Azure Hadoop: Degree Distribution Sample
Overview
This tutorial shows how to deploy Pegasus from the Hadoop on Azure portal to compute the degree of each node and the distribution of degrees for a simple 16-node graph. The degree distribution gives the number of nodes in the graph at each degree.
The degree of a node in a network (or graph) is the number of connections (or edges) that it has to other nodes. The degree distribution of a graph is the probability distribution of these degrees over the whole network. The degree distribution P(k) of a graph or network is the fraction of nodes with degree k. So if there are n nodes in total in a network and m(k) of them have degree k, then P(k) = m(k)/n.
A graph is type of abstract mathematical structure that consists of a collection of nodes and a collection of edges that connect a subset of these nodes, pairwise. The Web is a model of a graph structure, where pages are nodes and hyperlinks are edges. If a graph has edges that are directed, where edges point like a vector from one node to another node, then each node has two different types of degree: the in-degree, which is the number of incoming edges, and the out-degree, which is the number of outgoing edges. A graph can also have edges that are not directed and point toward both of the nodes that they connect, in which case the nodes are said to have in-out-degree.
Pegasus
Pegasus is an open source graph mining library implemented in a distributed manner on top of Hadoop. Pegasus provides large scale algorithms for various graph mining tasks:
- Degree
- PageRank
- Random Walk with Restart
- Radius
- Connected Components
This form of analysis is applicable to many networked structures other than the Web, such as computer and social networks, that model a graph.
People from School of Computer Science, Carnegie Mellon University developed Pegasus. For more information, see the Pegasus Project site.
Goals
In this tutorial you see three things:
How Pegasus input and output files are structured.
How to use the Hadoop on Azure to deploy a Pegasus page rank analysis.
How to use the Interactive Console in Hadoop on Azure to examine the results computed by Pegasus for the degree and degree distribution of the nodes.
Key technologies
Setup and configuration
You must have an account to access Hadoop on Azure and have created a cluster to work through this tutorial. To obtain an account and create an Hadoop cluster, follow the instructions outlined in the Getting started with Microsoft Hadoop on Azure section of the Introduction to Hadoop on Azure topic.
Tutorial
This tutorial is composed of the following segments:
- How to clean up a previous deployment of the Pegasus DegDist algorithm from Hadoop on Azure.
- How to deploy the DegDist algorithm in Pegasus from Hadoop on Azure.
- How to inspect the output from the Pegasus DegDist algorithm in the Interactive Console of Hadoop on Azure.
How to clean up a previous deployment of the Pegasus DegDist algorithm from Hadoop on Azure
This segment is only needed if you have already completed a deployment of the Pegasus page rank algorithm on the current Hadoop cluster.
From your Account page, scroll down to the Interactive Console icon in the Your cluster section and click the icon to open the console.
Enter the following commands at the js> prompt to delete the output directories from the previous job. If these directories exist, a new job fails.
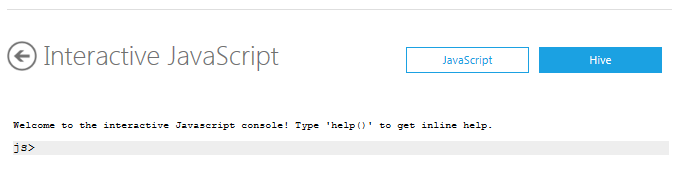
js> #rmr dd_node_deg
js> #rmr dd_deg_count
How to deploy the DegDist algorithm in Pegasus from Hadoop on Azure
From your Account page, scroll down to the Samples icon in the Manage your account section and click it to get to the Samples Gallery.
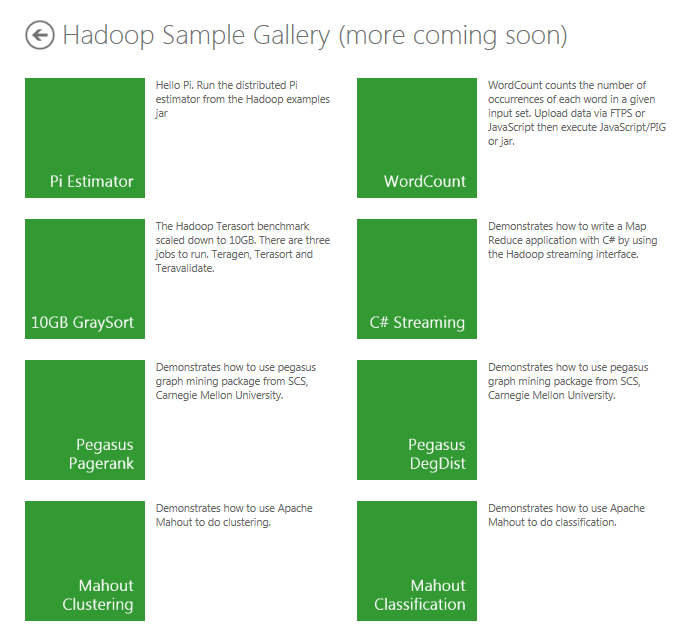
Click the Pegasus DegDist sample icon in the Hadoop Sample Gallery to open the Deployment page for the sample.
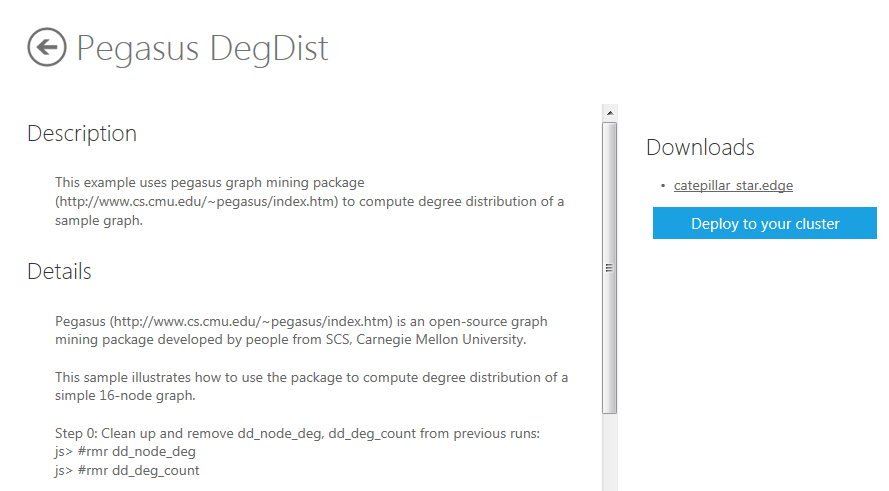
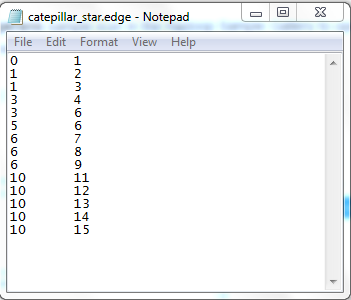
The caterpillar_star.edge file is the input file that contains the graph to be analyzed by Pegasus. Download it and open it with Notepad or any other program that opens text files. Each line specifies an edge in the graph. The format for a line is: source node Id followed by TAB followed by destination node Id. So if this file was for a graph of Web pages, the first line says that there is a hyperlink from the page with Id = 0 to the page with Id = 1.
Click the Deploy to your cluster to deploy the sample and bring up the Create Job page.
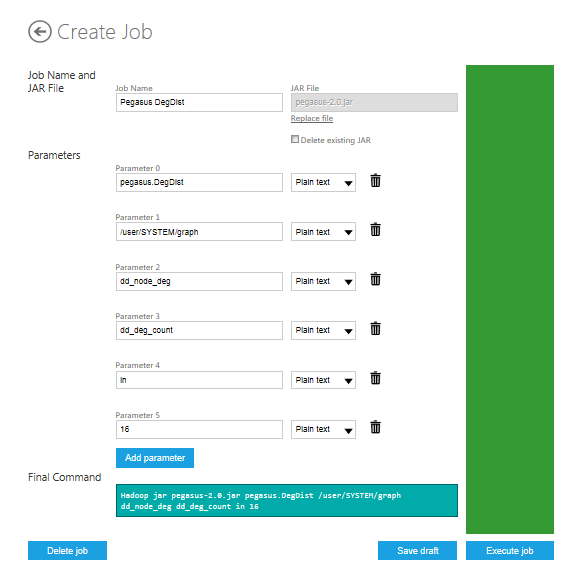
The Final Command, which begins,
"Hadoop jar pegasus-2.0.jar", takes six parameters. To run the runpr.sh command, Pegasus shell uses only the parameters that are highlighted in bold in the following parameter list. The first (pegasus.DegDist) parameter specifies the DegDist algorithm that uses runpr.sh command. The Hadoop on Azure portal require the others parameters.
- pegasus.DegDist - the Pegasus algorithm.
- /user/SYSTEM/graph - HDFS directory where input edge file is located.
- dd_node_deg - output directory for the degree distribution results.
- dd_deg_count - output directory for the degree distribution.
- in - type of degree to compute.
- 16 - the number of nodes.
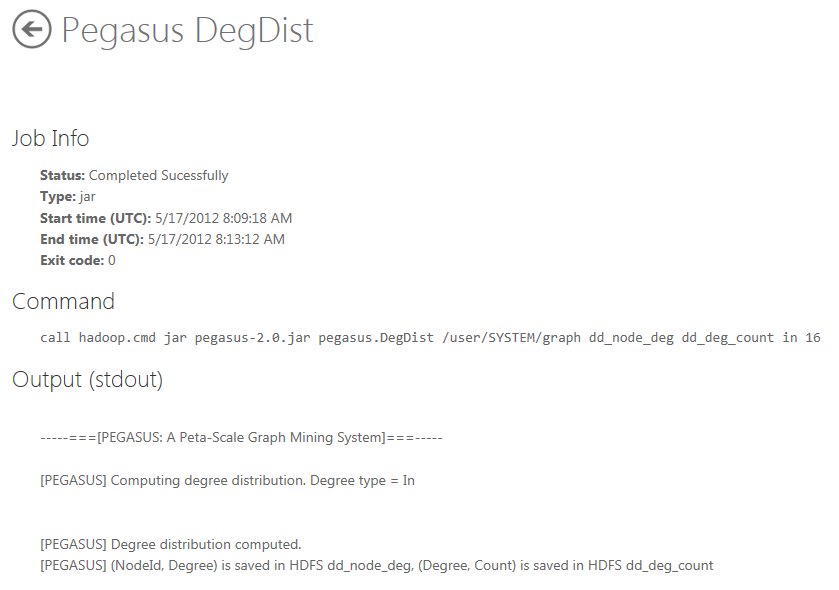
To start the job click the Execute job button. When it finishes, the Status at the Job Info section at the top of the page has the value "completed Successfully".
How to inspect the output from the Pegasus DegDist algorithm in the Interactive Console of Hadoop on Azure
Return to your Account page, scroll down to the Interactive Console icon in the Your cluster section and click the icon to open the console.
The default output directories for the Pegasus DegDist job are dd_deg_count and dd_node_deg. To locate the directories on the cluster, use the list command #ls from the js> prompt. To see the files in the dd_deg_count directory, use the following command:
#ls /user/bradsev/dd_deg_count
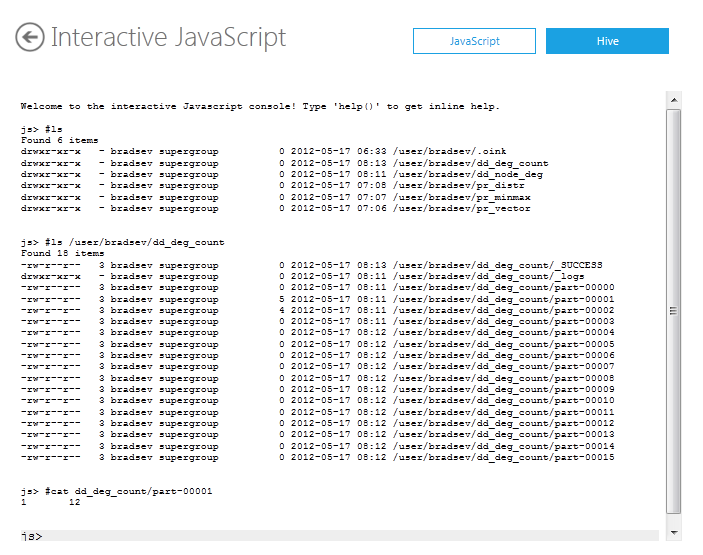
The results are in the files named part-nnnnn, where the nnnnn enumerates through the degrees of the nodes. To see the nodes that have a degree of one, use the following command:
#cat dd_deg_count/part-00001
Each line is in the format: degree - TAB - number of nodes with that degree. So the line 1 12 shown, for example, means that 12 nodes have degree of 1. The output for the other degrees can be similarly inspected.
To see the files in the dd_node_deg directory, use the following command:
#ls /user/bradsev/dd_node_deg
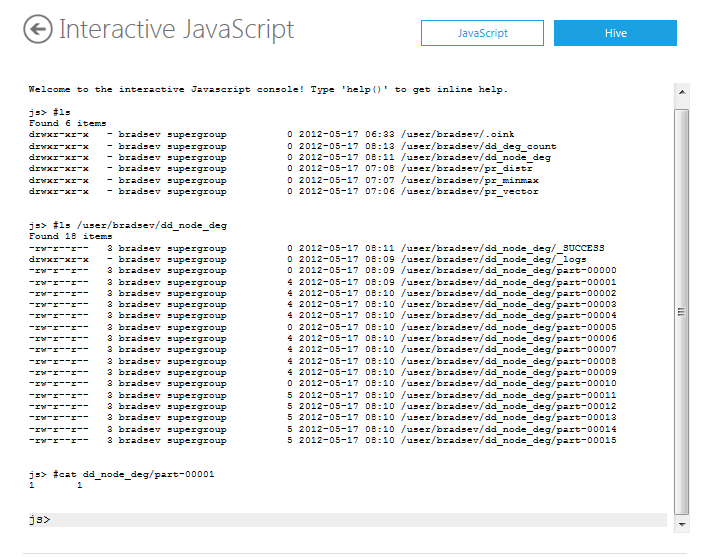
The results are in the files named part-nnnnn, where the nnnnn enumerates through the nodes. To see the degree of node with an Id of 1, use the following command:
#cat dd_node_deg/part-00001
Each line is in the format: nodeId - TAB - degreeofthe_node. So the line 1 1 shown, for example, means that the nodes with an Id of 1 has a degree of 1. The output for the other nodes can be similarly inspected.
Summary
In this tutorial, you have seen how Pegasus input and output files are structured for the computations of the node degrees and the degree distribution, how to use the Hadoop on Azure portal to deploy a Pegasus Pagerank analysis, and how to use the Interactive Console in Hadoop on Azure to examine the results of these computation.