Introduction to Azure HDInsight
Note
This wiki topic is obsolete.
This wiki topic is no longer updated by Microsoft. We moved the content to windowsazure.com where we keep it current. To find the latest version of this topic, click here.
Overview ** **
Windows Azure HDInsight is a service that deploys and provisions Apache™ Hadoop™ clusters in the cloud, providing a software framework designed to manage, analyze and report on big data.test
Data is described as "big data" to indicate that it is being collected in ever escalating volumes, at increasingly high velocities, and for a widening variety of unstructured formats and variable semantic contexts. Big data collection does not provide value to an enterprise on its own. For big data to provide value in the form of actionable intelligence or insight, it must be accessible, cleaned, analyzed, and then presented in a useful way, often in combination with data from various other sources.
Apache Hadoop is a software framework that facilitates big data management and analysis. Apache Hadoop core provides reliable data storage with the Hadoop Distributed File System (HDFS), and a simple MapReduce programming model to process and analyze in parallel the data stored in this distributed system. HDFS uses data replication to address hardware failure issues that arise when deploying such highly distributed systems.
To simplify the complexities of analyzing unstructured data from various sources, the MapReduce programming model provides a core abstraction that provides closure for map and reduce operations. The MapReduce programming model views all of its jobs as computations over key-value pair datasets. So both input and output files must contain such key-value pair datasets. Other Hadoop-related projects such as Pig and Hive are built on top of HDFS and the MapReduce framework, providing higher abstraction levels such as data flow control and querying, as well as additional functionality such as warehousing and mining, required to integrate big data analysis and end-to-end management.
Windows Azure HDInsight makes Apache Hadoop available as a service in the cloud. It makes the HDFS/MapReduce software framework and related projects available in a simpler, more scalable, and cost efficient environment. To simplify configuring and running Hadoop jobs and managing the deployed clusters, Microsoft provides JavaScript and Hive interactive consoles. This simplified JavaScript approach enables IT professionals and a wider group of developers to deal with big data management and analysis by providing a more accessible path for them into the Hadoop framework.
It addition to the available Apache Hadoop-related ecosystem projects, Windows Azure HDInsight also provides Open Database Connectivity (ODBC) drivers to integrate Business Intelligence (BI) tools such as Excel, SQL Server Analysis Services, and Reporting Services, facilitating and simplifying end-to-end data analysis.
This topic describes Windows Azure HDInsight, the main scenarios for using Hadoop on Windows Azure, and provides a tour around the Windows Azure HDInsight dashboard. It contains the following sections:
Big Data: Volume, Velocity, Variety and Variability. - The qualities of big data that render it best managed by NoSQL systems like Hadoop, rather than by conventional Relational Database Management System (RDBMS).
The Hadoop Ecosystem on Windows Azure HDInsight - HDInsight provides Pig, Hive, Mahout, Pegasus, Sqoop, and Flume implementations, and supports other BI tools such as Excel, SQL Server Analysis Services and Reporting Services that are integrated with HDFS and the MapReduce framework.
Big Data Scenarios for Hadoop on Windows Azure - The types of jobs appropriate for using Hadoop on Windows Azure.
Tour of the Dashboard - Deploying clusters, managing your account, running samples, and the interactive JavaScript console.
Resources for HDInsight for Windows Azure - Where to find resources with additional information.
Big data: volume, velocity, variety, and variability
You cannot manage or process big data by conventional RDBMS because big data volumes are too large, or because the data arrives at too high a velocity, or because the data structures variety and semantic variability do not fit relational database architectures.
Volume
The Hadoop big data solution is a response to two divergent trends. On the one hand, because the capacity of hard drives has continued to increase dramatically over the last 20 years, vast amounts of new data generated by web sites and by new device and instrumentation generations connected to the Internet, can be stored. In addition, there is automated tracking of everyone's online behavior. On the other hand, data access speeds on these larger capacity drives have not kept pace, so reading from and writing to very large disks is too slow.
The solution for this network bandwidth bottleneck has two principal features. First, HDFS provides a type of distributed architecture that stores data on multiple disks with enabled parallel disk reading. Second, move any data processing computational requirements to the data-storing node, enabling access to the data as local as possible. The enhanced MapReduce performance depends on this design principle known as data locality. The idea saves bandwidth by moving programs to the data, rather than data to programs, resulting in the MapReduce programming model scaling linearly with the data set size. For an increase in the cluster size proportionately with the data processed volume, the job executes in more or less the same amount of time.
Velocity
The rate at which data is becoming available to organizations has followed a trend very similar to the previously described escalating volume of data, and is being driven by increased ecommerce clickstream consumer behavior logging and by data associated social networking such as Facebook and Twitter. Smartphones and tablets device proliferation has dramatically increased the online data generation rate. Online gaming ,scientific health instrumentation are also generating streams of data at velocities with which traditional RDBMS are not able to cope. Insuring a competitive advantage in commercial and gaming activities requires quick responses as well as quick data analysis results. These high velocity data streams with tight feedback loops require a NoSQL approach like Hadoop's optimized for fast storage and retrieval.
Variety
Most generated data is messy. Diverse data sources do not provide a static structure enabling traditional RDBMS timely management. Social networking data, for example, is typically text-based taking a wide variety of forms that may not remain fixed over time. Data from images and sensors feeds present similar challenges. This sort of unstructured data requires a flexible NoSQL system like Hadoop that enables providing sufficient structure to incoming data, storing it without requiring an exact schema. Cleaning up unstructured data is a significant processing part required to prepare unstructured data for use in an application. To make clean high-quality data more readily available, data marketplaces are competing and specializing in providing this service.
Variability
Larger issues in the interpretation of big data can also arise. The term variability when applied to big data tends to refer specifically to the wide possible variance in meaning that can be encountered. Finding the most appropriate semantic context within which to interpret unstructured data can introduce significant complexities into the analysis.
The Hadoop ecosystem on Windows Azure HDInsight
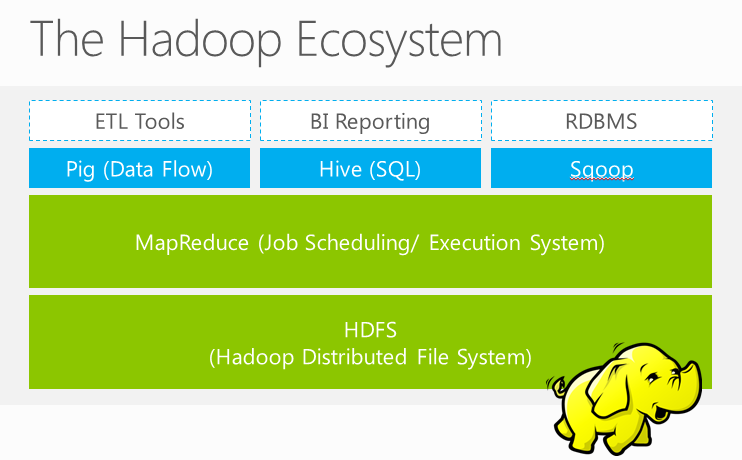
Introduction
Windows Azure HDInsight offers a framework that implements a Microsoft cloud-based solution for handling big data. This federated ecosystem manages and analyses large data amounts while exploiting parallel processing capabilities, other HDFS architecture optimizations, and the MapReduce programming model. Technologies such as Sqoop and Flume integrate HDFS with relational data stores and log files. Hive and Pig integrate data processing and warehousing capabilities. Pegasus provides graph-mining capabilities. Microsoft Big Data solution integrates with Microsoft BI tools, including SQL Server Analysis Services, Reporting Services, PowerPivot and Excel. Microsoft BI tools enable you to perform a straightforward BI on data stored and managed by the Hadoop ecosystem on Windows Azure HDInsight. The Apache-compatible technologies and sister technologies are part of this ecosystem built to run on top of Hadoop clusters are itemized and briefly described in this section.
Pig
Pig is a high-level platform for processing big data on Hadoop clusters. Pig consists of a data flow language, called Pig Latin, supporting writing queries on large datasets and an execution environment running programs from a console. The Pig Latin programs consist of dataset transformation series converted under the covers, to a MapReduce program series. Pig Latin abstractions provide richer data structures than MapReduce, and perform for Hadoop what SQL performs for RDBMS systems. Pig Latin is fully extensible. User Defined Functions (UDFs), written in Java, Python, C#, or JavaScript, can be called to customize each processing path stage when composing the analysis. For more information, see Welcome to Apache Pig!
Hive
Hive is a distributed data warehouse managing data stored in an HDFS. It is the Hadoop query engine. Hive is for analysts with strong SQL skills providing an SQL-like interface and a relational data model. Hive uses a language called HiveQL; a dialect of SQL. Hive, like Pig, is an abstraction on top of MapReduce and when run, Hive translates queries into a series of MapReduce jobs. Scenarios for Hive are closer in concept to those for RDBMS, and so are appropriate for use with more structured data. For unstructured data, Pig is better choice. Windows Azure HDInsight includes an ODBC driver for Hive, which provides direct real-time querying from business intelligence tools such as Excel into Hadoop. For more information, see Welcome to Apache Hive!
Mahout
Mahout is an open source machine-learning library facilitating building scalable matching learning libraries. Using the map/reduce paradigm, algorithms for clustering, classification, and batch-based collaborative filtering developed for Mahout are implemented on top of Apache Hadoop. For more information, see What is Apache Mahout .
Pagasus
Pegasus is a peta-scale graph mining system running on Hadoop. Graph mining is data mining used to find the patterns, rules, and anomalies characterizing graphs. A graph in this context is a set of objects with links that exist between any two objects in the set. This structure type characterizes networks everywhere, including pages linked on the Web, computer and social networks (FaceBook, Twitter), and many biological and physical systems. Before Pegasus, the maximum graph size that could be mined incorporated millions of objects. By developing algorithms that run in parallel on top of a Hadoop cluster, Pegasus develops algorithms to mine graphs containing billions of objects. For more information, see the Project Pegasus Web site.
Sqoop
Sqoop is tool that transfers bulk data between Hadoop and relational databases such a SQL, or other structured data stores, as efficiently as possible. Use Sqoop to import data from external structured data stores into the HDFS or related systems like Hive. Sqoop can also extract data from Hadoop and export the extracted data to external relational databases, enterprise data warehouses, or any other structured data store type. For more information, see the Apache Sqoop Web site.
Flume Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large log data amounts to HDFS. Flume's architecture is streaming data flow based. It is robust and fault tolerant with tunable and reliability mechanisms with many failover and recovery mechanisms. It has a simple extensible data model enabling online analytical applications. For more information, see the Flume incubation site.
Business intelligence tools
Familiar Business Intelligence (BI) tools such as Excel, PowerPivot, SQL Server Analysis Services and Reporting Services retrieves, analyzes, and reports data integrated with Windows Azure HDInsight using ODBC drivers. The Hive ODBC driver and Hive Add-in for Excel are available for download on the HDInsight dashboard.
* To install the driver and Add-in for Excel, see How To Connect Excel to Hadoop on Windows Azure via HiveODBC .
* For information Analysis Services, see SQL Server 2012 Analysis Services .
* For information Reporting Services, see SQL Server 2012 Reporting .
Big data scenarios for Windows Azure HDInsight
An exemplary scenario that provides a case for an Windows Azure HDInsight application is an ad hoc analysis, in batch fashion, on an entire unstructured dataset stored on Windows Azure nodes, which do not require frequent updates.
These conditions apply to a wide variety of activities in business, science, and governance. These conditions include, for example, monitoring supply chains in retail, suspicious trading patterns in finance, demand patterns for consumer utilities and services, air and water quality from arrays of environmental sensors, or crime patterns in metropolitan areas.
Hadoop is most suitable for handling a large amount of logged or archived data that does not require frequent updating once it is written, and that is read often, typically to do a full analysis. This scenario is complementary to data more suitably handled by a RDBMS that require lesser amounts of data (Gigabytes instead of Petabytes), and that must be continually updated or queried for specific data points within the full dataset. RDBMS work best with structured data organized and stored according to a fixed schema. MapReduce works well with unstructured data with no predefined schema because it interprets data when being processed.
Getting started with Windows Azure HDInsight
See Get Started with Windows Azure HDInsight
Resources for HDInsight for Windows Azure
Microsoft: HDInsight
- Welcome to Hadoop on Windows Azure - the welcome page for the Developer Preview for the Apache Hadoop-based Services for Windows Azure.
- Apache Hadoop-based Services for Windows Azure How To Guide - TechNet wiki with links to Hadoop on Windows Azure documentation.
- Big Data and Windows Azure - Big Data scenarios that explore what you can build with Windows Azure.
Microsoft: Windows and SQL Database
- Windows Azure home page - scenarios, free trial sign up, development tools and documentation that you need get started building applications.
- MSDN SQL Database - MSDN documentation for SQL Database
- Management Portal for SQL Database - a lightweight and easy-to-use database management tool for managing SQL Database in the cloud.
- Adventure Works for SQL Database - Download page for SQL Database sample database.
Microsoft: Business Intelligence
- Microsoft BI PowerPivot - a powerful data mashup and data exploration tool.
- SQL Server 2012 Analysis Services - build comprehensive, enterprise-scale analytic solutions that deliver actionable insights.
- SQL Server 2012 Reporting - a comprehensive, highly scalable solution that enables real-time decision making across the enterprise.
Apache Hadoop:
- Apache Hadoop - software library providing a framework that allows for the distributed processing of large data sets across clusters of computers.
- HDFS - Hadoop Distributed File System (HDFS) is the primary storage system used by Hadoop applications.
- Map Reduce - a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes.
See Also
- HDInsight for Windows landing page
Another important place to find an extensive amount of Cortana Intelligence Suite related articles is the TechNet Wiki itself. The best entry point is Cortana Intelligence Suite Resources on the TechNet Wiki.