A Practical Example of How to Handle Simple Many to Many Relationships in Power Pivot/SSAS Tabular Models
Introduction
There are a number of blogs that provide guidance on how to handle many to many relationships in Power Pivot and SSAS Tabular models using DAX. This article is not introducing anything new with regards to this. However, the example covered in this article may help you to gain a better understanding of how it works, so that you can more easily apply it in your own models. The example used in this article is based on a real world scenario that was presented in the MSDN forums.
The Problem
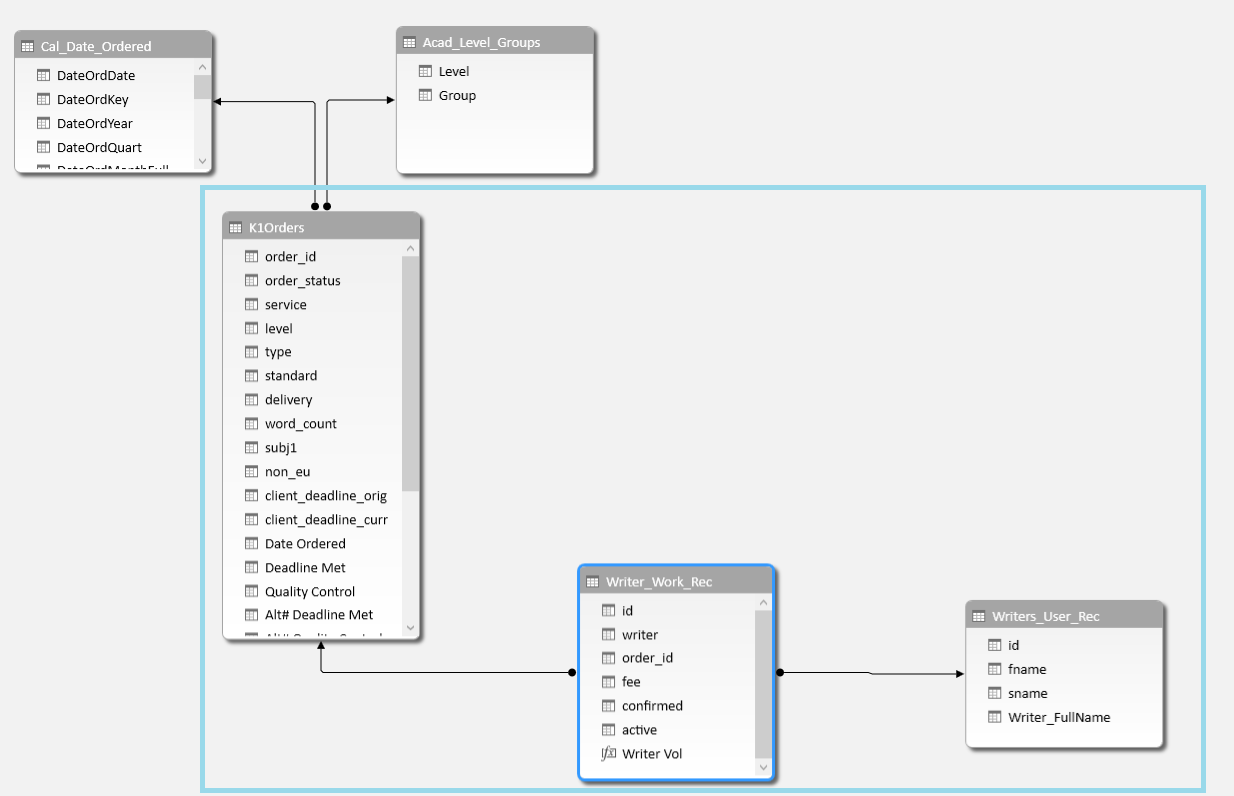
A Power Pivot user has created the above model to represent the following relationships between the tables: K1Orders represents sales. These sales are fulfilled by writers. The Writer_Work_Rec table holds a record of all the writers and the works that they have contributed towards; almost all works are created by more than one writer. The Writer_Work_Rec table links to Writer_User_Rec which contains the names of the writers.
A simple word count measure has been defined as follows:
WordCount:=CALCULATE(SUM(K1Orders[word_count]))
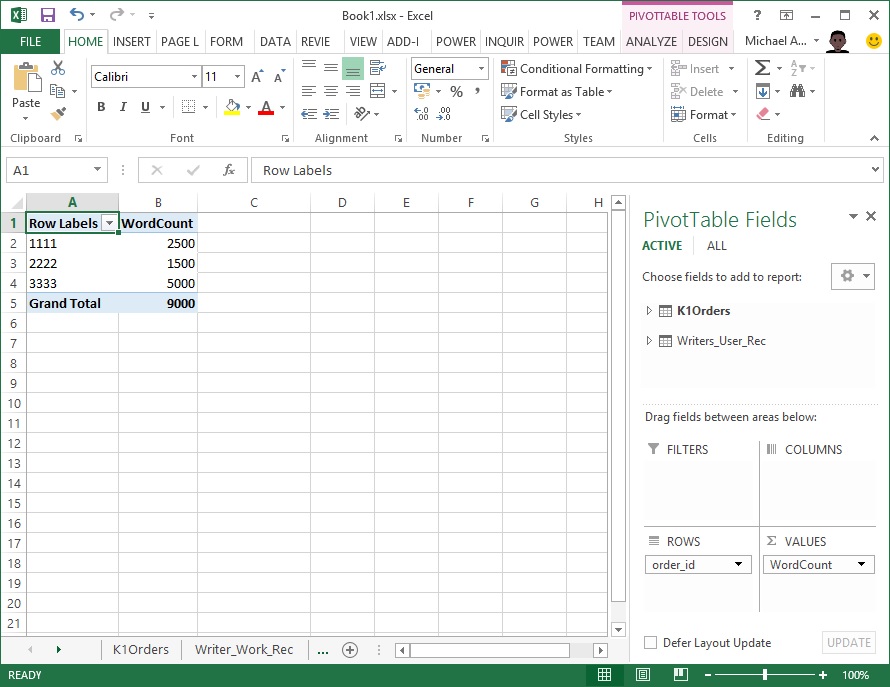
As we would expect, this measure works correctly when we slice it by a column from the K1Orders table:
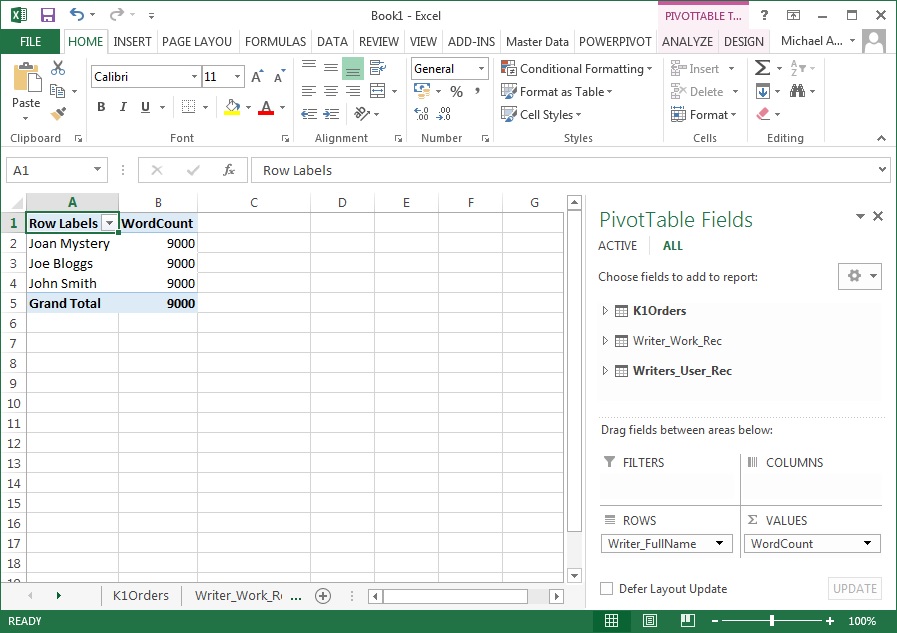
Strangely, when we try to slice this measure by any column from the Writer_User_Rec table, we get the wrong result:
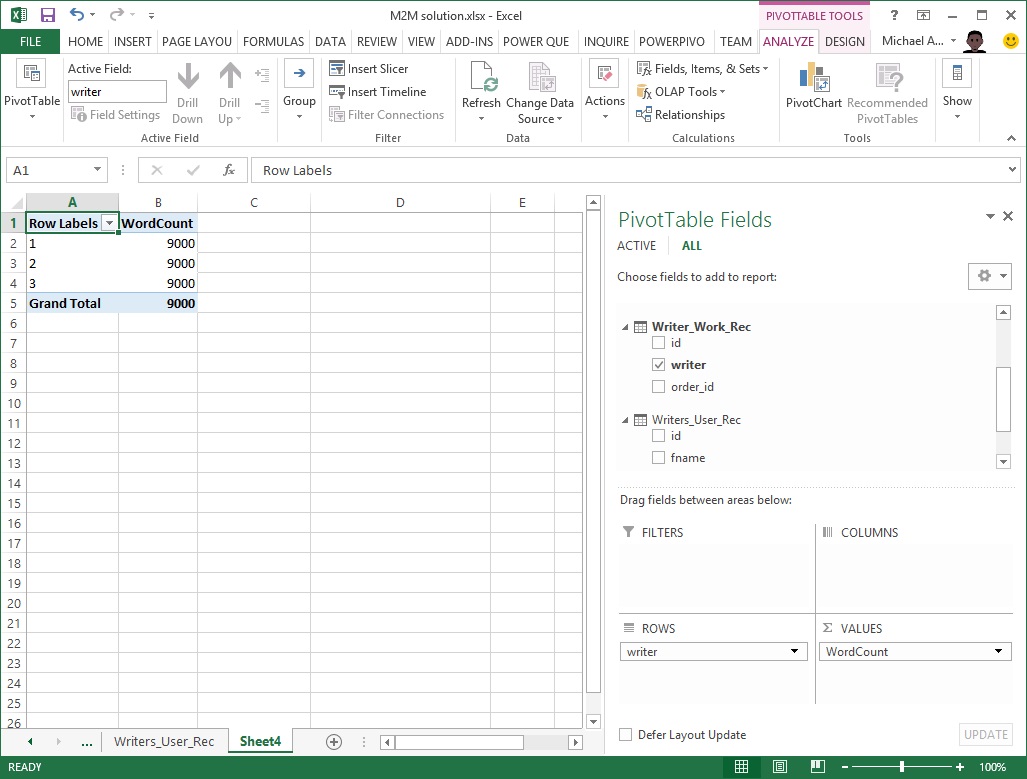
The same incorrect result is produced if we try and slice this same word count measure by a column from the Writer_Work_Rec table:
Read on to find out why this is and how we can solve this problem...
The Solution
The model has a simple many-to-many (M2M) relationship. Power Pivot doesn't support this natively yet; it only supports one to many. It also does not carry across filter contexts going from a 'many' side to the 'one' side, only the 'one' side to the 'many' side. In this scenario, the filter context will carry across (i.e. propagate) from **Writers_User_Rec **to Writer_Work_Rec, but will then be lost when going from **Writer_Work_Rec **to K1Orders. This is why the the word count measure returns the incorrect result when we slice it by any of the columns in the **Writers_User_Rec **or **Writer_Work_Rec **tables.
We can achieve the behaviour that we want by using the CALCULATE and SUMMARIZE DAX functions together. We can use some small test data and a subset of the data model to illustrate this:
K1Orders:
| order_id | word_count |
| 1111 | 2500 |
| 2222 | 1500 |
| 3333 | 5000 |
Writer_Work_Rec:
| id | writer | order_id |
| 1 | 1 | 1111 |
| 2 | 2 | 1111 |
| 3 | 2 | 2222 |
| 4 | 3 | 3333 |
Writers_User_Rec:
| id | fname | sname | Writer_FullName |
| 1 | Joe | Bloggs | Joe Bloggs |
| 2 | John | Smith | John Smith |
| 3 | Joan | Mystery | Joan Mystery |
You will notice that based on the data in these tables, Joe Bloggs and John Smith have co-authored a work of 2,500 words. John Smith has also authored a work by himself of 1,500 words. Joan Mystery has authored a work by herself of 5,000 words.
As mentioned earlier, the filter context is being lost when going from one side of the M2M relationship (via the Writer_Work_Rec which is a bridge table) to the other. If we slightly alter the [WordCount] measure by introducing the SUMMARIZE function, we can force the filter context to be kept when going from **Writers_User_Rec **to **Writer_Work_Rec **to **K1Orders. **This will result in the word count being evaluated correctly for each writer. Here is the formula for a measure that makes the word count measure to be 'M2M friendly':
WordCountM2M:=
CALCULATE(
[WordCount],
SUMMARIZE(
Writer_Work_Rec,
K1Orders[order_id]
)
)
We already know that the filter from the **Writers_User_Rec **is successfully propagated to the **Writer_Work_Rec **table. What the SUMMARIZE does here is to generate a list of all the K1Orders[order_id] values that are related to the **Writer_Work_Rec **table (taking into account any filters that have already been placed on it). It will then use this list to filter the **K1Orders **table before evaluating the [WordCount] measure in this context. The result can be seen below.
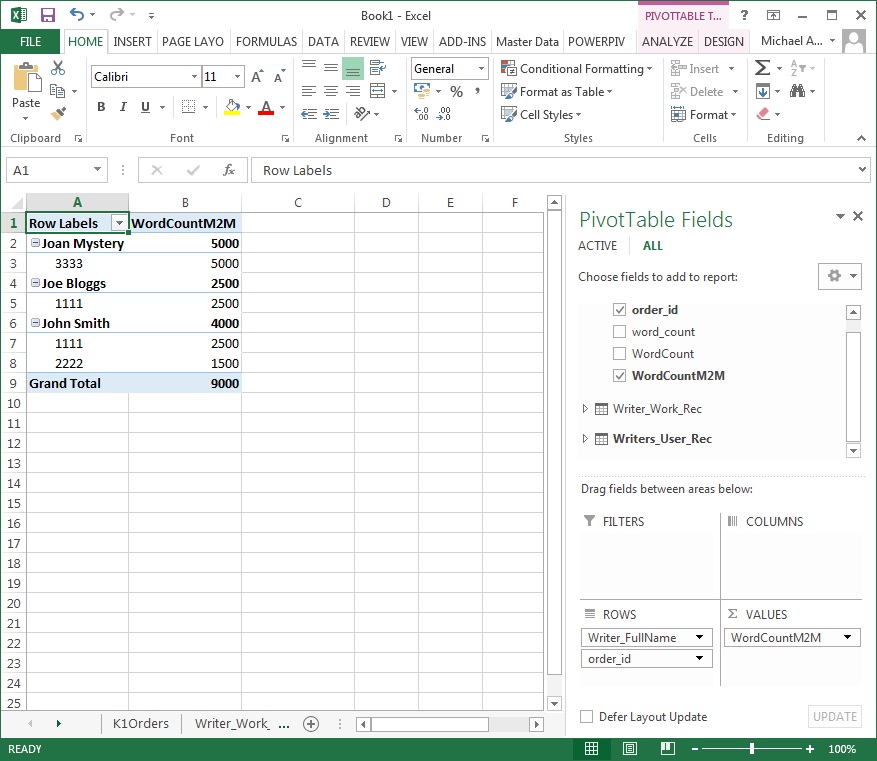
The above DAX formula can be simplified further to the following:
WordCountM2MSimplified:=CALCULATE(
[WordCount],
Writer_Work_Rec
)
Here, we have replaced the SUMMARIZE part of the formula with the name of the table in the first parameter of the SUMMARIZE function, Writer_Work_Rec. The Writer_Work_Rec table preserves the filter context propagated from Writers_User_Rec table and uses this to filter **K1Orders table **before evaluating the [WordCount] measure. As a result, the behaviour is the same as the SUMMARIZE version of the DAX formula.
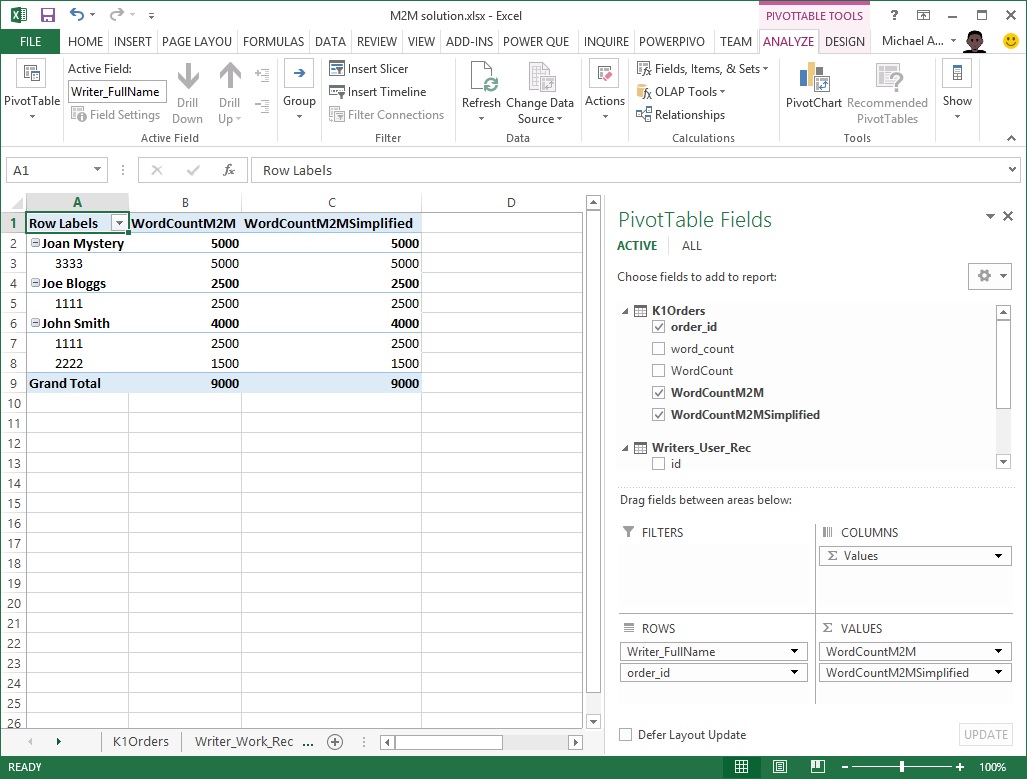
Conclusion
Handling many to many relationships can be quite a complex topic but as you've seen in the given example, it can be implemented using some relatively straight-forward DAX formulas. Hopefully, the article has helped you to understand more about handling simple many to many relationships using DAX, and to begin thinking about how to apply this approach to your own many to many modelling scenarios.
For further reading on this topic, there is a popular whitepaper called 'The Many-to-Many Revolution 2.0' by Marco Russo and Alberto Ferrari: http://www.sqlbi.com/articles/many2many