ii.aspx - Inside the Optimizer: Constructing a Plan – Part 4:
http://sqlblog.com/blogs/paul_white/archive/2010/07/31/inside-the-optimiser-constructing-a-plan-part-4.aspx - Query Hints (Transact-SQL):
http://msdn.microsoft.com/en-us/library/ms181714.aspx
See Also
- SQL Server Query Language - Transact-SQL
- Crazy TSQL Queries play time
Include several JOIN playing and example