T-SQL: Simplified CASE expression
The goal of this article is providing explanations about using CASE expression and its alternatives which introduced in SQL Server 2012. This article is completely compatible with SQL Server 2012 and 2014.
Introduction
SQL Server 2012 introduces these two new functions which simplify CASE expression:
- Conditional function ( IIF)
- Selection function ( CHOOSE )
We also have been working with COALESCE, an old simplified CASE expression statement as a NULL-related statement since early versions. Although ISNULL is a function, which logically simplifies a CASE expression, it never translates to a CASE expression behind the scene (by execution plan). By the way, we will also cover ISNULL in this article, as it is an alternative to COALESCE. The goal of this article is providing the in-depth tutorial about these statements:
- ISNULL
- COALESCE
- IIF
- CHOOSE
I prefer using the term “statement” because although they do the similar job, they are not in the same category by their purpose. For example, ISNULL is a function while COALESCE is an expression.
As we will see later, the main purpose of introducing these statements is improving code readability and achieving cleaner code. Using these statements may result in poor performance in some situations. Therefore, we also will discuss alternative solutions.
This article targets all levels of readers: from newbies to advanced. So, if you are familiar with these statements, you may prefer skipping Definition section.
Definition ** **
ISNULL
ISNULL(expr_1, expr_2)
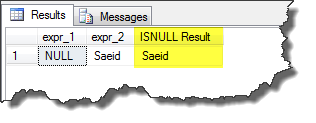
If expr_1 is null, then ISNULL function returns expr_2, otherwise returns expr_1. Following example shows its functionality.
DECLARE @expr_1 NVARCHAR(10) ,
@expr_2 NVARCHAR(10) ;
SET @expr_1 = NULL ;
SET @expr_2 = N'Saeid' ;
SELECT @expr_1 AS expr_1,
@expr_2 AS expr_2,
ISNULL(@expr_1, @expr_2) AS [ISNULL Result]
Output:
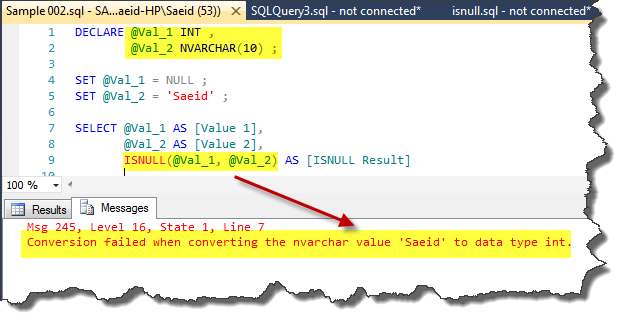
When the data types of two arguments are different, if they are implicitly convertible, SQL Server converts one to the other, otherwise returns an error. Executing follow code results an error as illustrated in output figure.
DECLARE @Val_1 INT ,
@Val_2 NVARCHAR(10) ;
SET @Val_1 = NULL ;
SET @Val_2 = 'Saeid' ;
SELECT @Val_1 AS [Value 1],
@Val_2 AS [Value 2],
ISNULL(@Val_1, @Val_2) AS [ISNULL Result]
Output:
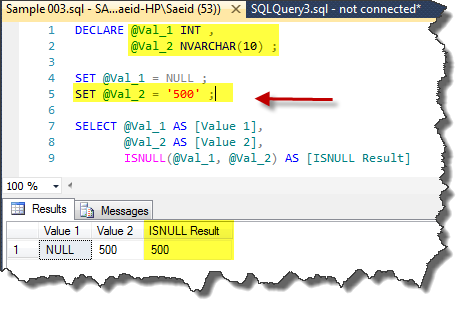
Changing value of variable @Val_2 to ‘500’, we do not encounter any error. Because this value is convertible to numeric data type INT. Following code shows this:
DECLARE @Val_1 INT ,
@Val_2 NVARCHAR(10) ;
SET @Val_1 = NULL ;
SET @Val_2 = '500' ;
SELECT @Val_1 AS [Value 1],
@Val_2 AS [Value 2],
ISNULL(@Val_1, @Val_2) AS [ISNULL Result]
Pic 003
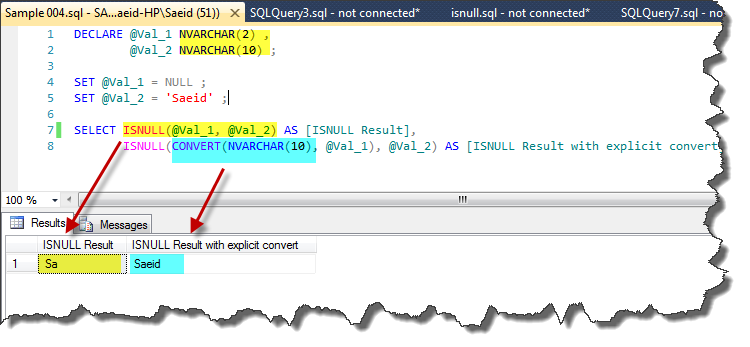
Implicit conversion may lead to data truncation. This will happen if the length of expr_1 data type is shorter than the length of the expr_2 data type. So it is better to convert explicitly if needed. In the next example, first output column suffers from value truncation while second will not.
DECLARE @Val_1 NVARCHAR(2) ,
@Val_2 NVARCHAR(10) ;
SET @Val_1 = NULL ;
SET @Val_2 = 'Saeid' ;
SELECT ISNULL(@Val_1, @Val_2) AS [ISNULL Result],
ISNULL(CONVERT(NVARCHAR(10), @Val_1), @Val_2) AS [ISNULL Result with explicit convert]
Output
Determine output data type
There are few rules to determine output column's data type generated via ISNULL. The next code illustrates these rules:
IF OBJECT_ID('dbo.TestISNULL', 'U') IS NOT NULL
DROP TABLE dbo.TestISNULL ;
DECLARE @Val_1 NVARCHAR(200) ,
@Val_2 DATETIME ;
SET @Val_1 = NULL ;
SET @Val_2 = GETDATE() ;
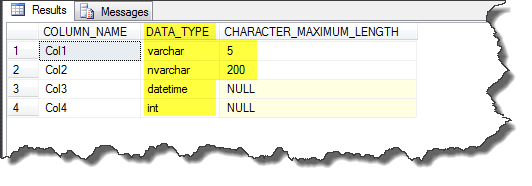
SELECT ISNULL('Saeid', @Val_2) AS Col1,
ISNULL(@Val_1, @Val_2) AS Col2,
ISNULL(NULL, @Val_2) AS Col3,
ISNULL(NULL, NULL) AS Col4
INTO dbo.TestISNULL
WHERE 1 = 0 ;
GO
SELECT COLUMN_NAME ,
DATA_TYPE ,
CHARACTER_MAXIMUM_LENGTH
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'dbo'
AND TABLE_NAME = N'TestISNULL' ;
Output:
Determine output NULL-ability
Follow code illustrates the rules to determine output column data type generated via ISNULL:
IF OBJECT_ID('dbo.TestISNULL', 'U') IS NOT NULL
DROP TABLE dbo.TestISNULL ;
DECLARE @Val_1 NVARCHAR(200) ,
@Val_2 DATETIME ;
SET @Val_1 = NULL ;
SET @Val_2 = GETDATE() ;
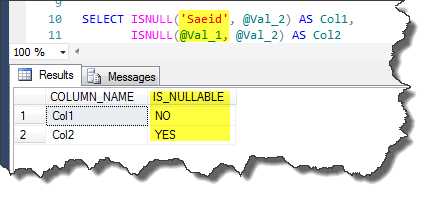
SELECT ISNULL('Saeid', @Val_2) AS Col1,
ISNULL(@Val_1, @Val_2) AS Col2
INTO dbo.TestISNULL
WHERE 1 = 0 ;
GO
SELECT COLUMN_NAME ,
IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'dbo'
AND TABLE_NAME = N'TestISNULL' ;
Output
** COALESCE **
COALESCE(expr_1, expr_2, ..., expr_n) ,(for n >=2)
COALESCE returns the first NOT NULL expression in the expression list. It needs at least two expressions.
Dissimilar from the ISNULL function, COALESCE is not a function, rather it’s an expression. COALESCE always translates to CASE expression. For example,
COALESCE (expr_1, expr_2)
is equivalent to:
CASE
WHEN (expr_1 IS NOT NULL) THEN (expr_1)
ELSE (expr_2)
END
Therefore the database engine handles it like handling a CASE expression. So this is inside our simplified CASE expression list.
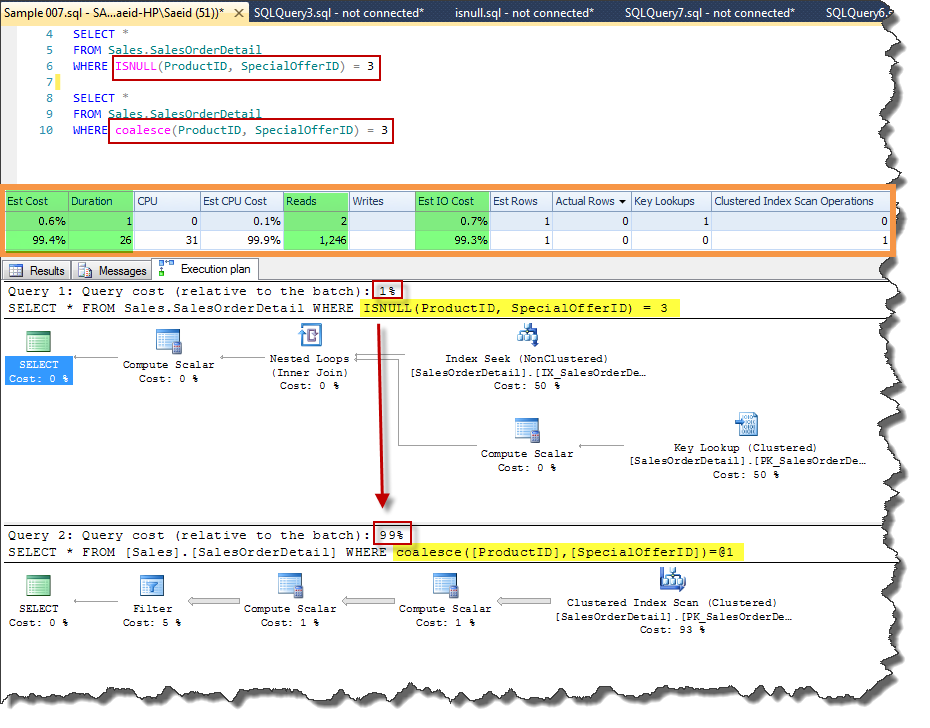
Following code is one of many samples that could illustrate different execution plans for COALESCE and ISNULL:
USE AdventureWorks2012 ;
GO
SELECT *
FROM Sales.SalesOrderDetail
WHERE ISNULL(ProductID, SpecialOfferID) = 3 ;
SELECT *
FROM Sales.SalesOrderDetail
WHERE coalesce(ProductID, SpecialOfferID) = 3 ;
Pic 007
By using COALESCE, we do not have the limitations that discussed about ISNULL function, neither about output column data type nor output column NULL-ability. Even there is no more suffering from value truncation. The next example is the new revision of the ISNULL section examples, but replacing with COALESCE:
-- value truncation
DECLARE @Val_1 NVARCHAR(2) ,
@Val_2 NVARCHAR(10) ;
SET @Val_1 = NULL ;
SET @Val_2 = 'Saeid' ;
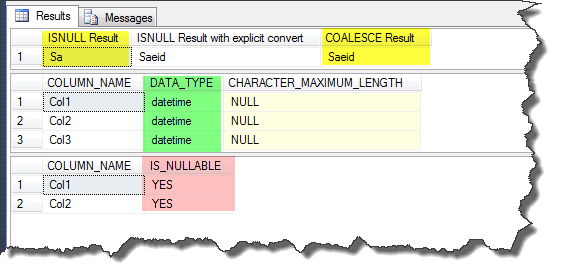
SELECT ISNULL(@Val_1, @Val_2) AS [ISNULL Result],
ISNULL(CONVERT(NVARCHAR(10), @Val_1), @Val_2) AS [ISNULL Result with explicit convert],
COALESCE(@Val_1, @Val_2) AS [COALESCE Result]
GO
----------------------------------------------------------
-- output data type
IF OBJECT_ID('dbo.TestISNULL', 'U') IS NOT NULL
DROP TABLE dbo.TestISNULL ;
DECLARE @Val_1 NVARCHAR(200) ,
@Val_2 DATETIME ;
SET @Val_1 = NULL ;
SET @Val_2 = GETDATE() ;
SELECT COALESCE('Saeid', @Val_2) AS Col1,
COALESCE(@Val_1, @Val_2) AS Col2,
COALESCE(NULL, @Val_2) AS Col3
INTO dbo.TestISNULL
WHERE 1 = 0 ;
GO
SELECT COLUMN_NAME ,
DATA_TYPE ,
CHARACTER_MAXIMUM_LENGTH
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'dbo'
AND TABLE_NAME = N'TestISNULL' ;
GO
----------------------------------------------------------
-- NULL-ability
IF OBJECT_ID('dbo.TestISNULL', 'U') IS NOT NULL
DROP TABLE dbo.TestISNULL ;
DECLARE @Val_1 NVARCHAR(200) ,
@Val_2 DATETIME ;
SET @Val_1 = NULL ;
SET @Val_2 = GETDATE() ;
SELECT COALESCE('Saeid', @Val_2) AS Col1,
COALESCE(@Val_1, @Val_2) AS Col2
INTO dbo.TestISNULL
WHERE 1 = 0 ;
GO
SELECT COLUMN_NAME ,
IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'dbo'
AND TABLE_NAME = N'TestISNULL' ;
GO
Output
IIF
IIF( condition , x, y)
IIF is a logical function which was introduced in SQL Server 2012. It is like a conditional operator in C-Sharp language. When the condition is true, x evaluated, else y evaluated. Following example illustrates this function usage.
DECLARE @x NVARCHAR(10) ,
@y NVARCHAR(10) ;
SET @x = N'True' ;
SET @y = N'False' ;
SELECT IIF( 1 = 0, @x, @y) AS [IIF Result]
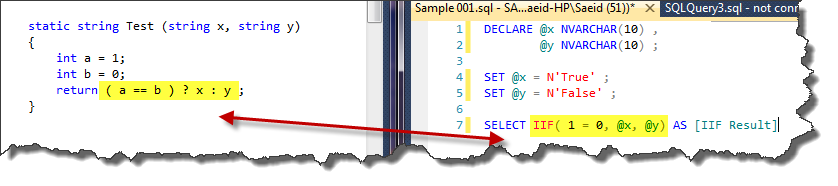
Like COALESCE expression, IIF function always translates to CASE expression. For instance,
IIF ( condition, true_value, false_value )
is equivalent to:
Case
when (condition is true) then (true_value)
Else (false_value)
End
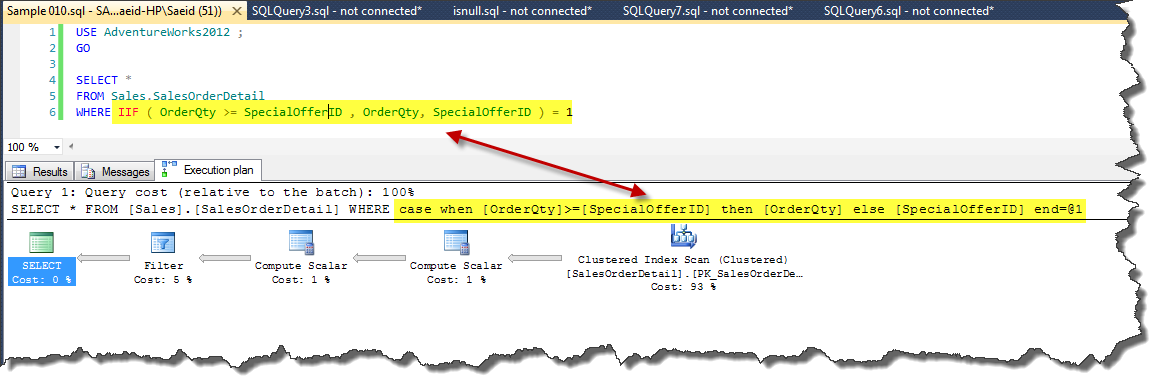
This example shows that this translation.
USE AdventureWorks2012 ;
GO
SELECT *
FROM Sales.SalesOrderDetail
WHERE IIF ( OrderQty >= SpecialOfferID , OrderQty, SpecialOfferID ) = 1
Pic 010
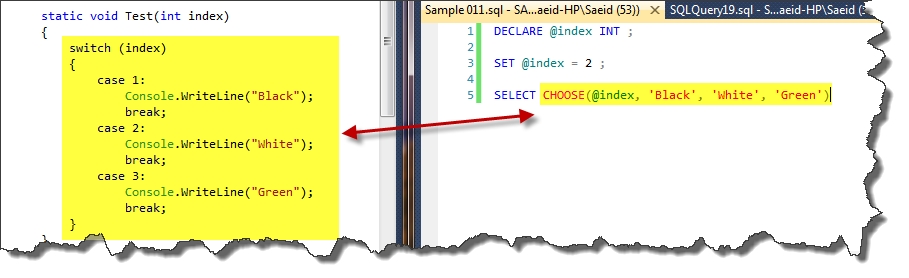
**CHOOSE **
CHOOSE(index, val_1, val_2, ..., val_n) ,(for n >=1)
CHOOSE is a selection function which was introduced in SQL Server 2012. It’s like the Switch operator in C-Sharp language. If index (must be convertible to data type INT) is NULL or its value is not found, the output will be NULL. This function needs at least two arguments, one for index and other for value. Following code illustrates this function usage.
DECLARE @index INT ;
SET @index = 2 ;
SELECT CHOOSE(@index, 'Black', 'White', 'Green')
Like COALESCE expression and IIF function, CHOOSE also always translates into CASE expression. For example,
CHOOSE ( index, val_1, val_2 )
is equivalent to:
Case
when (index = 1) then val_1
when (index = 2) then val_2
Else NULL
End
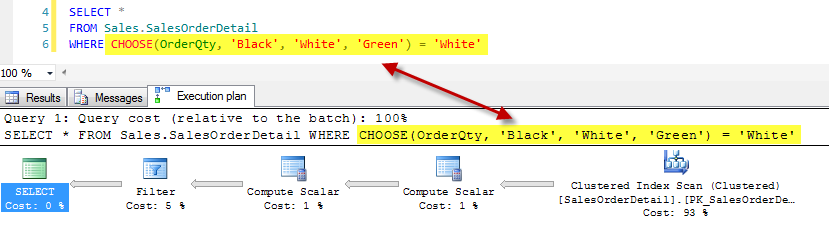
This simple code shows that this translation.
USE AdventureWorks2012 ;
GO
SELECT *
FROM Sales.SalesOrderDetail
WHERE CHOOSE(OrderQty, 'Black', 'White', 'Green') = 'White'
Pic 012
Performance
Although the main purpose of simplified CASE expression statements is increasing readability and having cleaner codes, one important question is how these statements impact on the database performance. Is there any performance difference between the CASE expression and these statements? By the way, to achieve the best performance it’s usually better to find alternative solutions and avoid using CASE and these statements.
Dynamic filtering
This is common to write reports which accept input parameters. To achieve better performance it’s a good practice to write their code within stored procedures because procedures store the way of their executing as an execution plan and reuse it again. By the way, there are some popular solutions to write this type of procedures.
IS NULL and OR
This is the most common solution. Let me start with an example and rewrite it with comparable solutions:
USE AdventureWorks2012;
GO
IF OBJECT_ID('Sales.SalesOrderDetailSearch', 'P') IS NOT NULL
DROP PROC Sales.SalesOrderDetailSearch ;
GO
CREATE PROC Sales.SalesOrderDetailSearch
@ModifiedDate AS DATETIME = NULL ,
@ShipDate AS DATETIME = NULL ,
@StoreID AS INT = NULL
AS
SELECT b.ShipDate ,
c.StoreID ,
a.UnitPriceDiscount ,
b.RevisionNumber ,
b.DueDate ,
b.ShipDate ,
b.PurchaseOrderNumber ,
b.TaxAmt ,
c.PersonID ,
c.AccountNumber ,
c.StoreID
FROM Sales.SalesOrderDetail a
RIGHT OUTER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
LEFT OUTER JOIN Sales.Customer c ON b.CustomerID = c.CustomerID
WHERE (a.ModifiedDate = @ModifiedDate OR @ModifiedDate IS NULL)
AND (b.ShipDate = @ShipDate OR @ShipDate IS NULL)
AND (c.StoreID = @StoreID OR @StoreID IS NULL)
GO
-----------------------------------------------
-- now execute it with sample values
EXEC Sales.SalesOrderDetailSearch @ModifiedDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @ShipDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @StoreID = 602
Execution statistics:

The main problem here, as illustrated in above figure, is using same execution plan for all the three situations. It’s obvious that the third one suffers from an inefficient execution plan.
CASE
We can change the combination of IS NULL and OR and translate it using CASE. Now we rewrite above code like this one:
USE AdventureWorks2012;
GO
IF OBJECT_ID('Sales.SalesOrderDetailSearch', 'P') IS NOT NULL
DROP PROC Sales.SalesOrderDetailSearch ;
GO
CREATE PROC Sales.SalesOrderDetailSearch
@ModifiedDate AS DATETIME = NULL ,
@ShipDate AS DATETIME = NULL ,
@StoreID AS INT = NULL
AS
SELECT b.ShipDate ,
c.StoreID ,
a.UnitPriceDiscount ,
b.RevisionNumber ,
b.DueDate ,
b.ShipDate ,
b.PurchaseOrderNumber ,
b.TaxAmt ,
c.PersonID ,
c.AccountNumber ,
c.StoreID
FROM Sales.SalesOrderDetail a
RIGHT OUTER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
LEFT OUTER JOIN Sales.Customer c ON b.CustomerID = c.CustomerID
WHERE a.ModifiedDate = CASE WHEN @ModifiedDate IS NOT NULL THEN @ModifiedDate ELSE a.ModifiedDate END
AND b.ShipDate = CASE WHEN @ShipDate IS NOT NULL THEN @ShipDate ELSE b.ShipDate END
AND c.StoreID = CASE WHEN @StoreID IS NOT NULL THEN @StoreID ELSE c.StoreID END
GO
-----------------------------------------------
-- now execute it with sample values
EXEC Sales.SalesOrderDetailSearch @ModifiedDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @ShipDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @StoreID = 602
Execution statistics:

Using CASE shows improvements to IS NULL and OR, but with more CPU cost for the first one. Also, the Reads and Actual Rows decreased in the first two executions. So it’s better but still, we continue our experiment.
COALESCE
We also can change CASE and translate it to COALESCE. Now we rewrite above code like this:
USE AdventureWorks2012;
GO
IF OBJECT_ID('Sales.SalesOrderDetailSearch', 'P') IS NOT NULL
DROP PROC Sales.SalesOrderDetailSearch ;
GO
CREATE PROC Sales.SalesOrderDetailSearch
@ModifiedDate AS DATETIME = NULL ,
@ShipDate AS DATETIME = NULL ,
@StoreID AS INT = NULL
AS
SELECT b.ShipDate ,
c.StoreID ,
a.UnitPriceDiscount ,
b.RevisionNumber ,
b.DueDate ,
b.ShipDate ,
b.PurchaseOrderNumber ,
b.TaxAmt ,
c.PersonID ,
c.AccountNumber ,
c.StoreID
FROM Sales.SalesOrderDetail a
RIGHT OUTER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
LEFT OUTER JOIN Sales.Customer c ON b.CustomerID = c.CustomerID
WHERE a.ModifiedDate = COALESCE(@ModifiedDate, a.ModifiedDate)
AND b.ShipDate = COALESCE(@ShipDate, b.ShipDate)
AND c.StoreID = COALESCE(@StoreID, c.StoreID)
GO
-----------------------------------------------
-- now execute it with sample values
EXEC Sales.SalesOrderDetailSearch @ModifiedDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @ShipDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @StoreID = 602
Execution statistics:

It’s obvious that because COALESCE translates to CASE internally, so there is no difference between them.
ISNULL
Now we rewrite above code and use ISNULL instead of COALESCE:
USE AdventureWorks2012;
GO
IF OBJECT_ID('Sales.SalesOrderDetailSearch', 'P') IS NOT NULL
DROP PROC Sales.SalesOrderDetailSearch ;
GO
CREATE PROC Sales.SalesOrderDetailSearch
@ModifiedDate AS DATETIME = NULL ,
@ShipDate AS DATETIME = NULL ,
@StoreID AS INT = NULL
AS
SELECT b.ShipDate ,
c.StoreID ,
a.UnitPriceDiscount ,
b.RevisionNumber ,
b.DueDate ,
b.ShipDate ,
b.PurchaseOrderNumber ,
b.TaxAmt ,
c.PersonID ,
c.AccountNumber ,
c.StoreID
FROM Sales.SalesOrderDetail a
RIGHT OUTER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
LEFT OUTER JOIN Sales.Customer c ON b.CustomerID = c.CustomerID
WHERE a.ModifiedDate = ISNULL(@ModifiedDate, a.ModifiedDate)
AND b.ShipDate = ISNULL(@ShipDate, b.ShipDate)
AND c.StoreID = ISNULL(@StoreID, c.StoreID)
GO
-----------------------------------------------
-- now execute it with sample values
EXEC Sales.SalesOrderDetailSearch @ModifiedDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @ShipDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @StoreID = 602
Execution statistics:

There is no change in Duration, but with more estimated rows.
Dynamic SQL
Using above four solutions we could not achieve good performance, because we need different efficient execution plan for each combination of input parameters. So it’s time to use an alternative solution to overcome this problem.
USE AdventureWorks2012;
GO
IF OBJECT_ID('Sales.SalesOrderDetailSearch', 'P') IS NOT NULL
DROP PROC Sales.SalesOrderDetailSearch ;
GO
CREATE PROC Sales.SalesOrderDetailSearch
@ModifiedDate AS DATETIME = NULL ,
@ShipDate AS DATETIME = NULL ,
@StoreID AS INT = NULL
AS
DECLARE @sql NVARCHAR(MAX), @parameters NVARCHAR(4000) ;
SET @sql = '
SELECT b.ShipDate ,
c.StoreID ,
a.UnitPriceDiscount ,
b.RevisionNumber ,
b.DueDate ,
b.ShipDate ,
b.PurchaseOrderNumber ,
b.TaxAmt ,
c.PersonID ,
c.AccountNumber ,
c.StoreID
FROM Sales.SalesOrderDetail a
RIGHT OUTER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
LEFT OUTER JOIN Sales.Customer c ON b.CustomerID = c.CustomerID
WHERE 1 = 1 '
IF @ModifiedDate IS NOT NULL
SET @sql = @sql + ' AND a.ModifiedDate = @xModifiedDate '
IF @ShipDate IS NOT NULL
SET @sql = @sql + ' AND OrderQty = @xShipDate '
IF @StoreID IS NOT NULL
SET @sql = @sql + ' AND ProductID = @xStoreID '
SET @parameters =
'@xModifiedDate AS DATETIME ,
@xShipDate AS DATETIME ,
@xStoreID AS INT' ;
EXEC sp_executesql @sql, @parameters,
@ModifiedDate, @ShipDate, @StoreID ;
GO
-----------------------------------------------
-- now execute it with sample values
EXEC Sales.SalesOrderDetailSearch @ModifiedDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @ShipDate = '2008-04-30 00:00:00.000'
EXEC Sales.SalesOrderDetailSearch @StoreID = 602
Execution statistics:

There is no doubt that this solution is the best one! Here is the comparison chart. (lower is better)
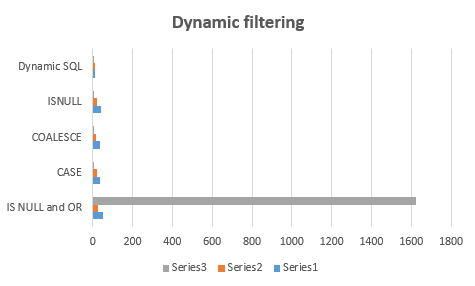
You can find more information about the last solution in Erland Sommarskog website.
Concatenate values in one column
This is another common problem that fits our discussion. In this example, we just cover COALESCE and ISNULL solutions and at last, we will see an alternative solution which performs better than using the CASE solutions.
COALESCE
Next code concatenates the values of column “ProductID” and delimiters each with the comma separator.
USE AdventureWorks2012
GO
DECLARE @sql NVARCHAR(MAX);
SELECT @sql = COALESCE(@sql + ', ', '') + CONVERT(NVARCHAR(100), ProductID)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID < 53000
Execution statistics:

This code executed in 13 seconds in our test system.
ISNULL
Now we rewrite above code and use ISNULL instead of COALESCE:
USE AdventureWorks2012
GO
DECLARE @sql NVARCHAR(MAX);
SELECT @sql = ISNULL(@sql + ', ', '') + CONVERT(NVARCHAR(100), ProductID)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID < 53000
Execution statistics:

The duration decreased to 3 seconds.
XML
It’s time to use an alternative solution to overcome this problem.
USE AdventureWorks2012
GO
DECLARE @sql NVARCHAR(MAX);
SELECT @sql = ( SELECT STUFF(( SELECT ',' + CONVERT(NVARCHAR(100), ProductID) AS [text()]
FROM Sales.SalesOrderDetail
WHERE SalesOrderID < 53000
FOR
XML PATH('')
), 1, 1, '')
) ;
Pic 020

The duration decreased to 21 milliseconds. Here is the comparison chart. (lower is better)
Note that XML runs at lowest duration.
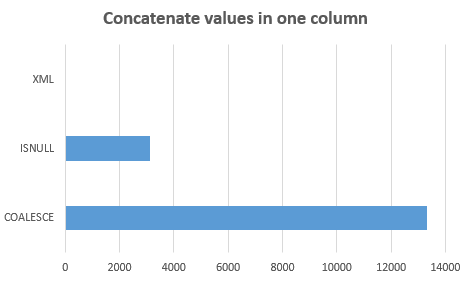
There is no doubt that this solution is the best one. But because using XML, this solution has some limitations related to XML reserved characters like "<" or ">".
Branch program execution based on switch between possible values
This is so common to use CHOOSE function to write cleaner codes. But is it the best solution to achieve optimal performance? In this section, we will discuss this question.
CHOOSE
Let’s start with an example that uses CHOOSE as its solution.
USE AdventureWorks2012 ;
GO
SELECT *
FROM Sales.SalesOrderDetail
WHERE CHOOSE(OrderQty, 'J', 'I', 'H', 'G', 'F', 'E', 'D', 'C', 'B', 'A')
IN ( 'J', 'Q', 'H', 'G', 'X', 'E', 'D', 'Y', 'B', 'A', NULL )
GO
Execution statistics:

This code executed in 352 milliseconds in our test system.
UDF function
Now we rewrite above code and use a Table Valued Function to produce CHOOSE list:
USE AdventureWorks2012 ;
GO
CREATE FUNCTION ufnLookup ()
RETURNS TABLE
AS
RETURN
SELECT 1 AS Indexer, 'J' AS val
UNION ALL
SELECT 2, 'I'
UNION ALL
SELECT 3, 'H'
UNION ALL
SELECT 4, 'G'
UNION ALL
SELECT 5, 'F'
UNION ALL
SELECT 6, 'E'
UNION ALL
SELECT 7, 'D'
UNION ALL
SELECT 8, 'C'
UNION ALL
SELECT 9, 'B'
UNION ALL
SELECT 10, 'A'
GO
SELECT *
FROM Sales.SalesOrderDetail a
JOIN dbo.ufnLookup() b ON a.OrderQty = b.Indexer
WHERE b.val IN ( 'J', 'Q', 'H', 'G', 'X', 'E', 'D', 'Y', 'B', 'A', NULL ) ;
Execution statistics:

The duration decreased to 195 milliseconds.
Permanent Lookup Table
It’s time to use an alternative solution to overcome this problem.
USE AdventureWorks2012 ;
GO
CREATE TABLE LookupTable
( id INT PRIMARY KEY, val CHAR(1) ) ;
GO
INSERT dbo.LookupTable
( id, val )
SELECT 1 AS Indexer, 'J' AS val
UNION ALL
SELECT 2, 'I'
UNION ALL
SELECT 3, 'H'
UNION ALL
SELECT 4, 'G'
UNION ALL
SELECT 5, 'F'
UNION ALL
SELECT 6, 'E'
UNION ALL
SELECT 7, 'D'
UNION ALL
SELECT 8, 'C'
UNION ALL
SELECT 9, 'B'
UNION ALL
SELECT 10, 'A' ;
GO
SELECT *
FROM Sales.SalesOrderDetail a
JOIN dbo.LookupTable b ON a.OrderQty = b.Id
WHERE b.val IN ( 'J', 'Q', 'H', 'G', 'X', 'E', 'D', 'Y', 'B', 'A', NULL )
Execution statistics:

The duration decreased to 173 milliseconds. Next figure shows the comparison chart between these solutions. (lower is better)
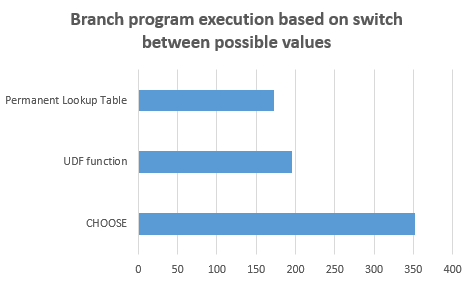
This solution is the best one. By increasing the number of values in the parameter list of CHOOSE function, the performance decreases. So by using a permanent look-up table that benefits from a physical index, we can achieve the best performance.
More Readability
The most important goal to use these simplified CASE statements is achieved cleaner code. Many times we encounter this issue that code is so large that the SELECT list becomes more than a hundred lines of code. Therefore there is a significant reason to use these statements. I have faced a simple problem just a few years ago. At first sight, it seems that the solution should be very simple. But after writing the code using CASE, I found that I am in trouble. The problem was so simple. Assume that a department store has two discount plan, one based on purchases amount, and other based on the distance from the customer’s home to store. But the rule was that just one plan that is greater is applicable. Next code shows two solutions, first by using CASE and second uses IIF.
IF OBJECT_ID('tempdb..#temp', 'U') IS NOT NULL
DROP TABLE #temp ;
CREATE TABLE #temp ( CustomerId INT, Bill MONEY, Distance INT ) ;
INSERT #temp
( CustomerId, Bill, Distance )
VALUES ( 1, 30.00, 3 ),
( 2, 10.00, 8 ),
( 3, 5.00, 14 ),
( 4, 20.00, 21 ),
( 5, 25.00, 23 ),
( 6, 5.00, 27 ) ;
SELECT *
FROM #temp
-- solution using CASE
SELECT
CASE
WHEN
CASE WHEN Bill < 10.00 THEN 10 ELSE 20 END > CASE WHEN Distance < 10 THEN 7 ELSE 13 END
THEN CASE WHEN Bill < 10.00 THEN 10 ELSE 20 END
ELSE CASE WHEN Distance < 10 THEN 7 ELSE 13 END
END AS Discount
FROM #temp
--solution using IIF
SELECT
IIF( IIF( Bill < 10.00 , 10 ,20 ) > IIF( Distance < 10 , 7 , 13 )
,IIF( Bill < 10.00 , 10 ,20 ) , IIF( Distance < 10 , 7 , 13 ) ) AS Discount
FROM #temp
As illustrated in the above code, IIF solution is more readable.
Conclusion
Using simplified CASE expression statements results to have cleaner code and speed up development time, but they show poor performance in some situations. So if we are in performance tuning phase of software development, it’s better to think about alternative solutions.