Alta Disponibilidade com SQL Server
Alta disponibilidade é um assunto obrigatório quando falamos em servidores corporativos de banco de dados. Em qualquer segmento do mercado podemos citar exemplos de aplicações que não podem parar de funcionar: desde o controle de uma balança de caminhões na estrada até a emissão de passagens aéreas. Hospitais são um dos exemplos com o qual eu mais gosto de pensar quando falamos em missão crítica.
Meu professor de guitarra dizia a alguns anos que eu parecia médico, pois, quando eu trabalhava com suporte e precisava fazer plantão, ficava disponível 24 horas por dia no período de uma semana, que era o meu período de plantão em um mês. Mas eu acho que, por maior que seja o prejuízo de um sistema parado, nenhum supera o prejuízo de uma vida perdida ou de um atendimento de emergência que não pôde ser iniciado. Então quem faz missão crítica mesmo são os médicos e enfermeiros, não nós, meros geeks da área de TI J
Vamos voltar aos nossos prejuízos por causa de aplicações paradas. Os prejuízos podem ser em receita (entrada de pedidos, vendas), em aumento de custos (caminhões parados, utilização de processos manuais ou de contingência) e até mesmo na imagem da empresa (atendimento a clientes, emissão de passagens, entrega de produtos), entre outros. O SQL Server oferece diversas alternativas para atingirmos níveis non-stop de alta disponibilidade. É a abordagem que a Microsoft chama de Always On Technologies. No caso do SQL Server, seja com soluções como clusters geográficos ou outras muito simples e baratas como o Database Mirroring, os níveis alcançados de alta disponibilidade atendem as necessidades de negócio, independente do tamanho ou complexidade da aplicação. Neste post, vamos explorar algumas das alternativas de alta disponibilidade oferecidas pelo SQL Server 2005 e como elas foram melhoradas no SQL Server 2008. Mãos a obra.
Antes de tudo, porque tantas opções?
Uma pergunta freqüente é: porque existem tantas opções para resolver o mesmo problema? As diversas opções de alta disponibilidade oferecidas pelo SQL Server visam atender a qualquer cenário, não importa o tamanho da empresa. Seja um banco de dados de 100MB ou de 30TB, uma aplicação distribuída contra uma centralizada, temos uma solução mais apropriada para cada cenário. O que se deve fazer é olhar caso a caso e optar pela melhor opção. E, porque não, utilizar as opções de alta disponibilidade combinadas.
Database Mirroring
O Database Mirroring foi introduzido ao SQL Server 2005 como parte do Service Pack 1. Trata-se de uma tecnologia que permite atingir os maiores níveis de alta disponibilidade de uma forma muito simples e barata. Ele permite espelhar um banco de dados em outro servidor, aplicando quaisquer alterações no banco de dados no servidor principal instantaneamente no servidor de espelho.
Dependendo da forma como o Database Mirroring for configurado, o failover para o servidor de mirror pode ser automático, sem necessidade de chaveamento manual na aplicação. Isto é feito através da utilização de um servidor chamado witness (testemunha) que monitora a disponibilidade do servidor principal e “notifica” as aplicações que se conectam a ele a chavearem para o servidor de mirror. (as aplicações procuram pelo witness através de um parâmetro em sua connection string) Muito simples de configurar e manter, tem sido amplamente utilizado no mercado.
Quanto a desempenho, pode-se configurar se as transações serão enviadas em tempo real (de forma síncrona) ou com um pequeno atraso (de forma assíncrona). Isto permite balancear a carga de rede e de processamento.
No SQL Server 2008, o Database Mirroring foi melhorado. Ele compacta os dados que são enviados entre os servidores, gerando uma carga menor em rede. Além disso, a proteção dos dados passa a ser feita por páginas (pages of data): se uma página estiver corrompida, tanto no servidor principal quanto no mirror, o mecanismo do Database Mirroring toma o cuidado de recuperar a página a partir do outro servidor.
O que torna o Database Mirroring uma solução barata, afinal de contas? Vários fatores. Um dos principais é o fato de não precisar de hardware específico, como um cluster, por exemplo, que exige um disco compartilhado e hardware para cluster. Outro ponto importante é que se o servidor onde fica o mirror não for utilizado para consultas de outras bases de dados (apenas em stand by), não é necessário pagar a licença do SQL Server que está atuando como mirror. Esta configuração é chamada de cold backup. A partir do momento que a instancia de cold backup passa a ser utilizada, ainda que apenas para leitura, se faz necessário licenciar também este servidor. Porém, no caso de um failover, o servidor de backup pode ficar no ar até trinta dias no lugar do principal, sem que seja necessário pagar a licença do cold backup.
Log Shipping
O Log Shipping é uma tecnologia de alta disponibilidade que aplica logs transacionais em uma cópia do banco de dados com certa periodicidade, garantindo uma cópia atualizada do banco de dados na rede. Embora o tempo de atraso entre a aplicação destes logs no servidor secundário possa resultar em um banco de dados desatualizado no destino, pode-se utilizar a base secundária para leitura dos dados e recuperação caso ocorra um erro humano na base principal.
O Log Shipping está disponível desde versões anteriores do SQL Server e também é utilizado amplamente.
Failover Clustering
Geralmente o Failover Clustering é a solução mais comum quando falamos em alta disponibilidade. O SQL Server usufrui do serviço de cluster do Windows Server para garantir alta disponibilidade em caso de falha de hardware. O serviço de cluster do Windows Server (Microsoft Cluster Service) garante que serviços hospedados em um servidor sejam movidos a outro em caso de falha de hardware, com queda mínima no tempo de serviço (pouco maior do que o Database Mirroring). Esta solução requer hardware específico, sendo esta a principal desvantagem. Os servidores que são membros do cluster acessam um mesmo sistema de discos, que é compartilhado entre todos os membros do cluster.
O cluster é muito simples de se configurar, tendo todos os pré-requisitos atendidos. Da parte do Windows Server, um simples assistente faz a configuração. No caso do SQL Server, durante a instalação você marca uma opção dizendo que irá “clusterizar” recursos como o Database Engine ou o Analysis Services, escolhe os nós (nodes) do cluster que farão parte da instalação do SQL Server e o programa de instalação toma os devidos cuidados. Ao contrário do que muitas pessoas pensam, a versão Standard do SQL Server 2005 suporta a configuração de cluster de dois nós (nodes).
A principal novidade no SQL Server 2008 é o fato de não precisar de um drive lógico para cada instância SQL no cluster: agora várias instâncias podem utilizar um mesmo drive lógico (“G:“, por exemplo), o que deverá viabilizar mais a instalação de múltiplas instâncias SQL Server em um mesmo cluster. Além disto, agora será possível suportar 16 nós (nodes) em um cluster, mas este é na verdade um benefício do Windows Server 2008.
Geographically Dispersed Failover Clustering
Imagine um cluster separado fisicamente, com replicação de storage. Isto é o Geographically Dispersed Failover Clustering. A grande vantagem dele sobre o cluster comum é exatamente a característica de replicação do storage, que elimina um ponto de falha na solução. Na eventual falha do sistema de discos de um dos nós, todo o controle é cedido ao servidor secundário, que tem uma réplica dos dados.
Peer-to-Peer Replication
Entre os vários modelos de replicação do SQL Server, talvez este seja o que melhor se aplica ao tema alta disponibilidade. A replicação Peer-To-Peer permite que os dados sejam replicados entre dois ou mais servidores, não importa onde as alterações ou inserções estão sendo feitas. Para este cenário, no entanto, as aplicações precisam ser desenhadas de modo que sejam direcionadas a um dos servidores em específico, já que o SQL Server não faz resolução de conflitos (para isto, veja merge replication). Esta solução é especialmente apropriada quando falamos em servidores que estão separados por distâncias maiores.
Até o SQL Server 2005, o processo de replicação precisava ser interrompido caso houvesse a necessidade de adicionar um servidor a topologia de replicação. No SQL Server 2008, no entanto, este não é o caso: servidores podem ser adicionados à topologia de replicação sem parada da replicação.
Downtime Reduzido
Além das tecnologias citadas acima, vários recursos internos do SQL Server permitem uma maior disponibilidade do sistema. Alguns deles são:
- Fast Database Recovery: disponibiliza parcialmente os bancos de dados durante o processo de recovery (enquanto faz rollback de algumas transações, por exemplo) , durante o failover em Database Mirroring e em processos de restore.
- Backup and Restore: o processo de backup e restore permite que você faça cópias em várias unidades de fita, por exemplo, (também pode ser em disco) para ajudar em casos de perda ou de comprometimento da mídia de backup. O SQL Server também gera checksums para poder fazer verificações na fase de restore. No SQL Server 2008 a novidade é poder fazer backup comprimidos, que podem reduzir o número de fitas necessárias para o backup significativamente.
- Checksum on Data Pages: compara os valores escritos no disco aos valores lidos do checksum (aplicando-se um algoritmo de verificação). Se não coincidirem, a página é marcada como suspect e precisa ser restaurada.
- Online Index Operations: outro dia falei sobre isto em um cliente e ele disse: “-O SQL Server realmente faz isso?”. Faz sim!Desde o SQL Server 2005, é possível fazer manutenção em índices sem afetar a disponibilidade.
- Online Piecemeal and Page-Level Restore: no SQL Server 2008, permite que se faça o restore dos filegroups por partes, deixando disponíveis os dados já restaurados. Também permite que se faça o restore de páginas corrompidas.
- Partial Database Availability: deixa um banco de dados disponível mesmo se parte dele estiver comprometida (por falha em um disco, por exemplo)
- Snapshot Isolation: garante que registros sejam lidos mesmo durante alteração dos dados, a partir da visualização de versões de uma linha. Aumenta a disponibilidade pelo fato de reduzir os tempos de lock substancialmente. Eu considero este um dos principais benefícios do database engine do SQL Server 2005 em relação a versões anteriores.
- Dynamic Configuration: possibilidade de fazer upgrade de hardware sem parar o serviço. Como um exemplo, adicione memória em um servidor ligado (desde que o hardware dê suporte a isto) e disponibilize esta memória para o SQL Server sem parar o servidor. No SQL Server 2008, a novidade é o suporte a adição de processadores sem parar o servidor.
Perceba que alguns destes recursos estão disponíveis apenas na edição Enterprise do SQL Server. Para uma tabela comparativa entre as diferentes edições visite https://www.microsoft.com/sql/prodinfo/features/compare-features.mspx
Outro fator importante que precisa ser lembrado é que o SQL Server oferece todos os recursos citados acima out-of-box. Não é necessário pagar nada a mais para ter o Database Mirroring ou o Failover Cluster, por exemplo.
Conclusão
O SQL Server oferece diversas soluções para atingir níveis de alta disponibilidade. Embora sejam soluções individuais e auto-suficientes (não dependem necessariamente uma da outra), elas podem ser utilizadas em conjunto para atingir maiores níveis de alta disponibilidade, como no cenário abaixo:
|
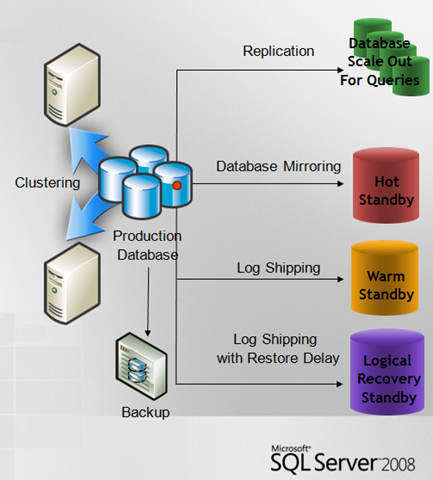 |
Não importa o tamanho do seu negócio ou a complexidade da sua aplicação: O SQL Server é o servidor de banco de dados ideal para atingir alta disponibilidade com baixos custos.
Comments
Anonymous
March 07, 2008
Olá Péricles, tudo certo? Mais uma vez, um excelente post que consegue consolidar muito bem um dos principais ativos de um banco de dados, que a alta disponibilidade. Parabéns pelo excelente blog! []s Waldemir.Anonymous
March 28, 2008
The comment has been removedAnonymous
April 04, 2008
Olá José, Obrigado pelo seu comentário. Apenas permita-me esclarecer um mal entendido: o SQL Server não limita o tamanho dos bancos de dados a 30TB. Em meu texto eu citei este valor como um exemplo de banco de dados grande, mas certamente não é um limite. Perceba que o SQL Server não tem limite no tamanho de base de dados (com exceção do Express Edition). Abraços Pericles RochaAnonymous
August 27, 2008
Pericles, Estou querendo implentar uma solução de Cluster Geográfico aqui na empresa onde trabalho. Se possivel vc tem algum material a respeito dessa implementação? Atenciosamente, Ivo FilhoAnonymous
October 27, 2008
Pessoal o que acontece se o servidor witness parar ? as instancias ficam como estão ou cai tudo?Anonymous
October 28, 2009
Parabéns pelo contéudo postado, realmente foi de grande ajuda, eu estou fazendo uma monografia sobre alta disponibilidade de banco de dados e este material me ajudou em muito a clarear as idéias, valeu mesmo por compartilhar.