Microsoft and Hadoop - Windows Azure HDInsight
Traditionally Microsoft Windows used to be a sort of stepchild in Hadoop world – the ‘hadoop’ command to manage actions from command line and the startup/shutdown scripts were written in Linux/*nix in mind assuming bash. Thus if you wanted to run Hadoop on Windows, you had to install cygwin.
Also Apache Hadoop document states the following (quotes from Hadoop R1.1.0 documentation):
- GNU/Linux is supported as a development and production platform. Hadoop has been demonstrated on GNU/Linux clusters with 2000 nodes
- Win32 is supported as a development platform. Distributed operation has not been well tested on Win32, so it is not supported as a production platform.
Microsoft and Hortonworks joined their forces to make Hadoop available on Windows Server for on-premise deployments as well as on Windows Azure to support big data in the cloud.
This post covers Windows Azure HDInsight Service (Hadoop on Windows Azure, see https://www.hadooponazure.com) .
Note: As of writing, the service requires an invitation to participate in the CTP (Community Technology Preview) but the invitation process is very efficiently managed - after filling in the survey, I received the service access code within a couple of days.
New Cluster Request
To request a new cluster, you need to define the cluster name and the credentials to be able to login to the headnode. By default the cluster consists of 3 nodes.
http://bighadoop.files.wordpress.com/2012/11/newclusterrequest.png?w=584&h=423
{kind=link}
{kind=link}
After a few minutes, you will have a running cluster, then click on the “Go to Cluster” link to navigate to the main page.
http://bighadoop.files.wordpress.com/2012/11/hadooponazure-mainscreen.png?w=584&h=399
{kind=link}
{kind=link}
Running the WordCount Sample
No Hadoop test is complete without the standard WordCount application – Microsoft Azure HDInsight Service provides an example file (davinci.txt) and the Java jar file to run the wordcount sample - the Hello World of Hadoop.
First you need to go to the JavaScript Interactive Console to upload the text file using fs.put():
js> fs.put()
Choose File -> Browse
Destination: /user/istvan/example/data/davinci
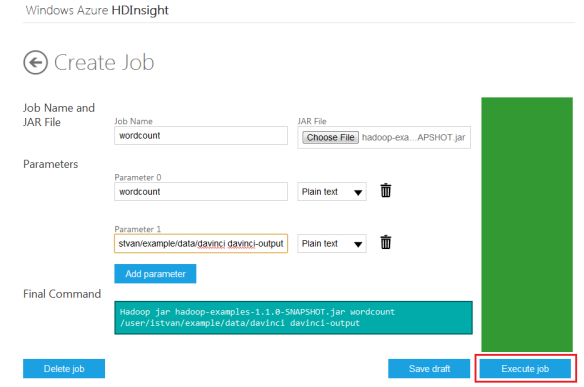
Next, click the Create a Job tile to create a MapReduce job.
http://bighadoop.files.wordpress.com/2012/11/createjob2.png?w=584&h=387
{kind=link}
The actual command that Microsoft Azure HDInsight Service executes is as follows:
c:\apps\dist\hadoop-1.1.0-SNAPSHOT\bin\hadoop.cmd jar c:\apps\Jobs\templates\634898986181212311.hadoop-examples-1.1.0-SNAPSHOT.jar wordcount /user/istvan/example/data/davinci davinci-output
You can validate the output from JavaScript console:
js> result = fs.read("davinci-output")
"(Lo)cra" 1
"1490 1
"1498," 1
"35" 1
"40," 1
"AS-IS". 1
"A_ 1
"Absoluti 1
"Alack! 1
Hadoop Streaming – Hadoop Job in C#
Hadoop Streaming is a utility to support running external map and reduce jobs. These external jobs can be written in various programming languages such as Python or Ruby – should we talk about Microsoft HDInsight, the example better be based on .NET C#…
The demo application for C# streaming is again a wordcount example using the imitation of Unix cat and wc commands. You could run the demo from the “Samples” tile but I prefer to demonstrate Hadoop Streaming from the command line to have a closer look at what is going on under the hood.
In order to run Hadoop command line from Windows cmd prompt, you need to login to the HDInsight headnode using Remote Desktop. First you need to click on “Remote Desktop” tile, then login the remote node using the credentials you defined at cluster creation time. Once you logged in, click on Hadoop Coomand Line shortcut.
In Hadoop Command Line, go to the Hadoop distribution directory (As of writing this post, Microsoft Azure HDInsight Service is based on Hadoop 1.1.0):
c:> cd \apps\dist
c:> hadoop fs -get /example/apps/wc.exe .
c:> hadoop fs -get /example/apps/cat.exe .
c:> cd \apps\dist\hadoop-1.1.0-SNAPSHOT
c:\apps\dist\hadoop-1.1.0-SNAPSHOT> hadoop jar lib\hadoop-streaming.jar -input "/user/istvan/example/data/davinci" -output "/user/istvan/example/dataoutput" -mapper "..\..\jars\cat.exe" -reducer "..\..\jars\wc.exe" -file "c:\Apps\dist\wc.exe" -file "c:\Apps\dist\cat.exe"
The C# code for wc.exe is as follows:
using System;
using System.IO;
using System.Linq;
namespace wc
{
class wc
{
static void Main(string[] args)
{
string line;
var count = 0;
if (args.Length > 0){
Console.SetIn(new StreamReader(args[0]));
}
while ((line = Console.ReadLine()) != null) {
count += line.Count(cr => (cr == ' ' || cr == '\n'));
}
Console.WriteLine(count);
}
}
}
And the code for cat.exe is:
using System;
using System.IO;
namespace cat
{
class cat
{
static void Main(string[] args)
{
if (args.Length > 0)
{
Console.SetIn(new StreamReader(args[0]));
}
string line;
while ((line = Console.ReadLine()) != null)
{
Console.WriteLine(line);
}
}
}
}
Interactive Console
Microsoft Azure HDInsight Service comes with two types of interactive console: one is the standard Hadoop Hive console, the other one is unique in Hadoop world, it is based on JavaScript.
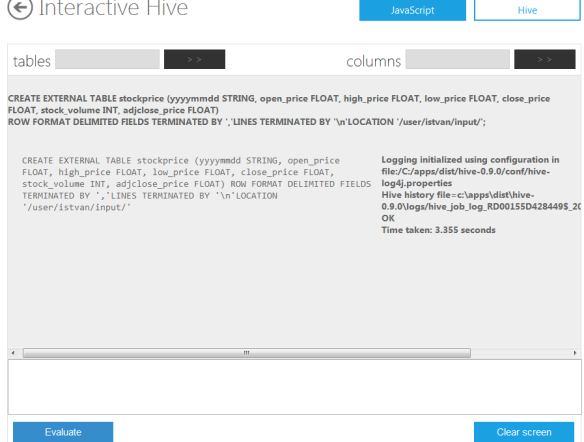
Let us start with Hive. You need to upload your data using the javascript fs.put() method as described above. Then you can create your Hive table and run a select query as follows :
CREATE TABLE stockprice (
yyyymmdd STRING,
open_price FLOAT,
high_price FLOAT,
low_price FLOAT,
close_price FLOAT,
stock_volume INT,
adjclose_price FLOAT)
row format delimited fields terminated by ','
lines terminated by '\n'
location '/user/istvan/input/';
select yyyymmdd, high_price, stock_volume from stockprice order by high_price desc;
http://bighadoop.files.wordpress.com/2012/11/interactivehive.png?w=584&h=442
{kind=link}
http://bighadoop.files.wordpress.com/2012/11/interactivehive-select.png?w=584&h=437
{kind=link}
The other flavor of HDInsight interactive console is based on JavaScript - as said before, this is a unique offering from Microsoft – in fact, the JavaScript commands are converted to Pig statements.
http://bighadoop.files.wordpress.com/2012/11/javascriptconsole.png?w=584&h=159
{kind=link}
The syntax resembles a kind of LINQ style query, though not the same:
js> pig.from("/user/istvan/input/goog_stock.csv", "date,open,high,low,close,volume,adjclose", ",").select("date, high, volume").orderBy("high DESC").to("result")
js> result = fs.read("result")
05/10/2012 774.38 2735900
04/10/2012 769.89 2454200
02/10/2012 765.99 2790200
01/10/2012 765 3168000
25/09/2012 764.89 6058500
Under the Hood
Microsoft and Hortonworks have re-implemented the key binaries (namenode, jobtracker, secondarynamenode, datanode, tasktracker) as executables (exe files) and they are running as services in the background. The key ‘hadoop’ command – which is traditionally a bash script – is also re-implemented as hadoop.cmd.
The distribution consists of Hadoop 1.1.0, Pig-0.9.3, Hive 0.9.0, Mahout 0.5 and Sqoop 1.4.2.