Azure Hadoop: Pi Estimator Sample
Overview
This tutorial shows how to deploy a MapReduce program that uses a statistical (quasi-Monte Carlo) method to estimate the value of Pi. Points placed at random inside of a unit square also fall within a circle inscribed within that square with a probability equal to the area of the circle, Pi/4. The value of Pi can be estimated from the value of 4R where R is the ratio of the number of points that are inside the circle to the total number of points that are within the square. The larger the sample of points used, the better the estimate is.
The PiEstimator .java file contains the mapper and reducer functions and is available for download and inspection. The mapper program generates a specified number of points placed at random inside of a unit square and then counts the number of those points that are inside the circle. The reducer program accumulates points counted by the mappers and then estimates the value of Pi from the formula 4R, where R is the ratio of the number of points counted inside the circle to the total number of points that are within the square.
The larger the number of points used, the better the estimate of Pi. This sample submits a Hadoop JAR job and runs with a default value 16 maps, each of which computes 10 million samples by default. These default values can be changed to improve the estimated value of Pi. For reference, the first 10 decimal places of Pi are 3.1415926535.
The .jar file that contains the files needed by Hadoop on Azure to deploy the application is a .zip file and is available for download. You can unzip it with various compression utilities then explore the files at your convenience.
Goals
In this tutorial, you see several things:
A simple example of a MapReduce program written in Java.
How to use the Hadoop on Azure portal to run a MapReduce program.
Key technologies
Setup and configuration
You must have an account to access Hadoop on Azure and have created a cluster to work through this tutorial. To obtain an account and create a Hadoop cluster, follow the instructions outlined in the Getting started with Microsoft Hadoop on Azure section of the Introduction to Hadoop on Azure topic.
Tutorial
This tutorial is composed of the following segments:
Deploy the Pi Estimator MapReduce program to an Hadoop cluster
From your Account page, scroll down to the Samples icon in the Manage your account section and click it.
Click the Pi Estimator sample icon in the Hadoop Sample Gallery.
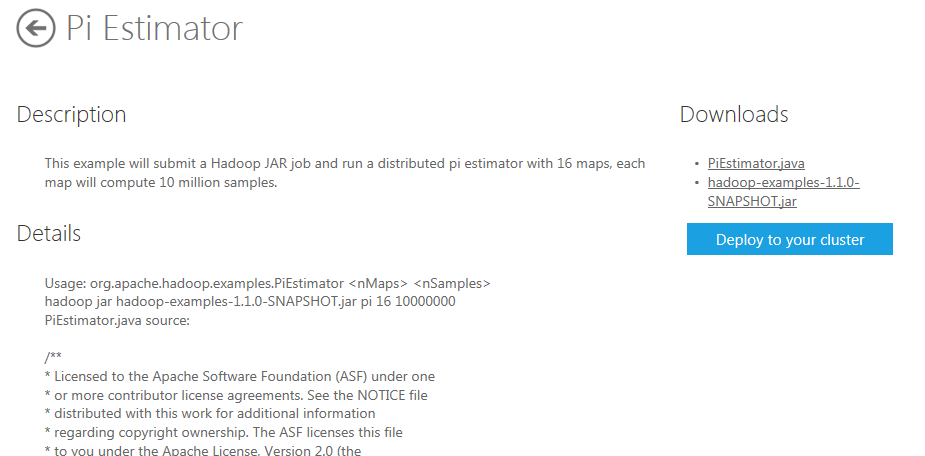
On the Pi Estimator page, information is provided about the application and downloads that are made available for Java MapReduce programs and the jar files that contains the files needed by Hadoop on Azure to deploy the application. The Java code is also available on the page and can be seen by scrolling down.
To deploy the job, click the Execute job button on the right side of the page.
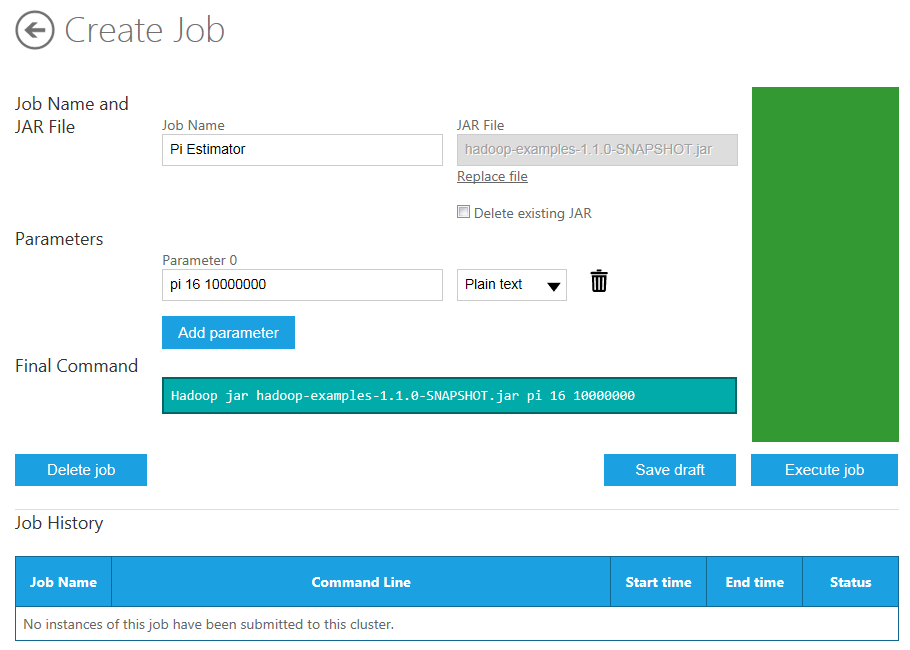
The first parameter (Parameter 0) value defaults to "pi 16 10000000". The first number indicates how many maps to create (default is 16) and the second number indicates how many samples are generated per map (10 million by default). So this program uses 160 million random points to make its estimate of Pi.
To run the program on the Hadoop cluster, click the blue Execute job button on the right side of the page.
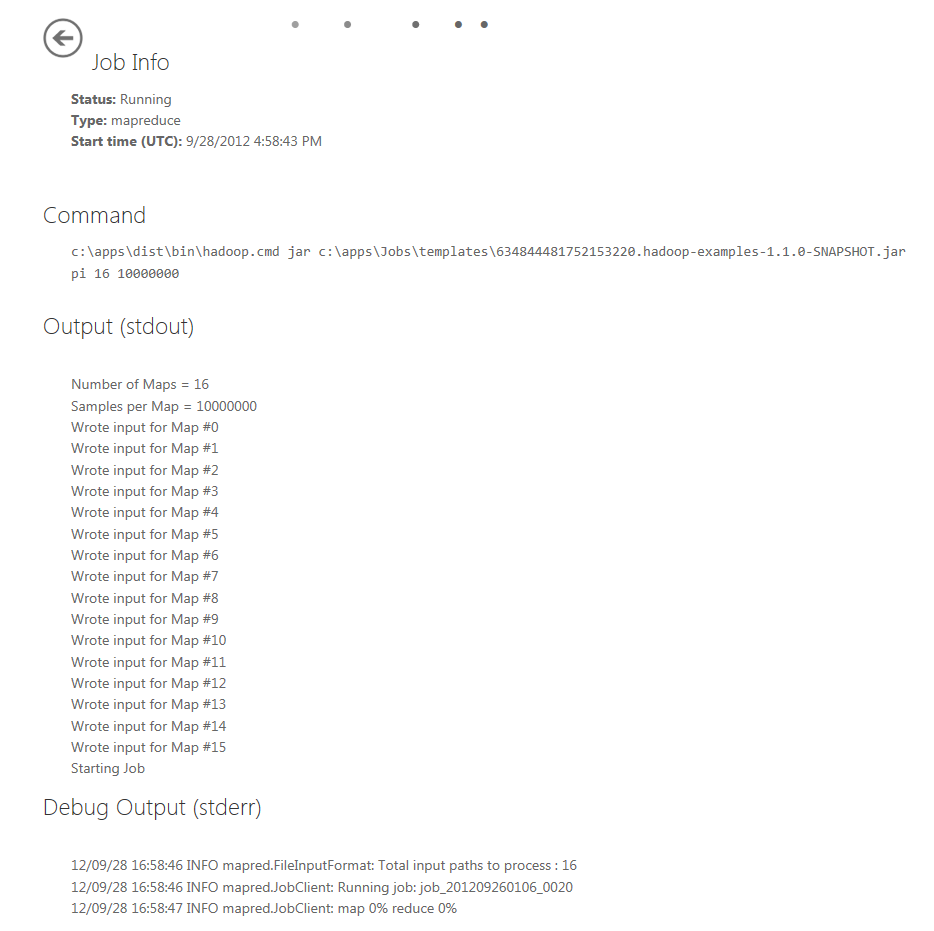
The status of the deployment is provided on the page in the Job Info section and should be Running until the job completes.
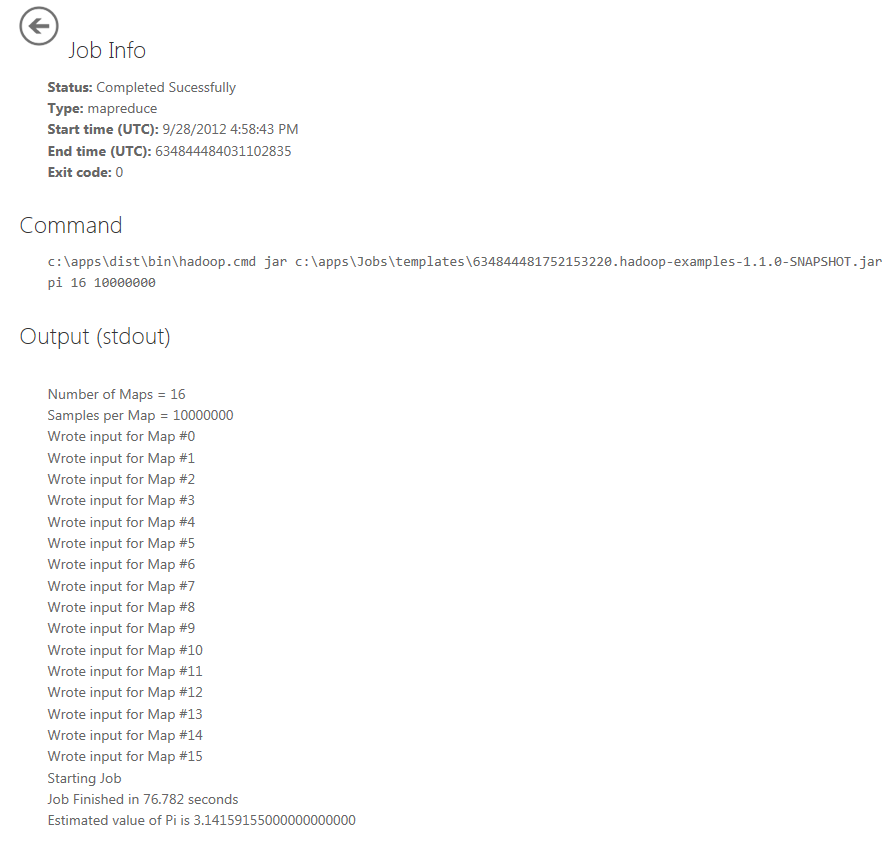
The program should take just over a minute to finish and when, assuming all is well, the status will change to Completed Successfully. The result is displayed at the bottom of the Output(stdout) section. For the default parameters, the result is (an 8 decimal number) Pi = 3.14159155000000000000 which is accurate to 5 decimal places, and to 6 places when rounded.
Summary
In this tutorial, you saw how to easy it was to deploy a set of MapReduce functions on an Hadoop cluster hosted on Windows Azure and how to use Monte Carlo methods that require large datasets that can be managed by Hadoop on Windows.