SQL Server: When Foreign Keys will Cause Conflicts with FILLFACTOR
The FILLFACTOR is a good option to avoid expensive page splits in an index. Unfortunately the usage of FILLFACTOR is most often handled like the usage of a water can - the same FILLFACTOR will be used for every index. Such a usage can lead to disadvantages when the given FILLFACTOR will leave space on the data page which will never be used again. This article will demonstrate the negative side effects to the data storage and the buffer pool with wrong implemented FILLFACTOR.
Test Environment
For all analysis steps the following table structure(s) will be used:
CREATE TABLE dbo.OrderTypes
(
Id tinyint NOT NULL identity (1,1),
c1 char(20) NOT NULL,
CONSTRAINT pk_OrderTypes PRIMARY KEY CLUSTERED (Id)
);
GO
CREATE TABLE dbo.Orders
(
OrderId int NOT NULL IDENTITY (1, 1),
OrderTypeId tinyint NOT NULL,
c1 char(200) NOT NULL DEFAULT ('some stuff'),
-- ... and many other possible attributes
OrderDate date NOT NULL,
CONSTRAINT pk_Orders PRIMARY KEY CLUSTERED (OrderId),
CONSTRAINT fk_OrderTypeId FOREIGN KEY (OrderTypeId)
REFERENCES dbo.OrderTypes(Id)
);
GO
The above script creates a reference table [dbo].[OrderTypes] which holds the different categories for given orders. The table [dbo].[Orders] will use this relation as a reference for the definition of the placed order. Furthermore - and important - is the fact that its clustered index is a steady growing value because the attribute [OrderId] has contiguous values by using IDENTITY as automatic value.
A common misconception is that Microsoft SQL Server will create an index when a FOREIGN KEY constraint will be created. This is not true as the following script will demonstrate:
SELECT index_id,
name,
type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders');
As the following picture will show there is only the individual defined clustered index for the dbo.Orders table available
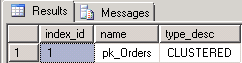
So an additional index [ix_Orders_OrderTypeId] will be created for a better support of queries which use the JOIN operator.
CREATE NONCLUSTERED INDEX ix_Orders_OrderTypeId ON dbo.Orders(OrderTypeId);
In this scenario there will be only a few different order types so only 4 records will be inserted into the reference table [dbo].[OrderTypes].
INSERT INTO dbo.OrderTypes (c1)
VALUES ('online order'),
('shop sales'),
('staff order'),
('others');
After the reference data have been inserted the next code will insert 10.000 order records with random "order types".
SET NOCOUNT ON;
GO
DECLARE @i int = 1;
WHILE @i <= 10000
BEGIN
INSERT INTO dbo.Orders (OrderTypeId, c1, OrderDate)
VALUES (
CAST(RAND() * 4 + 1 AS int),
'Order: ' + CAST(@i AS varchar(10)),
DATEADD(dd, -CAST(RAND() * 365 + 1 AS int), GETDATE())
);
SET @i += 1;
END
GO
Analysis of physical index stats
After all data have been inserted the next step shows the physical stats of the indexes in [dbo].[Orders].
SELECT i.name,
i.type_desc,
ps.page_count,
ps.record_count,
ps.avg_page_space_used_in_percent
FROM sys.indexes i INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') ps
ON (
i.object_id = ps.object_id AND
i.index_id = ps.index_id
)
WHERE i.object_id = OBJECT_ID('dbo.Orders', 'U') AND
ps.index_level = 0;

While the clustered index is in a perfect condition because of the contiguous values for the clustered key the index on the foreign key attribute [OrderTypeId] is in a bad condition. It consumes only 65% of the data pages. So an initial idea of a DBA should be the usage of FILLFACTOR for prevention of page splits for this index.
A Page Split in Detail
A page split is an expensive operation the database engine of Microsoft SQL Server has to do. A page split occurs when new data should be inserted on an index page and there is no further space on that page. At that moment Microsoft SQL Server needs to run the following - internal - processes to make room for this new data:
- Create a new data page
- Update object meta data about the new page (a new page has been added)
- Format the new data page
- COPY half of the data from the original data page to the new data page
- Delete the formerly copied data from the original data page
- Update the page header information about the next page (original page)
- Update the page header information about the previous page (former "next page")
All the operational steps consume a huge amount of transaction log and make such an operation extremely expensive. With FILLFACTOR as an option of an index rebuild those expensive page splits can be reduced by filling a data page only up to a dedicated percentage (e.g. 80%). Such an operation will leave 20% free for new data and until the page isn't full new data can be inserted without any expensive page splits. Concerning this behaviour the fragmented index [ix_Orders_OrderTypeId] will be rebuild by using only 80% of the available storage on a page.
ALTER INDEX ix_Orders_OrderTypeId REBUILD WITH (FILLFACTOR = 80);

After the rebuild operation the index average page density is ~75%. The situation may be non-critical in this context - but this is not true. By this operation the DBA has generated a huge amount of wasted storage.
A look into the physical location of the index data
To understand why this operation will not de-escalate the problems with page splits a deeper dive into the data pages is required. Before the investigation the first information which is required is the histogram of the different values (1 - 4) in the index itself.
DBCC SHOW_STATISTICS ('dbo.Orders', 'ix_Orders_OrderTypeId') WITH HISTOGRAM;
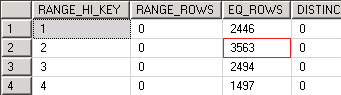
The above picture shows the distribution of the index keys. Shop Sales will dominate the daily business with over 3.500 index entries. The next SQL command will output the physical location of each index record. For better overview only an excerpt will be displayed after the command.
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, *
FROM dbo.Orders WITH (INDEX = 2)
WHERE OrderTypeId = 2;
The above statement returns for all records with the OrderTypeId = 2 the physical location of the index key values. The most important point of interest are the edges of the given data. The next picture show the starting point and the second picture shows the last index entry for OrderTypeId = 2 (the values may be different if you replay the demos!)
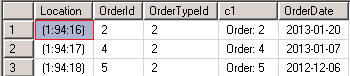
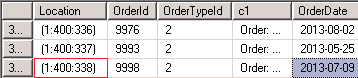
The above pictures show the beginning of key value 2 for the index [ix_Orders_OrderTypeId] on page 94 in the slot 16 while the very last entry for index key value 2 is at physical position 400 in slot 338. Supposing that app. 800 records will fit on one page the above pictures indicate the following scenario:
- on page 94 the index key value = 1 is located in Slots 0 - 15
- on page 400 the next index key value = 3 starts at slot 339
- all other pages in between are completely filled with the index key value = 2
So - depending on the above statement - the pages will have the following internal structure:
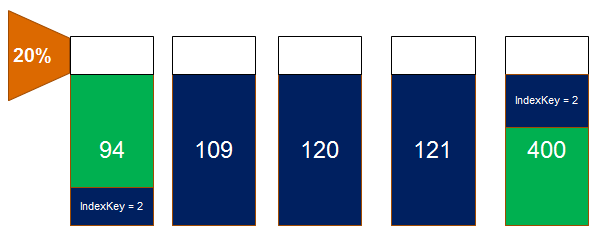
The picture shows the 20% of free space on each page. While page 94 can only add new index entries depending on index key value = 1 the pages 109, 120 and 121 cannot have new entries although 20% of free space is available. The page 400 can have new index records for the index key = 2 and the index key = 3. The problematic point to the above scenario is the increasing value for the clustered index key! Every non clustered index must store the clustered index key as reference to all data from the table. A look the b-tree (for this example the page 90) page which manages the shown pages looks as follows:
DBCC TRACEON (3604);
DBCC PAGE ('db_demo', 1, 90, 3);
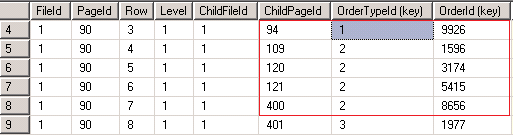
The above picture perfectly shows the hierarchy of the stored data. The clustered key [OrderId] will be stored with every single index key as reference.
Scenario for a new inserted Order
If a new record gets inserted the following three possibilities may occur:
- A new record with OrderTypeId = 1 will be inserted into the table. The record for index [ix_Orders_OrderTypeId] will be inserted on page 94 because the key value 2 is before the 3 and the new value for the clustered index (contiguous value) will be 10.001. Due to the fact that page 94 has 20% of free space the transaction will not run into a page split.
- A new record with the OrderTypeId = 2 will be inserted into the table. The record for the index [ix_Orders_OrderTypeId] will be inserted on page 400 because page 400 covers the last records for the OrderTypeId = 2. As the clustered index key is a contiguous value the record will be inserted without a page split because 20% of the data page is free.
- A new record with the OrderTypeId = 3 will be inserted into the table. The record for the index [ix_Orders_OrderTypeId] will be inserted on the very last index page which stores the last index record for OrderTypeId = 3 Page 400 will not be touched. It can only store new Orders from OrderTypeId = 2!
The above scenario demonstrates now the problem which occurs with all pages in between the edges of the data values for the index. Concerning the page model above the pages 190, 121 and 122 will never ever store any additional data because the clustered index key will always increase but never decrease.
Conclusion
The FILLFACTOR is a pretty fine corrective for page fragmentation. But if the index key is a composite of a value which has no large variance a FILLFACTOR will have bad side effects to the used storage on the data pages. Every time a FILLFACTOR will be taken into consideration it has to be proved for non clustered indexes for contiguous clustered keys. If both conditions will met a FILLFACTOR is not recommended but an index rebuild in a smaller interval!