SQL Server: How does SQL Server Allocate Space in a Heap?
The above question has been raised in an opened thread in the Microsoft Forums. The original question dealt with a problem that an insert operation into a heap has forced a new data page although the inserted records would all fit into one data page. This article describes the internal mechanism Microsoft SQL Server is using when space should be allocated in a heap.
Environment
For the demonstration of the internal process a quite simple table structure will be used
-- Create the table (Heap)
CREATE TABLE dbo.tbl_Heap
(
Id int NOT NULL IDENTITY (1, 1),
c1 varchar(2500) NOT NULL
);
GO
-- Insert 3 records each 2504 bytes
INSERT INTO dbo.tbl_heap(c1) VALUES (REPLICATE('X', 2500));
GO 3
Every data page in a Microsoft SQL Server database follows the same rules. It has a page header which consumes 96 Bytes as well as additional 8.096 bytes for the data and the slot array. The length of each inserted record is 2504 bytes + the overhead for the row structure. If 8.096 bytes are available all three records should be inserted into one data page. A look into the table and its physical location demonstrates that Microsoft SQL has separated the inserted records to two data pages.
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, * FROM dbo.tbl_heap;

The reason for this curious behavior is based on the way Microsoft SQL Server handles data for a heap.
Data Handling for Heaps
A heap is an unordered bunch of data which will be stored by the database engine in an arbitrary process. Records will be inserted into the table in a sequential way but before each INSERT Microsoft SQL Server determine the allocated space for each page. If there is enough space available on the page it will be used and allocated by the newly inserted record.
Exactly at this point the Microsoft SQL Server uses a process which completely distinguishes from the process Microsoft SQL Server is using for a clustered index. In a clustered index the data need to be ordered by the clustered key. When Microsoft SQL Server inserts new data into a clustered index, it goes down to the page where the new record should be inserted, checks the page header for the available free space on the page and - depending on the available storage - saves the record on the page or forces a page split to make room for the new record.
In a heap Microsoft SQL Server does not consider any order because there is none. Therefore Microsoft SQL Server does not check each page for available free space (which will consume lots of time and I/O) but can check the free space for each page on the highest level of the database - it scans the PFS (Page Free Space).
PFS - Page Free Space
The PFS stores information about the allocation of data pages and the allocated space for each page in the database. The first PFS is always at the second position in the database file (Page 1). A PFS can store information for about 8,088 data pages (64 MB). If the limit has reached a new PFS page will be created in the database, which control the allocation and space usage for the next 64 MB of pages. Concerning the space usage of each page Microsoft SQL Server uses the first 3 bit of each byte for the information about the used space.
| Status | used space in percent |
| 0x00 | page is empty |
| 0x01 | 1% - 50% full |
| 0x02 | 51% - 80% full |
| 0x03 | 81% - 95% full |
| 0x04 | 96% - 100% full |
The allocated space on each page can be seen by looking directly on the PFS from the above example.
DBCC TRACEON (3604);
DBCC PAGE ('demo_db', 1, 1, 3);
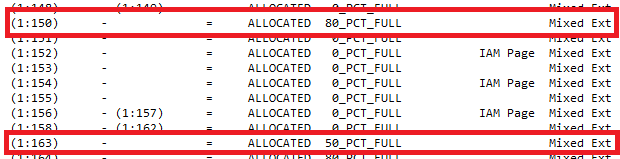
As the above picture shows the data page 150 (which holds the records 1 and 2) consumes app. 80% of the space while the page 163 (which holds the record 3) consumes nearly 50% of the given space. A closer look to the page header of page 150 gives a much deeper look into the space allocation than the PFS will do.
DBCC TRACEON (3604);
DBCC PAGE ('demo_db', 1, 150, 0);
The output of the page header shows the most important information
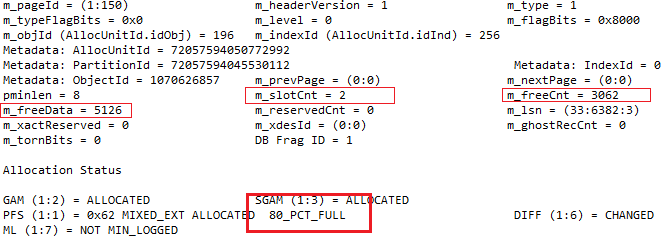
In total there are 2 records stored on the data page (m_slotCnt) and the page has 3,063 bytes available for new records (m_freeCnt). If Microsoft SQL Server will insert a new record into this page, it has to be inserted at the offset 5,126 (m_freeData). Last but not least the page is used by 51% - 80%. If Microsoft SQL Server would read the information from the page header it should be aware of the 3,062 bytes available space on the page. But it doesn't!
The record 3 has a length of 2504 bytes + row overhead but Microsoft SQL Server has not inserted the record on the page 150 because of the following calculation:
The PFS reports a space usage of 80% which mean 6,554 bytes from the complete page space. The free space of the page is 1,638 bytes and the record 3 has a length of 2,504 bytes which does not fit to the page based on these calculation! This calculation is manifesting the PFS scan instead of a dedicated scan of the page header. Because the new record does not fit on the page a new one will be created as the extract from the transaction log will make visible.
SELECT [Current LSN],
Operation,
Context,
AllocUnitId,
AllocUnitName,
[Page ID],
[Slot ID]
FROM sys.fn_dblog(NULL, NULL)
WHERE AllocUnitName = 'dbo.tbl_Heap' OR
Context = 'LCX_PFS'
ORDER BY
[Current LSN];

First of all a new record will be inserted into the table [dbo].[tbl_heap] in Slot 0 (Line 7). Directly after the record has been inserted an update to the PFS occurs (Line 8) and then the second record will be inserted (Line 9). After each insert operation an update of the PFS occurs to reflect the space used on the page. Now the data page consumes over 50% of the available space and when the 3rd insert operation happens it forces the creation of a new data page. When the record has been inserted the PFS will be updated again as it has happened within the two former operations, too.
Conclusion
Heaps are following a completly different way to store data on data pages. While a Clustered Index needs to be accurate in order, a Heap does not require it. The result for it is a quite faster insert operation for new data because there will be less I/O and not the data pages itself must be scanned for free space but only ONE data page - the PFS.
See Also
Information
The above coded examples are using undocumented functions like DBCC PAGE and fn_dblog(). Using undocumented functions does not mean vulnerability but you won't get any support about these commands from Microsoft. Although their usage is safe, keep in mind to use it in test environments only to avoid any impact to production processes.