BizTalk Server: Generating Flat File Schema for File with Tag Identifiers not at the Beginning, Grouping Data by Element and Debatching
Introduction
Recently there was a question posted in BizTalk forum, where an user wanted to:
- Create a flat file schema for delimited file with tag identifiers for header and detail which is not at the beginning of the record.
- Group the header and detail based on a date field.
- Debatch the grouped record by date.
This is an interesting question, which is worth an article by itself rather than a post in forum. In real life there a similar requirements for a complex flat file that needs to be debatched by group.
Scenario/Question
Question asked the forum will be described as follows:
An enterprise receives a flat file which looks something like this:
09Sep2013~header~data~data~data~data
09Sep2013~detail~data~data
09Sep2013~detail~data~data
09Sep2013~detail~data~data
10Sep2013~header~data~data~data~data
10Sep2013~detail~data~data
10Sep2013~detail~data~data
10Sep2013~detail~data~data
This is a delimited flat file with tag identifier for header and detail. As you can see, the tag identifiers are not at the beginning of the data for a delimited record. And questioner wants to debatch the file by date.

Figure 1. Flat File Structure.
I assume the readers for this article are familiar with the basics of BizTalk, Flat file schema processing and debatching in BizTalk. For more basic information about these concepts, readers can refer the reference section of this article.
Flat File Schema for a file with tag identifiers not at the beginning of the record
In the EDI world it is a common practice to precede the tag identifier with batch related information rather than to start with it. Unfortunately however, the BizTalk’s Flat-file schema wizard, doesn’t parse the flat file that way. It expects the tag identifier to be at the beginning of the record. If that is not the case than you will get an error as below:
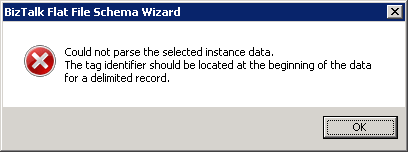
Figure 2. Flat File schema wizard error for tag identifier not at the beginning.
A possible approach of handling the flat file schema is to design the structure of the schema matching the given flat file first and then start thinking about matching the flat file to the designed schema structure by setting flat file schema properties like delimiters, type order etc. I found this useful many times as this gives an idea about how the end result (flat file schema) would be.
Following is the schema structure for the above flat file.
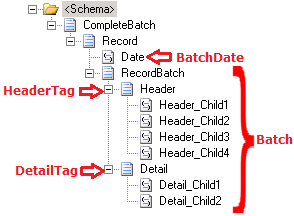
Figure 3. Schema Structure.
A way to handle the tag identifier, I prefer Johann Cooper’s suggestion. A generic repeating record to have all the common elements (in this case, just ‘Date’) and choice record node (RecordBatch). Within this choice record, I created separate record for each of the different tag identifiers (‘header’ and ‘detail’) with their respective elements (header children and detail children). Now validating the above flat file instance gave the XML instance like this.

Figure 4. XML instance for the given flat file.
Group By Date
As you can see, the above XML represents the flat file instance, but for debatching it by date, we need to group the record set by date.
**
Figure 5.** XML Instance to group by date element.

We can use the classic Muenchian Method to handle grouping and sorting. In XSLT, Muenchian method is a way to group and sort elements in a more efficient way using keys. Keys work by assigning a key value to a node and giving you easy access to that node through the key value.
Since the main objective is to debatch the file, I created an envelope schema to match this XML structure (whose structure is same as flat file schema) and mapped the flat file schema to envelope schema using Muenchian method based on custom XSLT.

Figure 6. Map Flat file schema to envelope schema.
Muenchian method based mapping.
<?xml version="1.0" encoding="UTF-16"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:msxsl="urn:schemas-microsoft-com:xslt" xmlns:var="http://schemas.microsoft.com/BizTalk/2003/var" exclude-result-prefixes="msxsl var s0" version="1.0" xmlns:ns0="http://MSDN.TechnetWiki.ComplexFFDebatch.EnvelopeSchemaGrouped" xmlns:s0="http://MSDN.TechnetWiki.ComplexFFDebatch.ComplexFFSchemaUngrouped">
<xsl:output omit-xml-declaration="yes" method="xml" version="1.0" />
<xsl:key use="Date" match="/s0:CompleteBatch/Record" name ="groups"/>
<xsl:template match="/">
<xsl:apply-templates select="/s0:CompleteBatch" />
</xsl:template>
<xsl:template match="/s0:CompleteBatch">
<ns0:CompleteBatch>
<!-- In Muenchian grouping , used count() instead of generate-id() for better performance -->
<!--<xsl:for-each select="Record[generate-id(.)=generate-id(key('groups',Date))]"> -->
<xsl:for-each select="Record[count(.| key('groups',Date)[1])=1]">
<Record>
<Date>
<xsl:value-of select="Date/text()" />
</Date>
<RecordBatch>
<xsl:for-each select ="key('groups',Date)">
<xsl:for-each select="RecordBatch/Header">
<Header>
<Header_Child1>
<xsl:value-of select="Header_Child1/text()" />
</Header_Child1>
<Header_Child2>
<xsl:value-of select="Header_Child2/text()" />
</Header_Child2>
<Header_Child3>
<xsl:value-of select="Header_Child3/text()" />
</Header_Child3>
<Header_Child4>
<xsl:value-of select="Header_Child4/text()" />
</Header_Child4>
</Header>
</xsl:for-each>
<xsl:for-each select="RecordBatch/Detail">
<Detail>
<Detail_Child1>
<xsl:value-of select="Detail_Child1/text()" />
</Detail_Child1>
<Detail_Child2>
<xsl:value-of select="Detail_Child2/text()" />
</Detail_Child2>
</Detail>
</xsl:for-each>
</xsl:for-each>
</RecordBatch>
</Record>
</xsl:for-each>
</ns0:CompleteBatch>
</xsl:template>
</xsl:stylesheet>
After applying the map, the XML instance grouped by date would look like this.

Figure 7. XML Instance grouped by date element.
Debatching
Now with XML being grouped by date in an envelope schema, it can be easily debatched by calling a receive pipeline in Orchestration. I have executed the map in orchestration just to have better readability.

**
Figure 8. **Orchestration used to call Receive-Pipeline to debatch the message
Note: Debatching in an orchestration can be useful if you require full control of your debatching process. However keep in mind that with large files that need to be debatched than orchestration is not the preferred way. Better performance can be achieved to detach in a receive port.
Output
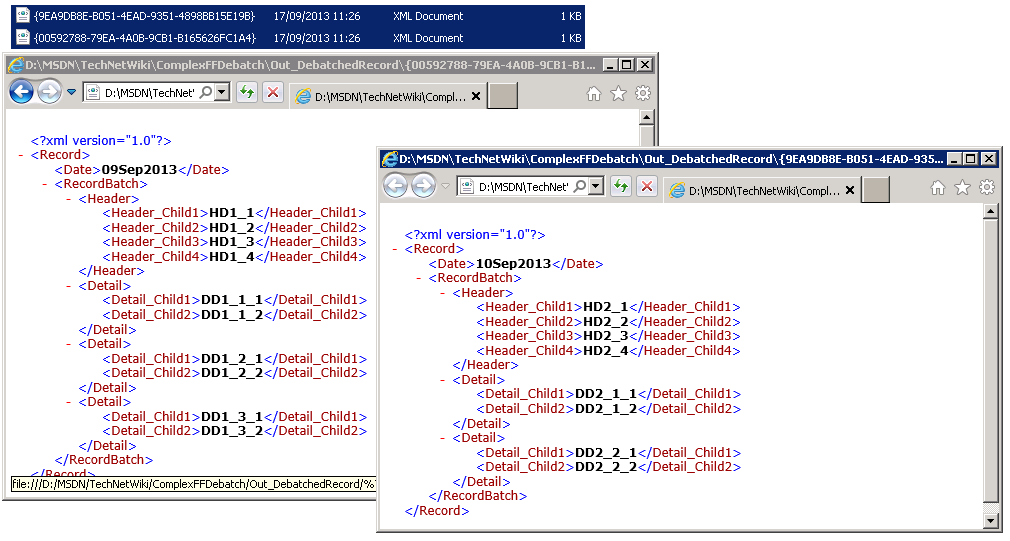
The output of the debatching is as follows:
Figure 9. Output-Debatched messages.
As with any problem, there many solutions to handle to solve it. The above method is one of the ways to implement a solution to the problem.
Source Code
Source Code for this article can be downloaded at the MSDN Code Gallery:
References
- MSDN: Flat File Schemas
- MSDN: BizTalk Flat File Schema Wizard Walkthrough
- Creating well-typed BizTalk flat file schemas which contain tags in the middle of a record
- Muenchian Grouping and Sorting in BizTalk
See Also
Read suggested related topics:
- BizTalk Virtual Mapper VS Custom-XSLT
- XSLT Muenchian Grouping - BizTalk Complex Transformation
- Complex Flat File Conversion using BizTalk schema and Map ******
Another important place to find an extensive amount of BizTalk related articles is the TechNet Wiki itself. The best entry point is BizTalk Server Resources on the TechNet Wiki.