SQL Server 2012: Structured Error Handling Mechanism
The goal of this article is to provide a simple and easy to use error handling mechanism with minimum complexity. This article is completely compatible with MS SQL SERVER 2012 and above versions.
Problem definition
There are many questions in MSDN forum and other Internet communities about Error Handling in SQL Server. There are several issues as presented in the Table of Contents above.
Introduction
There are many articles written by the best experts and there are complete references about Error Handling in SQL Server. The goal of this article is to provide a simple and easy to use error handling mechanism with minimum complexity. Therefore I will try to address this topic from a problem-solving approach and particularly in SQL Server 2012 (and later) versions. So the road map of this article is to cover the above questions as well as providing a step by step tutorial to design a structured mechanism for error handling in SQL Server 2012 (and up) procedures.
Solution
Is there any structured Error Handling mechanism in SQL Server?
Yes, there is. The TRY/CATCH construct is the structured mechanism for error handling in SQL Server 2005 and later. This construct has two parts; we can try executing some statements in TRY block and handling errors in the CATCH block if they occur. Therefore, the simplest error handling structure can be like this:
- TRY
- Try executing statements
- CATCH
- Handle the errors if they occur
Here is a sample code to provide the above structure in the simplest form:
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; /* Executing statements */
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
PRINT 'Error occurs!' /* Handle the error */
END CATCH -- End of Handling the error if occurred
--result
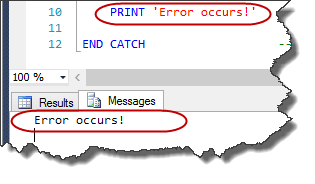
Will all statements in TRY block try to execute?
When executing statements in the TRY block, if an error occurs the flow of execution will transfer to the CATCH block. So the answer is NO!
We can see this behavior with an example. As we can see after executing the following code, the statement no. 3 does not try executing, because the flow of execution will transfer to the CATCH block as soon as statement no. 2 raises an error.
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
PRINT 'Before Error!' -- Statement no1
SELECT 1 / 0; -- Statement no2
PRINT 'After Error!' -- Statement no3
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
PRINT 'Error occurs!' /* Handle the error */
END CATCH -- End of Handling the error if occurred
--result

Does the CATCH part automatically handle the errors?
No. The role of the TRY/CATCH construct is just providing a mechanism to try executing SQL statements. Therefore, we need to use another constructor statements to handle the errors in the CATCH block that I explain later. For instance, the following code will try to execute a divide by zero statements. It does not automatically handle any errors. In fact, in this sample code, when an error occurs the flow control immediately transfers to the CATCH block, but in the CATCH block, we do not have any statement to tell us that there was an error!
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; -- Statement
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
END CATCH -- End of Handling the error if occurred
--result
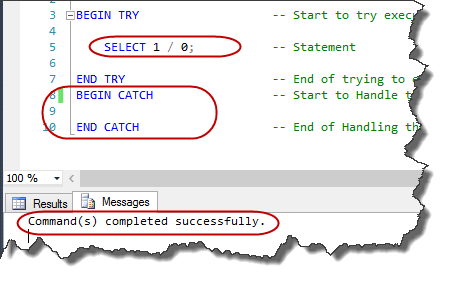
In the CATCH block we can handle the error and send the error message to the application. So we need an element to show what error occurs. This element is RAISERROR. So the error handling structure could be like this:
- TRY
- Try executing statements
- CATCH
- Handle the error if occurs
- RAISERROR
- Handle the error if occurs
Here is sample code to produce the above structure:
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; -- Statement
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
RAISERROR('Error!!!', 16, 1);
END CATCH -- End of Handling the error if occurred
--result

The RAISERROR itself needs other elements to identify the error number, error message, etc. Now we can complete the error handling structure:
- TRY
- Try executing statements
- CATCH
- Handle the error if occurs
- RAISERROR
- ERROR_NUMBER()
- ERROR_MESSAGE()
- ERROR_SEVERITY()
- ERROR_STATE()
- ERROR_PROCEDURE()
- ERROR_LINE()
- RAISERROR
- Handle the error if occurs
Here is sample code to produce the above structure:
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; -- Statement
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT
@ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (@ErrorMessage, -- Message text.
@ErrorSeverity, -- Severity.
@ErrorState -- State.
);
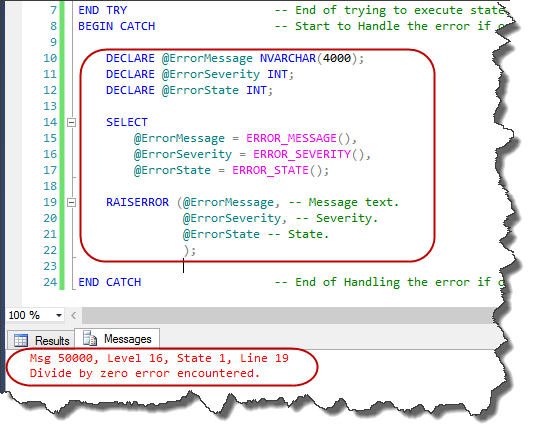
END CATCH -- End of Handling the error if occurred
--result
Is it a good idea to use a general procedure as a modular Error Handler routine?
From a modular programming approach, it’s recommended to create a stored procedure that does the RAISERROR job. But I believe that using a modular procedure (I call it spErrorHandler) to re-raise errors is not a good idea. Here are my reasons:
1. When we call RAISERROR in procedure “spErrorHandler”, we have to add the name of the procedure that the error occurs within to the Error Message. This will confuse the application end-users (Customer). Customer does not want to know which part of his car is damaged. He prefers that his car just send him a simple message which tells him there is an error in its functions. In the software world it’s more important to send a simple (English) message to the customer because if we send a complex error message, he will be afraid of what will happen to his critical data!
2. If we accept the first reason and decide to resolve this issue, we need to send a simple message to the client application. So we will lose the procedure name that the error occurs within and other useful information for debugging unless we insert this useful information in an Error-Log table.
You can test this scenario with the following code:
CREATE PROCEDURE spErrorHandler
AS
SET NOCOUNT ON;
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT
@ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (@ErrorMessage, -- Message text.
@ErrorSeverity, -- Severity.
@ErrorState -- State.
);
go
-----------------------------------------
CREATE PROCEDURE spTest
AS
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; -- Statement
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
EXEC spErrorHandler;
END CATCH -- End of Handling the error if occurred
go
exec spTest;
--result
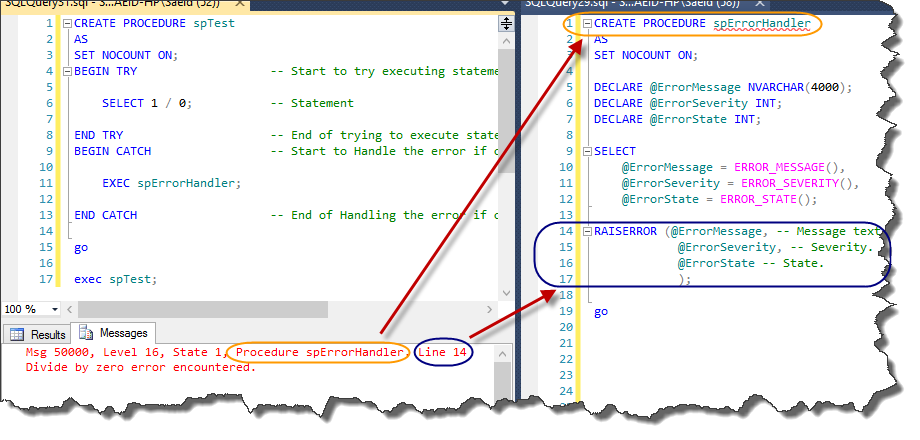
As is illustrated in this figure, when using spErrorHandler, the values of ERROR_PROCEDURE() and ERROR_NUMBER() are changed in the output. This behavior is because of the RAISERROR functionality. This function always re-raises the new exception, so spErrorHandler always shows that the value of ERROR_PROCEDURE() simply is “spErrorHandler”. As I said before there are two workarounds to fix this issue. First is concatenating this useful data with the error message and raise it, which I spoke about in reason one. Second is inserting this useful data in another table just before we re-raise the error in spErrorHandler.
Now, we test the above sample without using spErrorHandler:
CREATE PROCEDURE spTest
AS
SET NOCOUNT ON;
BEGIN TRY -- Start to try executing statements
SELECT 1 / 0; -- Statement
END TRY -- End of trying to execute statements
BEGIN CATCH -- Start to Handle the error if occurs
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT
@ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (@ErrorMessage, -- Message text.
@ErrorSeverity, -- Severity.
@ErrorState -- State.
);
END CATCH -- End of Handling the error if occurred
go
exec spTest;
--result

As you see in this figure, the procedure name and error number are correct. By the way, I prefer that if one customer reports an error, I go for SQL Server Profiler, simulate the environment completely, and test those SQL statements in SSMS to recreate the error and debug it based on the correct error number and procedure name.
In the THROW section, I will explain that the main advantage of THROW over RAISERROR is that it shows the correct line number of the code that raises the error, which is so helpful for a developer in debugging his code.
3. Furthermore, with the THROW statement introduced in SQL SERVER 2012, there is no need to write extra code in the CATCH block. Therefore there is no need to write a separate procedure except for tracking the errors in another error log table. In fact, this procedure is not an error handler, it's an error tracker. I explain the THROW statement in the next section.
What are the benefits of THROW when we have RAISERROR?
The main objective of error handling is that the customer knows that an error occurred and reports it to the software developer. Then the developer can quickly realize the reason for the error and improve his code. In fact, error handling is a mechanism that eliminates the blindness of both customer and developer.
To improve this mechanism Microsoft SQL Server 2012 introduced the THROW statement. Now I will address the benefits of THROW over RAISERROR.
The correct line number of the error!
As I said earlier this is the main advantage of using THROW. The following code will enlighten this great feature:
create proc sptest
as
set nocount on;
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
declare @msg nvarchar(2000) = error_message();
raiserror( @msg , 16, 1);
THROW
END CATCH
go
exec sptest
--result

As you can see in this figure, the line number of the error that RAISERROR reports to us always is the line number of itself in the code. But the error line number reported by THROW is line 6 in this example, which is the line where the error occurred.
Easy to use
Another benefit of using the THROW statement is that there is no need for extra code in RAISERROR.
Complete termination
The severity level raised by THROW is always 16. But the more important feature is that when the THROW statement in a CATCH block is executed, then other code after this statement will never run.
The following sample script shows how this feature protects the code compared to RAISERROR:
create proc sptest
as
set nocount on;
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
declare @msg nvarchar(2000) = error_message();
raiserror( @msg , 16, 1);
CREATE TABLE #Saeid (id int)
INSERT #Saeid
VALUES ( 101 );
SELECT *
FROM #Saeid;
DROP TABLE #Saeid;
THROW
PRINT 'This will never print!!!';
END CATCH
go
exec sptest
--result
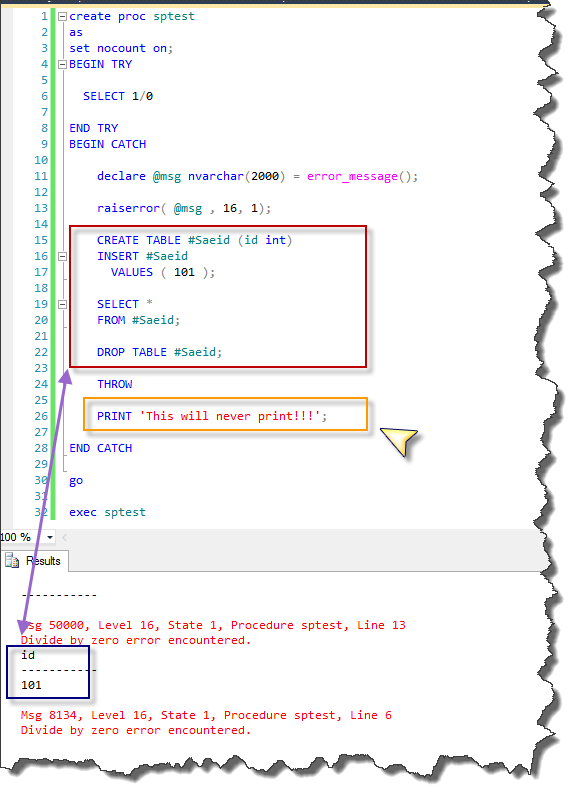
Independence of sys.messages
This feature makes it possible to re-throw custom message numbers without the need to use sp_addmessage to add the number.The feature is in real time, as you can see in this code:
create proc sptest
as
set nocount on;
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
THROW 60000, 'This a custom message!', 1;
END CATCH
go
exec sptest
--result
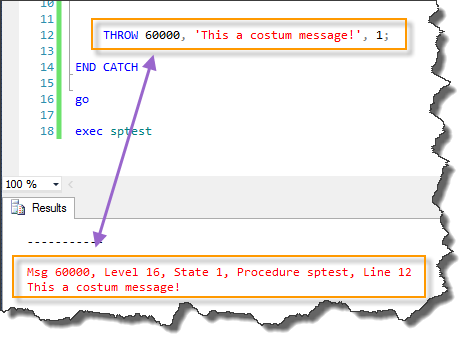
Tip
The statement before the THROW statement must be followed by the semicolon (;) statement terminator.
I want to check a condition in the TRY block. How can I control the flow of execution and raise the error?
This is a simple job! Now I change this question to this one:
“How can I terminate the execution of the TRY block?”
The answer is using THROW in the TRY block. Its severity level is 16, so it will terminate execution in the TRY block. We know that when any statement in the TRY block terminates (encounters an error) then immediately execution goes to the CATCH block. In fact, the main idea is to THROW a custom error as in this code:
create proc sptest
as
set nocount on;
BEGIN TRY
THROW 60000, 'This a custom message!', 1;
END TRY
BEGIN CATCH
THROW
END CATCH
go
exec sptest
--result
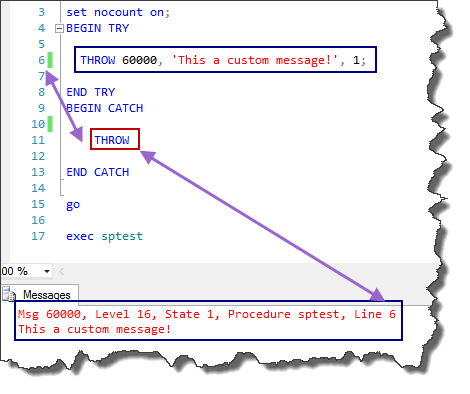
As you can see, we handle the error step by step. In the next session, we will complete this structure.
Does the CATCH part automatically rollback the statements within the TRY part?
This is the misconception that I sometimes hear. I explain this problem with a little example. After executing the following code the table “dbo.Saeid” still exists. This demonstrates that the TRY/CATCH block does not implement implicit transactions.
CREATE PROC sptest
AS
SET NOCOUNT ON;
BEGIN TRY
CREATE TABLE dbo.Saeid --No1
( id int );
SELECT 1/0 --No2
END TRY
BEGIN CATCH
THROW
END CATCH
go
-------------------------------------------
EXEC sptest;
go
SELECT *
FROM dbo.Saeid;
--result
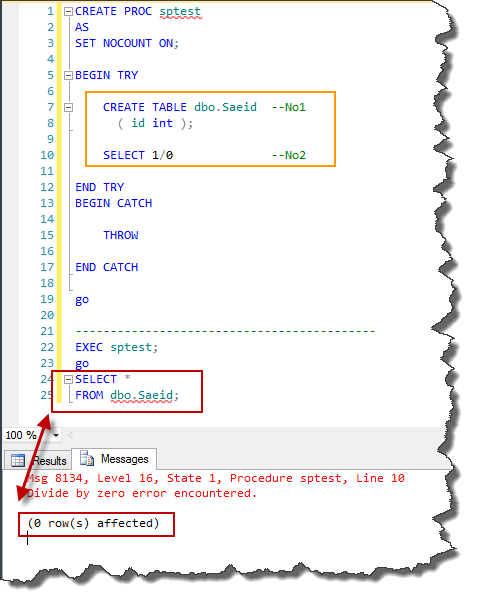
Can someone use TRANSACTION in the TRY/CATCH block?
The previous question showed that if we want to rollback entire statements in a try block, we need to use explicit transactions in the TRY block. But the main question here is:
“Where is the right place to commit and rollback? “
It’s a complex discussion that I would not like to jump into in this article. But there is a simple template that we can use for procedures (not triggers!).
This is that template:
CREATE PROC sptest
AS
SET NOCOUNT ON;
BEGIN TRY
SET XACT_ABORT ON; --set xact_abort option
BEGIN TRAN --begin transaction
CREATE TABLE dbo.Hasani
( id int );
SELECT 1/0
COMMIT TRAN --commit transaction
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0 --check if there are open transaction?
ROLLBACK TRAN; --rollback transaction
THROW
END CATCH
go
EXEC sptest;
go
SELECT *
FROM dbo.Hasani;
--result
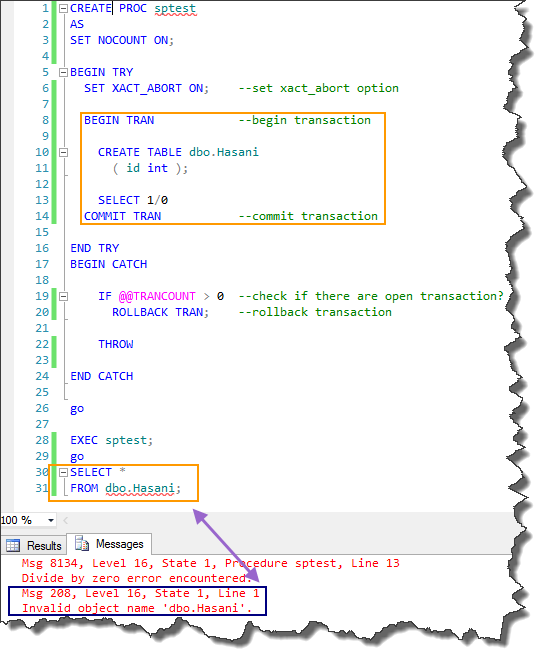
The elements of this structure are:
TRY block
- XACT_ABORT
- Begin transaction
- Statements to try
- Commit transaction
CATCH block
- Check @@TRANCOUNT and rollback all transactions
- THROW
Here is a short description of two parts of the above code:
XACT_ABORT
In general, it’s recommended to set the XACT_ABORT option to ON in our TRY/CATCH block in procedures. By setting this option to ON if we want to roll back the transaction, any user-defined transaction is rolled back.
@@TRANCOUNT
We check this global variable to ensure there is no open transaction. If there is an open transaction it’s time to execute rollback statements. This is a must in all CATCH blocks, even if you do not have any transactions in that procedure. An alternative is to use XACT_STATE().
Conclusion
Introduction of the THROW statement is a big feat in Error Handling in SQL Server 2012. This statement enables database developers to focus on accurate line numbers of the procedure code. This article provided a simple and easy to use error handling mechanism with minimum complexity using SQL Server 2012. By the way, there are some more complex situations that I did not cover in this article. If you need to dive deeper, you can see the articles in the See Also section.
BOL link http://technet.microsoft.com/en-us/library/ms175976.aspx
See Also
Related Wiki Articles
- Error Handling within Triggers Using T-SQL
- T-SQL: Error Handling for CHECK Constraints
- Transact-SQL Portal
- [[SQL Server 2012]]
- List of Award Winning TechNet Guru Articles
Error Handling in SQL Server 2000
- Error Handling in SQL 2000 – a Background written by Erland Sommarskog
- Implementing Error Handling with Stored Procedures in SQL 2000 written by Erland Sommarskog
Error Handling in SQL Server 2005 and Later
- Error Handling in SQL 2005 and Later written by Erland Sommarskog
- Error Handling in SQL Server 2005 written by Itzik Ben-Gan
- Handling Constraint Violations and Errors in SQL Server written by Phil Factor