How Storage Spaces Responds to Errors on Physical Disks
Physical disks often experience errors of varying severity, from errors that the disk can transparently recover from, without interruption or data loss; to errors that are catastrophic and can cause data loss. Storage Spaces responds to a range of errors that can occur on physical disks, responding according to the severity of the error in such a way to maximize data safety.
Overview
- If there is a disk error during a write, Storage Spaces will take one of two actions:
- If the disk returns an error code that indicates the physical disk is failing, Storage Spaces marks the disk as unhealthy in GUI (see Figure 2) and illuminates the failure LED (if present). The storage space is then marked as degraded until the failed disk is replaced and a repair operation is started. If a hot spare is present in the same enclosure in the storage pool, the hot spare comes online immediately; as part of this the type of the hot spare disk changes from hot spare to auto, allowing it to be used for allocations. Storage Spaces re-directs the failed write to any of the remaining disks in the pool and the data that was on the disk that failed is similarly re-allocated. The failure LED remains illuminated until the disk is replaced.
- If the error code is less severe, not indicating an entire disk failure, Storage Spaces may record error information in the Event Log. Even though the error was not critical, the write still failed and the storage space is marked as degraded. The physical disk where the I/O error occurred is marked as unhealthy in GUI, but the failure LED is not illuminated (even if present). Storage Spaces re-directs the failed write to any of the remaining disks in the pool and the data associated with the failed write is similarly re-allocated; the data on the disk not associated with the failed write is not re-allocated.
- If subsequent writes to the disk succeed, the disk is marked as healthy; disks often experience transitory errors and are capable of recovering from such errors. However, the storage space remains in a degraded state, reflecting that data is out-of-sync among the physical disks that are associated with the storage space. The storage space remains degraded until either a repair operation is started or an automatic re-synchronization occurs, which occurs after a five-minute interval. Until a user-initiated repair or re-synchronization occurs, the storage space is listed as degraded even though the physical disks appear healthy - after that storage space and physical disks will show consistent state again.
- If Storage Spaces encounters a read error, it will not mark a disk as failed. In a Mirror or Parity configuration, Storage Spaces attempts to retrieve the alternate copy of the data.
- For a repair to succeed, there must be sufficient free capacity, either in the pool or from a hot spare disk (in the same enclosure), to reallocate the data, either from the entire failed disk or the subset of data on the disk where the I/O error occurred. If there is not sufficient free space for the repair to succeed, then the storage space remains in a degraded state until the disk is replaced or additional disks are added to the pool.
- In the event that a disk cannot be written to or read from, but never returns an error, Storage Spaces treats the condition as a transitory failure. The action that Storage Spaces takes is configurable and defined by the Set-StoragePool -RetireMissingPhysicalDisks cmdlet; “Auto” is the default:
Option |
Behavior |
Enabled |
If a disk is missing but its enclosure is still present, treat the missing disk as failed and retire it. |
Disabled |
If a disk is missing, wait for either the disk to reconnect or for administrative action. GUI will show a status "Lost communication" |
Auto |
If the pool has a hot spare, follow the Enabled logic. Otherwise, follow the Disabled logic. |
Retire means the drive is no longer used for new allocations - data is written only to the remaining disks in the pool. Existing data on the drive, once it's marked retired, will be re-allocated to other drives in the pool as part of a repair operation. However, until re-allocation starts existing allocations on the drive will continue to be updated, in order to maintain redundancy of data, a disk that is retired will display that status in both the GUI and in Windows PowerShell.
Storage Spaces does not persist non-critical error information about physical disks. If a transitory I/O error occurs during write and the system is restarted, all physical disks will be identified as healthy after the reboot. If, however, an error occurs that indicates the entire drive is failing, that information will be persisted across a reboot such that the physical disk will continue to be identified as unhealthy. If a Storage Space was marked as degraded prior to the restart it will continue to be identified in the GUI as degraded until corrective action, such as a repair or automatic re-synchronization is started.
Under what conditions does a hot spare drive come online
If one or more drives are configured as hot spares, the following conditions describe when the hot spare drive(s) will come online:
- If a drive fails because of a medium failure, the hot spare will come online (if it resides in the same enclosure as the failing drive)
- If a drive is marked as retired, the hot spare will not come online
- If a drive is removed and the RetireMissingPhysicalDisks policy is:
- Auto: the hot spare within the same enclosure will come online
- Enabled: the hot spare within the same enclosure will come online
- Disabled: the hot spare will not come online
How to identify a physical disk when an error occurs
- For a disk that returns an error indicating that the drive is failing, the disk is marked as unhealthy and the failure LED (if present) is illuminated). For more information, see “How does Windows let me know of a disk failure”
- In addition, Windows will log an entry in the event viewer. Depending on the type of error, the disk may be identified by either a GUID or its physical disk number.
- Event ID 154 includes additional SCSI sense information that can be used for diagnostic purposes:
Provider: |
disk |
Event ID: |
154 |
Level: |
Error |
Text: |
“The IO operation at logical block address <LBA> for Disk <Disk Number> (PDO name: <PDO Name>) failed due to a hardware error.” |
Logged when: |
A fatal hardware error is reported by the device. |
Sense Key: |
Byte 0x2D in the binary data |
Add’l Sense Code: |
Byte 0x2E in the binary data |
Add’l Sense Code Qualifier: |
Byte 0x2F in the binary data |
Using Windows PowerShell
If a GUID is recorded, you can use the following PowerShell command to identify the physical disk associated with the I/O error:
Get-PhysicalDisk |? { $_.ObjectId.Contains( $PhysicalDiskGUID ); }
To illuminate the LED associated with the physical disk:
Enable-PhysicalDiskIndication –FriendlyName (Get-PhysicalDisk |? { $_.ObjectId.Contains( $PhysicalDiskGUID ); }).Friendlyname
If a physical disk number is recorded, as shown in Figure 1, you can use the following PowerShell command to identify the physical disk associated with the I/O error:
Get-PhysicalDisk -friendlyName <PhysicalDiskNumber>
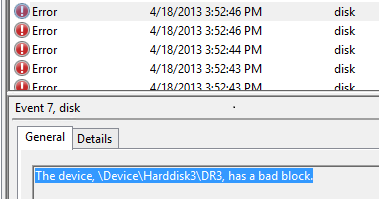
Figure 1: Event Viewer showing an error with physical disk 3
To illuminate the LED associated with the physical disk:
Enable-PhysicalDiskIndication –FriendlyName <PhysicalDiskNumber>
Using Server Manager
In the Storage Pools tile of the File and Storage Services role in Server Manager, health status that requires administrative action is identified as illustrated below, a yellow triangle with an exclamation point:
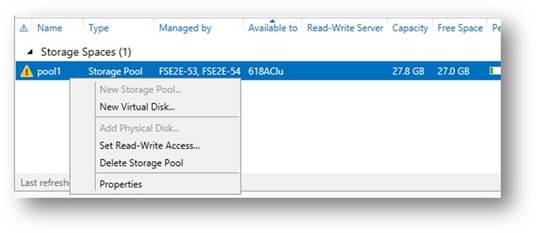
Figure 2: The Storage Pools tile in Server Manager
Figure 3: The Virtual Disks related tile in Server Manager
You can identify a drive using the "Toggle Drive Light" option:
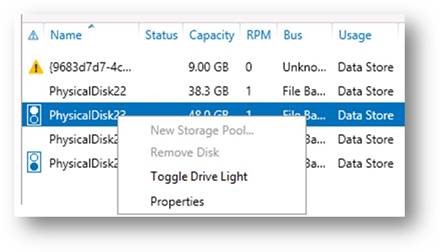
Figure 4: The Physical Disks related tile showing the Toggle Drive Light command
See Also
Events logged by Storage Spaces: