如何获得最佳的搜索结果新鲜度?SharePoint 的连续爬网简介
原文发布于 2012 年 9 月 15 日(星期六)
受众:搜索管理员/IT 专业人员
先决条件:本博客假设读者具有关于 SharePoint 搜索拓扑、爬网机制和爬网计划原理的基本搜索管理知识。
注意:此功能是 SharePoint 2013 的新功能。
什么是搜索结果的新鲜度?
从用户将文档上载到其 SharePoint 网站,到能够通过 SharePoint 搜索门户“搜索”到该文档之间的时间段即表示新鲜度的延迟。
新鲜度取决于什么?
多种因素——存储库的大小、变化速率、存储库的请求响应时间、爬网计划、变化类型。这是因为,要使文档可被“搜索”到,需要触发爬网(手动或按计划自动),还需要识别、请求和处理变化。
所以,问题是什么?
传统上,SharePoint 搜索中有两种计划选项——完全或增量爬网。完全爬网会搜索整个主机,而增量爬网只会处理自上次爬网以来主机中发生变化的项,这通过比较每个文档的时间戳或者利用该存储库预先存在的记录文档修改情况的更改日志来确定。为了获得更高的新鲜度,建议的方法是更积极地进行增量爬网(即,每天一次改为每 30 分钟一次)。
完全爬网和增量爬网的一个限制是,它们无法并行运行,也就是说,如果正在进行完全爬网或增量爬网,管理员无法对该内容源启动另一种爬网。这会将索引项目的方式强制为先进先出。此外,一些类型的变化会导致运行时间延长(例如,主机根级别的策略更改意味着需要重新索引整个主机才能更新每个已索引项目的安全描述符)。这两个因素结合在一起导致新鲜度发生波动,即使设置频繁的增量爬网计划也是如此。为了说明这一点,下面给出了期望的增量爬网思维模型与实际情况的对比,然后是该系统的新鲜度。
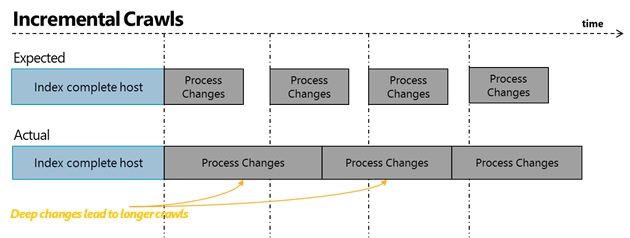

解决方法是什么?连续爬网简介
我为 SharePoint 型内容源推荐一种爬网选项,它提供免计划的内容源管理的替代方案。其基础架构设计为通过克服完全/增量爬网的两个基本限制来确保一致的新鲜度:
- 它们可以并行运行
- 一个深度更改不会导致后面所有更改的新鲜度降级
了解更多…
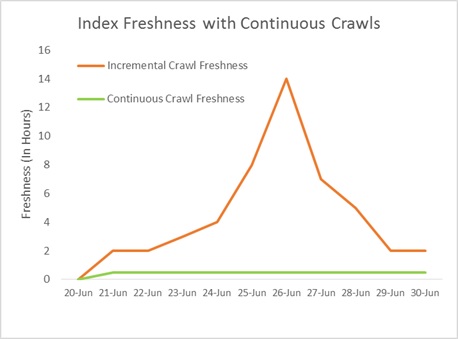
在后台,选择连续爬网会使爬网每 15 分钟启动一次,而不管之前的会话是否完成。这意味着在深度更改后可立即进行更改,无需在后面“等待”。 新更改将继续作为深度策略更改由另一个连续爬网对话以并行方式进行处理。这是连续爬网如何每 15 分钟并行启动一次来帮助管理突发内容峰值而不影响整体新鲜度的说明。下图说明了使用连续爬网取代增量爬网后对新鲜度的影响。

还需要了解什么?
在以后的博客中,我们将详细介绍连续爬网如何处理不同类型的情形(错误、安全等),以及如何通过爬网日志和爬网历史记录更好地了解后台情况。
常见问答:
能否对所有类型的内容源都使用连续爬网?
不能。连续爬网仅适用于 SharePoint 型内容源。所有其他类型的内容源将继续选择增量爬网和完全爬网。
>使用连续爬网是否会给存储库增加额外负载?
连续爬网的资源占用与增量爬网相似。当发出请求的频率增加后,对一个存储库/主机的并发请求最大数仍将由 *爬网影响规则* 控制。该规则定义了可发出请求的并发线程的最大数,最大数默认设置为 12 个线程,但可以根据业务要求和/或容量计划进行更改。
>使用连续爬网时是否需要设置增量爬网或完全爬网?
使用连续爬网时不需要配置增量爬网。
>连续爬网是否会给主机/存储库增加额外负载?
连续爬网将给主机增加少量负载,因为它本身可同时并行运行多个会话。但应当注意,它将遵守用于控制可向主机发出并发请求的最大数的“爬网影响规则”(OOB 设置为 12 个线程,但可以更改)
>能否使用连续爬网对以前版本的 SharePoint 内容进行爬网?
可以 -- 尽管搜索应用程序需要是 2013 版,但运行早期版本 SharePoint 的内容服务器场仍可配置为连续爬网。
这是一篇本地化的博客文章。请访问 How can I achieve the best freshness of search results? Introducing Continuous Crawls for SharePoint 以查看原文