HDInsight C# Hadoop Streaming Sample
MapReduce is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks. Most of the MapReduce jobs are written in Java. Hadoop provides a streaming API to MapReduce that enables you to write map and reduce functions in languages other than Java. This tutorial shows how to run the C# Streaming sample from the HDInsight Sample Gallery and how to use C# programs with the Hadoop streaming interface.
Before running this tutorial, you must have a Windows Azure HDInsight cluster provisioned. For more information on provision a HDInsight cluster, see Getting Started with Windows Azure HDInsight Service.
Estimated time to complete: 30 minutes.
In This Article
Hadoop Streaming
There is a communication protocol between the Map/Reduce framework and the streaming mapper/reducer utility that enables this approach. "The utility creates a Map/Reduce job, submit the job to an appropriate cluster, and monitor the progress of the job until it completes.
When an executable is specified for mappers, each mapper task launches the executable as a separate process when the mapper is initialized. As the mapper task runs, it converts its inputs into lines and" feeds the lines to the stdin of the process. In the meantime, the mapper collects the line-oriented outputs from the stdout of the process and converts each line into a key/value pair, which is collected as the output of the mapper. By default, the prefix of a line up to the first tab character is the key and the rest of the line (excluding the tab character) is the value. If there is no tab character in the line, then entire line is considered as key and the value is null.
When an executable is specified for reducers, each reducer task launches the executable as a separate process when the reducer is initialized. As the reducer task runs, it converts its input key/values pairs into lines and feeds the lines to the stdin of the process. In the meantime, the reducer collects the line-oriented outputs from the stdout of the process, converts each line into a key/value pair, which is collected as the output of the reducer. By default, the prefix of a line up to the first tab character is the key and the rest of the line (excluding the tab character) is the value." [haddoop.apache.org]
For more information on the Hadoop streaming interface, see Hadoop Streaming.
Access the HDInsight Sample Gallery
- Sign in to the Management Portal.
- Click HDINSIGHT. You shall see a list of deployed Hadoop clusters.
- Click the name of the HDInsight cluster where you want to run the MapReduce job.
- From the HDInsight dashboard, click Manage on the bottom of the page.
- Enter your credential, and then click Log On. Notice the Job History tile has a number on it. That indicates the number of jobs have been ran on this cluster. After you finish this tutorial, you shall see the number incrementing by 1.
- From the cluster dashboard, click the Samples tile. The are currently 5 samples deployed with the HDInsight cluster.
Understand the C# Code
"The MapReduce program uses the cat.exe application as a mapping interface to stream the text into the console and wc.exe application as the reduce interface to count the number of words that are streamed from a document. Both the mapper and reducer read characters, line by line, from the standard input stream (stdin) and write to the standard output stream (stdout)." [www.windows.azure.com]
From the Sample Gallery, click C# Streaming.
On the C# Streaming page, it contains the description, details, and the downloads. The downloads include:
Download Description Hadoop C# Streaming Excample.zip The word cound Map/Reduce program source code in C#. hadoop-streaming.jar The hadoop streaming jar file cat.exe The compiled C# Map program wc.exe The compiled C# Reduce program. davinci.txt The Map/Reduce job input file. Download and extract Hadoop C# Streaming Example.zip to your local computer, and open the solution file from Visual Studio. The source code for the cat.exe (Mapper) is: [www.windowsazure.com]
using System; using System.IO; namespace cat { class cat { static void Main(string[] args) { if (args.Length > 0) { Console.SetIn(new StreamReader(args[0])); } string line; while ((line = Console.ReadLine()) != null) { Console.WriteLine(line); } } } }*"The mapper code in the cat.cs file uses a StreamReader object to read the characters of the incoming stream into the console, which in turn writes the stream to the standard output stream with the static Console.Writeline method." *[www.windowsazure.com]
The source code for wc.exe (Reducer) is: [www.windowsazure.com]
using System; using System.IO; using System.Linq; namespace wc { class wc { static void Main(string[] args) { string line; var count = 0; if (args.Length > 0){ Console.SetIn(new StreamReader(args[0])); } while ((line = Console.ReadLine()) != null) { count += line.Count(cr => (cr == ' ' || cr == '\n')); } Console.WriteLine(count); } } }"The reducer code in the wc.cs file uses a StreamReader object to read characters from the standard input stream that have been output by the cat.exe mapper. As it reads the characters with the Console.Writeline method, it counts the words by counting space and end-of-line characters at the end of each word, and then it writes the total to the standard output stream with the Console.Writeline method." [www.windowsazure.com]
Deploy and Execute the Word Count MapReduce Job
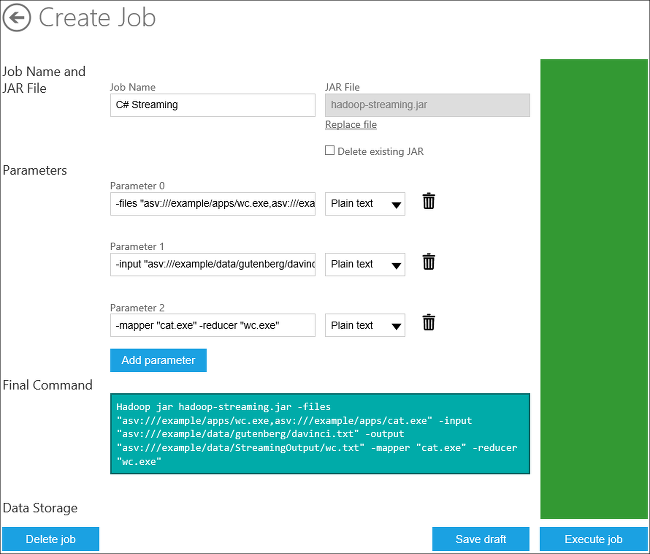
From the C# Streaming sample page, click Deploy to your cluster on the right side. It opens the Create Job interface with the fields populated:
The Parameter 0 is the path and the file name of the mapper and reducer; parameter 1 is the input file and output file path and name; and parameter 2 designates mapper and reducer executables.
The Final Command shows the actual command that will be used.
Click Execute job on the right-hand side of the page. Wait until you see the Status shows Completed Successfully.
If the job is taking too long, press F5 on the browser to refresh the screen.
Check the Result
You can use the Interactive JavaScript console to check the mapreduce job results.
Click Windows Azure HDInsight on the upper left corner to go back to the cluster dashboard. Notice the number on the Job History tile has been incremented by one.
Click Interactive Console.
Use the following commands to list the folder and display the result:
#lsr /example/data/StreamingOutput #cat /example/data/StreamingOutput/wc.txt/part-00000part-00000 is the default Hadoop output file name.
Summary
In this tutorial, you have seen how use C# programs with the Hadoop streaming interface.