Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Introduction
Predicates are used for selection of data from tables based on given arguments. These predicates will be used in the WHERE statement. Depending on the selectivity of an index Microsoft SQL Server has to access several data pages for returning the result of the query to the application which requested these data. This article will describe circumstances when wrong selected data types for the predicates will force a much higher data access (IO) than expected.
How does Microsoft SQL Server search for data?
Data are stored on data pages. When Microsoft SQL Server is looking for data it accesses these data pages. Every single data page access is described as 1 IO. Such a data page has a size of 8.192 bytes and can use as greatest possible 8.060 bytes for data, 36 bytes for the Slot Array and 96 bytes are used for the page header. For detailed information about the structure of data pages refer to the links at the end of this article. Even if it is the table itself or it is an index - all data are stored on the same kind of data pages. When an index can be used for the determination of the requested data the great benefit is that the produced IO can be quite less instead of a scan of the whole table. Whether an index can be used optimal or not includes the correct selected data type for the query predicates as the following example will demonstrate.
Test Environment
The test will use one single table with a clustered index on two columns of the table. The data for the first column have a very low selectivity while the values for the second column are very high selective.
CREATE TABLE dbo.demo_table
(
c1 int NOT NULL,
c2 varchar(10) NOT NULL,
c3 char(1000) NOT NULL DEFAULT ('Filler'),
CONSTRAINT pk_demo_table PRIMARY KEY CLUSTERED (c1, c2)
);
GO
/* Filling the table with 1000 records */
DECLARE @i int = 1;
WHILE @i <= 1000
BEGIN
INSERT INTO dbo.demo_table (c1, c2) VALUES (1, @i);
SET @i += 1;
END
GO
/* Rebuild the index for compression of data pages */
ALTER INDEX pk_demo_table ON dbo.demo_table REBUILD;
GO
The above script creates the table [dbo].[demo_table] with a clustered index on the columns [c1] and [c2]. When the table has been created 1,000 records will be inserted into it. Please note that the value for [c1] column is always 1 and note that [c2] has a data type of varchar. The next script shows the internal structure (pages) where the data are stored.
SELECT OBJECT_NAME(p.object_id) AS object_name,
au.type_desc,
au.data_pages,
au.used_pages,
au.total_pages
FROM sys.allocation_units AS au INNER JOIN sys.partitions AS p
ON (au.container_id = p.partition_id)
WHERE p.object_id = OBJECT_ID('dbo.demo_table', 'U');
GO

All 1,000 records are stored in 145 data pages. 143 data pages are allocated in total which means 1 additional data page for the root-node (B-Tree) and the IAM-page (index allocation map).

When an application requests data from a Microsoft SQL Server table the selectivity of the predicates determine the amount of pages it has to touch for the data. For the first example keep in mind that column [c1] will have a very high selectivity because only one single value is available.
SET STATISTICS IO ON;
SELECT * FROM dbo.demo_table WHERE c1 = 1;
SET STATISTICS IO OFF;
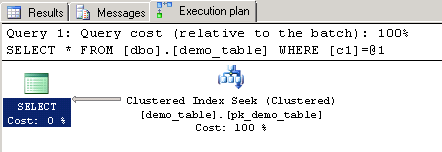
The execution plan for this query shows an “index seek” although Microsoft SQL Server is starting at the beginning of the index and has to go through every record. But because the query is using a predicate on the very first key column of the index, the Query Optimizer is actually doing a seek operation. It’s just a seek operation which has to scan every row of the table. This is what we generally consider to be a scan but not a seek operation. Microsoft SQL Server has to go through the complete table and the IO consumes 145 pages because the IAM has to be read and from the root node of the index all data pages have to be scanned by the query execution engine.
The result is expected because only the first column of the table has been used as a predicate for the results. With the next example the selectivity will be very high because the combination of [c1] and [c2] is unique. The first query will use the numeric value 1 as predicate for the column [c2] while the second query will use the varchar value “1” as value for the predicate.
SET STATISTICS IO ON;
SELECT * FROM dbo.demo_table WHERE c1 = 1 AND c2 = 1;
SELECT * FROM dbo.demo_table WHERE c1 = 1 AND c2 = '1';
SET STATISTICS IO OFF;
First picture shows the execution plan for both queries and the significant difference in the estimated execution costs seems evident.

While the first query seems to consume 97% of the whole batch the second one only consumes just traction of the consumed resources. Both queries are using obviously the same index strategy (an index seek operation). The next paragraph shows the result of the IO and it is obviously huge difference in the produced IO between both queries:
Table 'demo_table'. Scan count 1, logical reads 145, ...
Table 'demo_table'. Scan count 0, logical reads 2, ...
While the first query crawls through the whole bunch of data pages (145) the second query could use the index in a much more efficient way.
Explanation
By looking at the execution plan the first query seems to use an index seek operation but it crawls through the whole data pages instead of using a speedy seek operation. The reason for this dramatic degree of performance is the “residual predicate”. The following picture shows the details for the index seek operation for the first and the second query.

The left details show an implicit converting of the attribute [c2] while the right one can use the predicate for [c2] as a seek predicate. In the moment a column value itself will be converted the query is “non sargable” which leads to a scan instead of a seek operation. It has to scan the result set which has been filtered by the “seek predicate” and this bunch of data has to be filtered in a separate operation. Concerning the concrete example the column [c2] has a data type varchar(10) but the query is using a tinyint (because the value is 1). So Microsoft SQL Server has to convert the column values to an integer data type and the given value itself has to be changed to an integer data type, too. That’s the operation which takes place in the residual predicate. With a small hint in the query this – expensive – operation can be made visible. The above two queries will be used again but now with the – undocumented - traceflag 9130!
SELECT * FROM dbo.demo_table WHERE c1 = 1 AND c2 = 1 OPTION (QUERYTRACEON 9130);
SELECT * FROM dbo.demo_table WHERE c1 = 1 AND c2 = '1' OPTION (QUERYTRACEON 9130);
The following picture shows the difference in the – usually hidden – filter operation:

Due to the convert operation the whole bunch of data has to be scanned first (here mentioned as a seek operation which is none). After all data have been processed they have to pass a filter which than returns only one single record. The second query is using the correct data type (varchar) for the predicate and that’s the reason Microsoft SQL Server can use an efficient and “real” index seek operation.
Solution
Every developer of such queries needs to be familiar with the meta data structure of the given tables, views and its columns. For the given example the well phrased predicate is as follows:
SELECT * FROM dbo.demo_table WHERE c1 = CAST(1 AS int) AND c2 = CAST(1 AS varchar(10));
The statement converts the predicates to its correct data types and Microsoft SQL Server doesn’t need to run an implicit converting of the data.
Conclusion
When a query runs against the database you have to make sure that the correct data type will be used for predicates. A wrong data type may lead to an operational pitfall because Microsoft SQL Server will use the expected index operation but in the background the “optimal” operation is proved as a quite expensive operation because more records have to be touched than necessary.
See Also
Pages and Extents Architecture: http://technet.microsoft.com/en-us/library/cc280360.aspx
Physical and logical operators: http://technet.microsoft.com/en-us/library/ms191158.aspx
Traceflag 9130: http://sqlblog.com/blogs/paul_white/archive/2012/10/15/cardinality-estimation-bug-with-lookups-in-sql-server-2008-onward.aspx
Information
Some of the above coded examples are using the undocumented TraceFlag 9130. Using undocumented functions does not mean vulnerability but you won't get any support about these commands from Microsoft. Although their usage is safe, keep in mind to use it in test environments only to avoid any impact to production processes. This wiki article is based on a a question in the MSDN forum which you can find here: