Как получить самые последние результаты поиска? Введение в непрерывный обход для SharePoint
Исходная статья опубликована в субботу, 15 сентября 2012 г.
Целевая аудитория: администраторы поиска, ИТ-специалисты
Необходимые условия: предполагается, что у читателя есть базовые знания об администрирования поиска в топологии поиска SharePoint, механизме обхода и принципах планирования обхода контента.
Примечание. Это новая возможность в SharePoint 2013.
Что такое свежесть результатов поиска?
После того как пользователь загрузит документ на сайт SharePoint, период времени, в течение которого документ будет доступен для поиска на портале поиска SharePoint, указывает задержку свежести.
От чего зависит свежесть?
От нескольких факторов: размера репозитория, частоты изменения, времени ответа на запросы от репозитория, расписания обхода и типов изменений. Это связано с тем, что для того, чтобы сделать документ доступным для поиска, необходимо запустить обход контента (вручную или автоматически по расписанию), а изменение нужно определить, запросить и обработать.
Так в чем проблема?
Обычно поиск SharePoint предоставлял два параметра: полный или инкрементный обход контента. Полный обход инициирует обнаружение для всего узла, а инкрементный обход обрабатывает только элементы хоста, которые изменились с момента последнего обхода, с использованием сравнения временной метки каждого документа или предварительно созданного журнала изменения для репозитория, который отслеживает измененные документы. Чтобы добиться лучшей свежести, рекомендуется сделать инкрементный обход более агрессивным (т. е. выполнять его каждые 30 минут, а не каждый день).
Одним из ограничений полного и инкрементного обхода является то, что они не могут выполняться параллельно. Т. е. если выполняется полный или инкрементный обход, администратор не может запустить другой обход в источнике контента. Это приводит к получению подхода FIFO при индексации элементов. Кроме того, некоторые типы изменений приводит к увеличению времени выполнения (например, изменение политики на корневом уровне узла значит, что весь узел нужно переиндексировать для обновления дескриптора безопасности каждого индексируемого элемента). Эти два фактора вместе приводят к колебанию свежести, даже если запланировано частое выполнение инкрементного обхода контента. Чтобы продемонстрировать это, далее представлена ментальная модель инкрементного обхода по сравнению с практическими ситуациями, и указана свежесть этой системы.
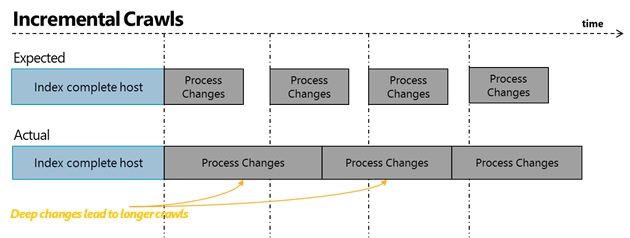

Как это исправить? Введение непрерывного контента.
Я рекомендую параметр обхода для источников контента SharePoint, который предоставляет альтернативный метод управления источником контента без использования расписания. Базовая архитектура предназначена для обеспечения постоянной свежести за счет устранения двух фундаментальных ограничений полного и инкрементного обхода:
- они могут работать параллельно;
- одно значительное изменение не приводит к ухудшению свежести для всех следующих изменений.
Дополнительные сведения.
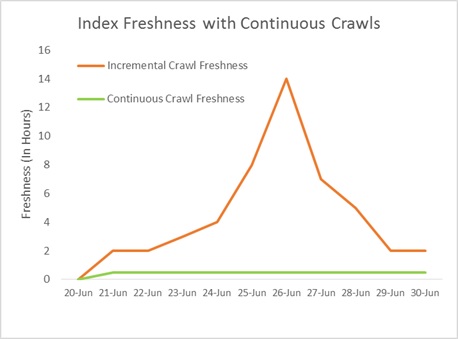
В фоне непрерывный обход приводит к запуску процесса обхода каждые 15 минут независимо от того, завершился ли предыдущий сеанс или нет. Это значит, что изменение, внесенное сразу после значительного изменения, не будет "дожидаться своей очереди". Новые изменения будут обрабатываться параллельно, по мере применения значительного изменения политики другим сеансом непрерывного обхода. Вот пример того, как процессы непрерывного обхода запускаются каждые 15 минут параллельно, что позволяет управлять неожиданными изменениями контента без ухудшения свежести. На следующем графике показано влияние на свежесть при использовании непрерывного обхода по сравнению с инкрементным обходом.

Итак, что еще нужно знать?
В последующих записях блога мы более подробно изучим, как непрерывный обход может обрабатывать различные сценарии (ошибки, безопасность и т. д.) и как можно использовать журнал и историю обхода для лучшего понимания происходящих процессов.
Вопросы и ответы.
Можно ли использовать непрерывный обход для всех типов источников контента?
Нет, непрерывный обход доступен только для источников контента SharePoint. Все другие типы источников будут использовать инкрементный и полный обход.
Повысит ли использование непрерывного обхода нагрузку на репозиторий?
Нагрузка непрерывного обхода аналогична нагрузке инкрементного обхода. Хотя частоты запросов увеличена, максимальное число одновременных запросов для одного репозитория или узла будет контролироваться правилами влияния на обход (которые определяют максимальное число параллельных потоков, которые могут создавать запросы, которое по умолчанию равно 12, но которое можно изменить в соответствии с бизнес-требованиями или планом мощности).
Требуется ли настраивать инкрементный или полный обход при использовании непрерывного обхода?
При использовании непрерывного обхода нет необходимости настраивать инкрементный обход.
Повысит ли непрерывный обход нагрузку на узел или репозиторий?
Непрерывный обход повышает нагрузку на узел, так как он может запускать множество сеансов параллельно. Но следует отметить, что при этом учитывается параметр "Правило влияния на обход", который контролирует максимальное число запросов к узлу (который задан в OOB как 12 потоков, но это значение можно изменить).
Можно ли использовать непрерывный обход для обхода предыдущих версий контента SharePoint?
Да, хотя приложение поиска должно соответствовать версии 2013, фермы контента с более старыми версиями SharePoint можно настроить для непрерывного обхода.
Это локализованная запись блога. Исходная статья доступна по адресу: How can I achieve the best freshness of search results? Introducing Continuous Crawls for SharePoint