WSL System Calls
This is the third in a series of blog posts on the Windows Subsystem for Linux (WSL). For background information you may want to read the architectural overview and introduction to pico processes.
Posted on behalf of Stephen Hufnagel.
System calls
WSL executes unmodified Linux ELF64 binaries by emulating a Linux kernel interface on top of the Windows NT kernel. One of the kernel interfaces that it exposes are system calls (syscalls). This post will dive into how syscalls are handled in WSL.
Overview
A syscall is a service provided by the kernel that can be called from user mode which typically handle device access requests or other privileged operations. As an example, a nodejs webserver would use syscalls to access files on disk, handle network requests, create processes\threads, and other operations.
How a syscall is made depends on the operating system and the processor architecture, but it comes down to having an explicit contract between user mode and kernel mode called an Application Binary Interface (ABI). For most cases, making a syscall breaks down into 3 steps:
- Marshall parameters – user mode puts the syscall parameters and number at locations defined by the ABI.
- Special instruction – user mode uses a special processor instruction to transition to kernel mode for the syscall.
- Handle the return – after the syscall is serviced, the kernel uses a special processor instruction to return to user mode and user mode checks the return value.
While the Linux kernel and Windows NT kernel follow the steps above, they differ in ABI so they are not compatible. Even if the Linux kernel and Windows NT kernel had the same ABI, they expose different syscalls that do not always map one to one. For example, the Linux kernel includes things like fork, open, and kill while the Windows NT kernel has the comparable NtCreateProcess, NtOpenFile, and NtTerminateProcess. The following sections will go into the specifics of making syscalls in the different environments.
Syscall mechanics on Linux x86_64
The calling convention for syscalls on Linux x86_64 follow the System V x86_64 ABI defined here. As an example, one way to call the getdents64 syscall directly from a C program would be to use the syscall wrapper:
Result = syscall(__NR_getdents64, Fd, Buffer, sizeof(Buffer));
To discuss the syscall calling convention it’s easiest to translate the line of code into pseudo assembly to show the 3 steps above:
- mov rax, __NR_getdents64
- mov rdi, Fd
- mov rsi, Buffer
- mov rdx, sizeof(Buffer)
- syscall
- cmp rax, 0xFFFFFFFFFFFFF001
First, let’s look at how the parameters are marshaled. Steps 1-4 move the syscall parameters into the registers specified by the calling convention. Then on step 5 the special syscall instruction is made to transition to kernel mode. Finally, on step 6, the return value is checked by user mode.
Between steps 5 and 6 is where the Linux kernel handles the getdents syscall. When the syscall instruction is invoked, the processor performs a ring transition to kernel mode and starts executing at a specific function in kernel mode typically called the syscall dispatcher. As part of kernel initialization when the machine is booted, the kernel configures the processor to execute the syscall dispatcher with a specific environment when the syscall instruction is invoked. The first thing the Linux kernel will do in the syscall dispatcher is save off the user mode thread’s register state according to the ABI so that when the syscall returns the user mode program can continue executing with the expected register context. Then it will inspect the rax register to determine which syscall to perform and pass the registers off to the getdents syscall as parameters. Once the getdents syscall completes, the kernel restores the user mode register state, updates rax to contain the return value of the syscall, and uses another special instruction (usually sysret or iretq) that informs the processor to perform the ring transition back to user mode.
Syscall mechanics on NT amd64
The calling convention for syscalls on NT x64 follows the x64 calling convention described here. As an example, when the NtQueryDirectoryFile call is made we’ll have this simplified version of the call so it’s easier to compare against the getdents call above:
Status = NtQueryDirectoryFile(Foo, Bar, Baz);
The real NtQueryDirectoryFile API takes 11 parameters which would be strenuous for this example since it requires pushing arguments to the stack. Now let’s look at the disassembly side by side with the getdents case to see how the three steps are handled on NT compared to Linux:
| Step | Getdents | NtQueryDirectoryFile |
| 1 | mov rax, __NR_getdents64 | mov rax, #NtQueryDirectoryFile |
| 2 | mov rdi, Fd | mov rcx, Foo |
| 3 | mov rsi, Buffer | mov rdx, Bar |
| 4 | mov rdx, sizeof(Buffer) | mov r8, Baz |
| 5 | syscall | syscall |
| 6 | cmp rax, 0xFFFFFFFFFFFFF001 | test eax, eax |
For the marshalling parameters step, we see that NT also uses rax to hold the syscall number but differs in the registers used to pass the syscall parameters because it has a different ABI. For the special instruction step, we see syscall is also used since it is the preferred method on x64 for making syscalls. For the final step of checking the return, the code is slightly different because NTSTATUS failures are negative values whereas Linux failure codes fall into a specific range.
Just like with the Linux kernel, between steps 5 and 6 is where the NT kernel handles the NtQueryDirectoryFile syscall. This part is pretty much identical to Linux with some small exceptions around the ABI related to which user mode registers are saved and which registers are passed to NtQueryDirectoryFile. Since NT syscalls follow the x64 calling convention, the kernel does not need to save off volatile registers since that was handled by the compiler emitting instructions before the syscall to save off any volatile registers that needed to be preserved.
Syscall mechanics on WSL
After looking at how syscalls are made on NT compared to Linux, we can see that there are only a few minor differences around the calling convention. Next we’ll take a look at how syscalls are made on WSL.
The calling convention for syscalls on WSL follows the Linux description above since unmodified Linux ELF64 binaries are being executed. WSL includes kernel mode pico drivers (lxss.sys and lxcore.sys) that are responsible for handling Linux syscall requests in coordination with the NT kernel. The drivers do not contain code from the Linux kernel but are instead a clean room implementation of Linux-compatible kernel interfaces. Following the original getdents example, when the syscall instruction is made the NT kernel detects that the request came from a pico process by checking state in the process structure. Since the NT kernel does not know how to handle syscalls from pico processes it saves off the register state and forwards the request to the pico driver. The pico driver determines which Linux syscall is being invoked by inspecting the rax register and passes the parameters using the registers defined by the Linux syscall calling convention. After the pico driver has handled the syscall, it returns to NT which restores the register state, places the return value in rax, and invokes the sysret\iretq instruction to return to user mode.
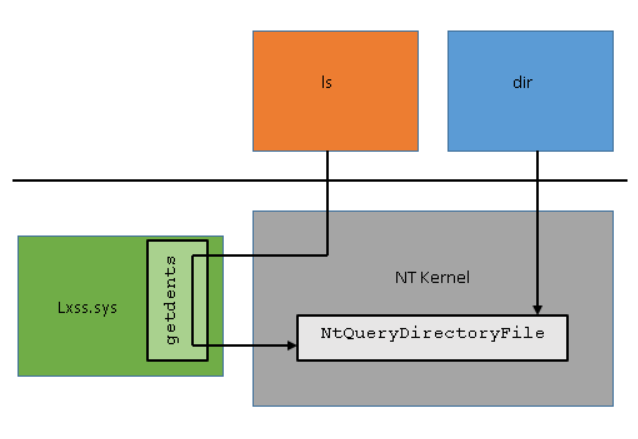
WSL syscall examples
Where possible, lxss.sys translates the Linux syscall to the equivalent Windows NT call which in turn does the heavy lifting. Where there is no reasonable mapping lxss.sys must service the request directly. This section will discuss a few syscalls implemented by WSL and the interaction with NT.
The Linux sched_yield syscall is an example that maps one to one with a NT syscall. When a Linux program makes the sched_yield syscall on WSL, the NT kernel hands the request off to lxss.sys which forwards the request directly to ZwYieldExecution which has similar semantics to the sched_yield syscall.
While sched_yield is an example of a syscall that maps nicely to an existing NT syscall, not all syscalls have the same properties even when there is similar functionality on NT. Linux pipes are a good example of this case since NT also has support for pipes. However, the semantics of Linux pipes are different enough from NT pipes, that WSL could not use NT pipes to get a fully featured Linux pipe implementation. Instead, WSL implements Linux pipes directly but still uses NT functionality for primitives like synchronization and data structures.
As a final example, the Linux fork syscall has no documented equivalent for Windows. When a fork syscall is made on WSL, lxss.sys does some of the initial work to prepare for copying the process. It then calls internal NT APIs to create the process with the correct semantics and create a thread in the process with an identical register context. Finally, it does some additional work to complete copying the process and resumes the new process so it can begin executing.
Conclusion
WSL handles Linux syscalls by coordinating between the NT kernel and a pico driver which contains a clean room implementation of the Linux syscall interface. As of this article, lxss.sys has ~235 of the Linux syscalls implemented with varying level of support. This support will continue to improve over time especially with the great feedback we get from the community.
Stephen Hufnagel and Seth Juarez explore how WSL redirects system calls.
Comments
- Anonymous
June 08, 2016
I wonder what is the plan for Linux 32-bit binaries when that is supported.- Anonymous
June 08, 2016
No official plans at this point, but we've looked at supporting x86\i386 and x32 emulation on 64bit and native x86\i386. This has come up before from the github community so please give us feedback on the user voice page so we can prioritize - https://wpdev.uservoice.com/forums/266908-command-prompt-console-bash-on-ubuntu-on-windo/suggestions/13377507-please-add-32-bit-elf-support-to-the-kernel.
- Anonymous
- Anonymous
June 08, 2016
Please start explaining what WSL is first for people coming from Hacker News etc.- Anonymous
June 08, 2016
Thanks for the feedback, there are two previously posted entries and the first gives an explanation of WSL:https://blogs.msdn.microsoft.com/wsl/2016/04/22/windows-subsystem-for-linux-overview/https://blogs.msdn.microsoft.com/wsl/2016/05/23/pico-process-overview/- Anonymous
June 08, 2016
Great, I already know it though. My comment was mostly about, when someone outside Microsoft ecosystem clicks on article, you start talking about WSL, but they probably do not know what it is, so if you start it like "WSL (Windows Subsystem for Linux)" they won't be as confused and start looking around what WSL might be. :-)- Anonymous
June 08, 2016
Says on top: "Windows Subsystem for LinuxThe underlying technology enabling the Windows Subsystem for Linux"Then first sentence links to https://blogs.msdn.microsoft.com/wsl/2016/04/22/windows-subsystem-for-linux-overview/I'm outside of Microsoft ecosystem and its perfectly clear what this provides. If I were to describe it to a laymen I'd describe it as something WSL is for Windows (in regards to Linux-x64) akin to what WINE is for *NIX. (I'm sure that's technically inaccurate as a comparison though.)
- Anonymous
- Anonymous
- Anonymous
- Anonymous
June 08, 2016
I'm very curious about some details. Just some minutia that's interesting to me.1. How does WSL handle vDSO?2. How does WSL emulate futex?3. How is fork() and clone() implemented on WSL? Traditional I know Windows didn't have fork() semantics for processes. Additionally, clone() has a complex list of flags that dictate how the process is created.- Anonymous
June 08, 2016
The comment has been removed
- Anonymous
- Anonymous
June 08, 2016
Any chance of making this translation layer open-source?- Anonymous
June 13, 2016
This is one of the top requests from the community, https://wpdev.uservoice.com/forums/266908-command-prompt-console-bash-on-ubuntu-on-windo, please give us feedback if you haven't already. - Anonymous
June 22, 2016
The real issue isn't lxss.sys being "open source" -- the real issue is whether somebody could make changes, rebuild it, and use their version instead. I seriously doubt MS would allow this. Even if you can build a new lxss.sys, if it's not properly signed, Windows won't load it. The kernel mode code signing requirements in Windows 10 are difficult for commercial developers to navigate, and would be almost impossible for individual hackers.
- Anonymous
- Anonymous
June 08, 2016
Was this idea inspired by the previous Windows Services for UNIX (https://en.wikipedia.org/wiki/Windows_Services_for_UNIX)? Was any of the previous stuff re-used?- Anonymous
June 09, 2016
I was gonna say, pretty sure NT does support fork, because that's how SUA/WSU supported fork. Also discussed at http://stackoverflow.com/a/985525/58074 - Anonymous
June 12, 2016
The comment has been removed - Anonymous
June 13, 2016
Yes, NT has supported different subsystems in the past and the other two videos have a brief discussion:https://blogs.msdn.microsoft.com/wsl/2016/04/22/windows-subsystem-for-linux-overview/https://blogs.msdn.microsoft.com/wsl/2016/05/23/pico-process-overview/WSL supports running native Linux binaries directly by emulating Linux kernel interfaces, whereas the previous Linux subsystems emulated Linux user mode and required recompilation\porting. The codebase couldn't be reused directly for that reason, but it was used for reference\comparison.
- Anonymous
- Anonymous
June 08, 2016
I'm curious, how did LXSS come to be? Is it true that it emerged from the work done on the cancelled Project Astoria? - Anonymous
June 09, 2016
Any estimate on when WSL will be available in standard (non-insider) windows builds? - Anonymous
June 09, 2016
The comment has been removed - Anonymous
June 10, 2016
Are you guys planning to give something back to the community? Like a Windows compatibility layer to let Linux users run unmodified Portable Executable (help Wine, maybe)? - Anonymous
June 11, 2016
Any word on when Ubuntu 16.04 will be available on Windows? - Anonymous
June 20, 2016
One of the presentations mentions that when the NT kernel receives a syscall, it first checks if the process in question is a pico process or e.g., a Win32 process. Do you happen to know some internal details behind this step? E.g., which kernel data structure is being examined?Thanks! - Anonymous
July 10, 2016
127008/63=2016/63=32 - Anonymous
July 12, 2016
Is there a list available of which Linux system calls are supported by the Windows Subsystem for Linux? Or are all Linux system calls supported with the initial release?- Anonymous
July 12, 2016
There is a list of currently supported syscalls available on in our MSDN Documentation. Keep in mind that all though this list currently enables most scenarios we don't guarantee that every flag or option is supported in the call.
- Anonymous
- Anonymous
July 12, 2016
The comment has been removed - Anonymous
July 12, 2016
Maybe it would be interesting to also detail some differences between this technology and e.g. cygwin. "Cygwin in Kernelspace" might be a bit short as an explainer otherwise - Anonymous
July 22, 2016
As an embedded systems dev who works in both Windows and Linux, I'm wondering about good old fashioned serial ports. Specifically, will I be able to access the Windows COM ports in /dev under WSL?- Anonymous
July 27, 2016
Maybe in later versions, but currently; noLinux version 3.4.0-Microsoft (Microsoft@Microsoft.com) (gcc version 4.7 (GCC) ) #1 SMP PREEMPT Wed Dec 31 14:42:53 PST 2014Linux WOC-PC 3.4.0+ #1 PREEMPT Thu Aug 1 17:06:05 CST 2013 x86_64 x86_64 x86_64 GNU/Linux
- Anonymous
- Anonymous
August 07, 2016
The comment has been removed- Anonymous
August 22, 2016
The comment has been removed
- Anonymous
- Anonymous
September 18, 2016
This is one of the most compelling reasons for me to adopt to Windows 10 Pro. Keep it up guys. Looking forward to a mature and robust WSL implementation. - Anonymous
January 26, 2017
I wonder how the linux ioctl() syscall is supported in lxss.sys. - Anonymous
January 28, 2017
You say that following the transition to Ring 0, the NT syscall dispatcher uses a magic flag in the "process structure" to decide whether to interpret the value in rax as an NT syscall number of a Linux one. My question is whether this process structure flag is modifiable by unprivileged user mode code? I guess I'm wondering if it would be possible to have a dual mode process that could make some syscalls as a Windows binary and others as a Linux one. - Anonymous
April 12, 2017
Copying everything at fork()-time is expensive; copy-on-write is expensive too. fork() is not really all that useful in a modern world, and, really, is very tough to get right.Much more interesting than fork() would be posix_spawn() and vfork(). posix_spawn() might require an extended CreateProcess() family function.With posix_spawn() you'd not need vfork(), naturally, except for compatibility reasons.vfork(2) could be implemented natively by the NT kernel. Or it could be emulated in user-land (with much, much care!) by creating a larval process for the subsequent execve() (so you can have its PID immediately available) that waits for instructions, the placing the caller's thread into a special mode (e.b., by setting a thread-local boolean) that records open(2), dup(2), dup2(2), close(2), (performing opens, but not the others) and other such system calls (ideally all functions in the async-signal-safe set!) and internally redirecting I/O in read(2)/write(2) and friends, then when the app does an execve(2) call, you would marshall up all those actions, pass them and any necessary file handles to the waiting child process for it to perform those recorded actions, then closing file descriptors and handles on the parent side that were never meant to be opened in the parent side. Similarly if the "child" exits: close handles opened by it, tell the waiting child to exit with the given code. When the "child" _exit()/execve() completes the thread in the parent would return to normal mode and longjump to trampoline that will "return" the child's PID. Complex, but much simpler and faster than fork(2) to a large degree. (Obviously lots of details are missing there, and it might turn out that emulating vfork(2) is ETOOHARD.)https://gist.github.com/nicowilliams/a8a07b0fc75df05f684c23c18d7db234- Anonymous
April 14, 2017
In theory, you're right.In practice, there's still lot's of software out there using fork() the traditional way, for either historical or portability reasons. (Do all the BSD and MacOS/iOS variants support vfork() or posix_spawn() by now? Not to speak of propritary Unices, GNU Hurd etc...)Additionally, according to https://msdn.microsoft.com/en-us/commandline/wsl/release_notes, vfork() was supported from the beginning. AFAICS, glibc implements posix_spawn based on vfork() or execve() (which is also supported by WSL), depending on the flags given, so I guess it doesn't need a specific syscall, and Linux also doesn't provide one.- Anonymous
April 18, 2017
It's true that a lot of software uses fork() because... it's the easy thing to do, vfork() has been unfairly vilified over the years, and posix_spawn() is not as easy to use. Also, some software uses fork() to start multiple worker processes where they don't exec and the parent doesn't exit either, and other software has the parent exit (e.g., to detach from a tty) -- these use-cases can't use anything other than fork() (hmmm, threads + vfork() might work, but I've not tested it), sadly, though I'm proposing an avfork() that would support that without copies nor COW:https://gist.github.com/nicowilliams/a8a07b0fc75df05f684c23c18d7db234So for now you do need a fork(), even if it's slow because it does full copies.Does WSL support mmap() with MAP_PRIVATE? I mean, does it support COW at all? If so you have the building block to implement a Unix-style fork()... Though even so, COW is very expensive, which is why typical implementations of fork() copy the RSS and apply COW for the rest.And yes, vfork() and posix_spawn() support are pretty universal across Linux, *BSD, Illumos, and OS X. I imagine AIX and HP-UX also have it, but I don't care to check. NetBSD even has posix_spawn() as a proper system call, which is pretty clever. - Anonymous
April 18, 2017
Also, congrats on implementing a vfork() system call. I'm glad you did. It can make a huge difference.
- Anonymous
- Anonymous