Raking through the parallelism tool-shed: the curious case of matrix-matrix multiplication
Part 1 – no sleeves have been rolled during the production of this blog post
Hello ladies and gentlemen, my name is Alex Voicu and I am a software engineer in the Visual C++ Libraries team. This constitutes the first post from what we hope will be an informative series that details the solutions Visual C++ offers in the area of parallel processing, and shows how they can be applied to great effect in the derivation of high-performance implementations of various algorithms. We will strive to offer two perspectives (and by way of consequence, each investigation shall be split in two parts):
first, we will attempt to cull most low-hanging fruits, implementing straightforward tweaks;
second, we shall strive to derive optimised, more involved implementations.
We hope that this approach shall end up providing something of use both for the developer on the hunt for a quick fix, and for the one that is willing to tackle things in-depth. As such, a well rounded out programmer must be adept at throwing coals into the hungry maw of their machine, and our goal shall be to show the tools that Visual Studio offers to aid in this noble quest. Let us start in a straightforward manner, by revisiting matrix – matrix multiplication (henceforth MM), an important primitive that has a knack for showing up in discussions about parallelism.
Since some formal context is generally beneficial, it would be worth our time to establish it. Let A be an M x N matrix, B an N x W matrix and C the result of multiplying A and B, an M x W matrix.
For the sake of simplifying the demonstration, without loss of generality, we further constrain the problem: the elements in A, B and C are real numbers, and M = N = W. Unless otherwise specified, we focus on the float data-type and all measurements shown in this material are taken from the following machine:
Characteristic |
Machine |
CPU |
AMD A10-7850k |
RAM |
16GB DDR3-2133 |
GPU |
AMD R7 |
GPU Drivers |
14.7 RC1 |
Programming Environment |
Visual Studio 14 CTP 2 |
Operating System |
Windows 8.1 Update 1 |
For all the functions that will be shown, you can assume the following interface:
template<typename T>
void MxM(const std∷vector<T>& A, const std∷vector<T>& B, std∷vector<T>& C,
unsigned int M, unsigned int N, unsigned int W)
Having established the above context, we can now engage in a case-by-case discussion.
The most common approach…
If you ever had the curiosity of studying some of the mainstream literature about MM, odds are that you have seen the following loop being presented as a potential implementation:
for (auto i = 0u; i != M; ++i) {
for (auto j = 0u; j != W; ++j) {
T result = 0;
for (auto k = 0u; k != N; ++k) {
result += A[i * N + k] * B[k * W + j];
}
C[i * W + j] = result;
}
}
Nothing wrong with that, is there? At this point, you probably expect us to start throwing multiple cores and GPUs at the issue. However…
... is terrible and should not be used as a basis for anything
The looping structure shown above, sometimes-called ijk loop, is actively bad (from the same family of bad things that Bubble Sort comes from). To see why, do look at the following profiling information obtained via AMD's CodeXL (M = 512, showing data associated with the MxM function):
Counter |
Value |
L1 Data-cache misses |
5352 |
L1 Data-TLB misses |
37 |
L2 Cache-misses |
20 |
Cacheline utilization |
6.32% |
Consider two successive iterations of the innermost loop: B(j, k) and B(j, k + 1) are exactly W elements apart, which is, roughly, W * sizeof(decltype(B(j, k))) bytes too far for efficient usage of the memory hierarchy (note, this does not matter for really small W). The memory hierarchy is used poorly. So how do we get an extremely consistent speed-up, perhaps even up to an order of magnitude? Given the name of this particular blog, you might be expecting to hear something about multiple CPUs or maybe even a GPU…but how about:
for (auto k = 0u; k != N; ++k) {
for (auto i = 0u; i != M; ++i) {
const auto r = A[i * N + k];
for (auto j = 0u; j != W; ++j) {
C[i * W + j] += r * B[k * W + j];
}
}
}
Seems rather innocuous, does it not? However:
Counter |
Value |
L1 Data-cache misses |
48 |
L1 Data-TLB misses |
2 |
L2 Cache-misses |
4 |
Cacheline utilization |
6.29% |
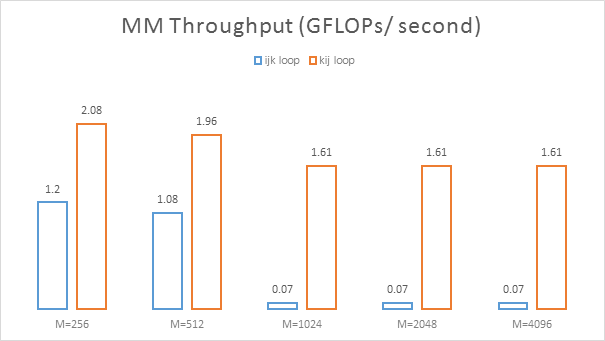 It only took a very simple change to get a major increase in performance – this gives us a proper stick to measure against once we start plucking tools out and using them to optimize. Would it be possible to get a similarly noticeable boost without performing extraordinary feats of surgery? Yes!
It only took a very simple change to get a major increase in performance – this gives us a proper stick to measure against once we start plucking tools out and using them to optimize. Would it be possible to get a similarly noticeable boost without performing extraordinary feats of surgery? Yes!
Vectorize mine workload!
An interesting series of articles by Jim Hogg talks about the auto-vectorising capabilities embedded in the Visual Studio C++ compiler. The following statements are hope inducing:
"Auto-vectorization is on by-default. You don't need to request this speedup. You don't need to throw a compiler switch. You don't need to set environment variables or registry entries. You don't need to change your C++ code. You don't need to insert #pragmas. The compiler just goes ahead and does it. It all comes for free."
If the above holds, we might have stumbled upon the first counter-proof to the "There is No Such Thing As A Free Lunch" axiom! Perhaps our simple code is already taking advantage of this feature – let's find out by adding /Qvec-report:2 to the command-line:
// info C5002: loop not vectorized due to reason '1304'
Hmm, perhaps free lunches are not that easy to come by after all – a quick check through the vectorizer error message decoder tells us that the mysterious 1304 reason suggests that our loop body includes assignments of heterogeneous size, which is odd since we are adding to a T the result of multiplying two Ts. Well, to be exact, we are multiplying a const T with a const T& and adding the result to a T&, which in theory should not be at all confusing in the parts of the world where the vectorizer roams, but that's a story for another day. For now, we would still like our lunch, even if it's not completely free, and to get it we incur the potential cost of an extra load / temporary and make the addition explicit:
for (auto k = 0u; k != N; ++k) {
for (auto i = 0u; i != M; ++i) {
const auto r = A[i * N + k];
for (auto j = 0u; j != W; ++j) {
C[i * W + j] = C[i * W + j] + r * B[k * W + j];
}
}
}
// info C5002: loop not vectorized due to reason '1203'
Close, but no cigar yet – reason 1203 has to do with non-contiguous accessing of arrays. Fair enough, whilst on a conceptual level we know that within the innermost loop we are practically linearly traversing B and C with unit stride, our fellow compiler might be confused by the explicit address calculation we are doing within the subscript operator. Let us give it a hand and hoist the row computation outside of the loop, and see if it worked:
for (auto i = 0u; i != M; ++i) {
const auto row_A = i * N;
const auto row_C = i * W;
for (auto k = 0u; k != N; ++k) {
const auto row_B = k * W;
const auto r = A[row_A + k];
for (auto j = 0u; j != W; ++j) {
C[row_C + j] = C[row_C + j] + r * B[row_B + j];
}
}
}
// info C5001: loop vectorized
Success, but was it worth it? Let us find out:
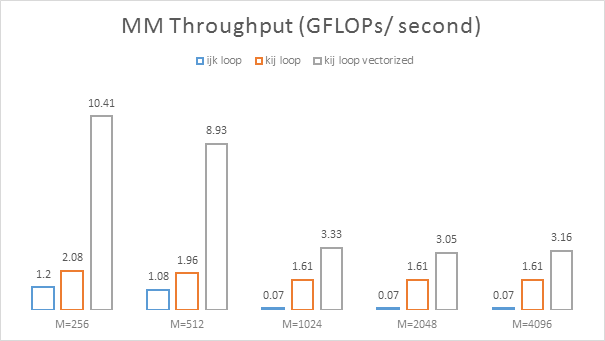 Not too shabby, and it was not so hard to get our auto-vectorising friend to play nice, albeit we promise to make it even more straightforward in the future. However, you might be curious as to why there is such a sharp drop in throughput as size increases. Perhaps we can find out if we look at what is happening in the memory hierarchy at the two extremes:
Not too shabby, and it was not so hard to get our auto-vectorising friend to play nice, albeit we promise to make it even more straightforward in the future. However, you might be curious as to why there is such a sharp drop in throughput as size increases. Perhaps we can find out if we look at what is happening in the memory hierarchy at the two extremes:
Counter |
M = 512 |
M = 4096 |
L1 Data-cache misses |
8 |
96446 |
L1 Data-TLB misses |
0 |
2768 |
L2 Cache-misses |
0 |
9028 |
Cacheline utilization |
24.41% |
25.09% |
Ah, it appears that the larger problem sizes blow us out of the cache hierarchy, whereas for small problems we are executing out of the L1 cache. Is there a way to work around this? Yes, as we shall see in part 2 (all those in the back yelling "Blocking!", please have some patience). For now, let us assume that we have extracted a reasonable amount of what a single CPU core can give us (it is quite an assumption, but bear with us) – it is now time to torment all the available CPU cores!
If you have multiple hammers, what does everything look like?
The somewhat coarser, blunter, relative of the auto-vectorizer is the auto-parallelizer, which takes care of spreading the work across CPU cores. It is also a tool that has definite theoretical appeal – just add a little pragma and voilà, the CPU is flexing harder than a Mister Olympia contestant is. Unlike the vectorizer, the parallelizer is not on by default, requiring one to add the /Qpar compiler flag. So let us take our vectorized loop, and open the gates of the parallel flood, using Qpar-report:2 to see if we are actually achieving anything:
#pragma loop(hint_parallel(0))
for (auto i = 0u; i != M; ++i) {
const auto row_A = i * N;
const auto row_C = i * W;
for (auto k = 0u; k != N; ++k) {
const auto row_B = k * W;
const auto r = A[row_A + k];
for (auto j = 0u; j != W; ++j) {
C[row_C + j] = C[row_C + j] + r * B[row_B + j];
}
}
}
// info C5012: loop not parallelized due to reason '1007'
Note that we aim to parallelize the outer loop, which iterates across rows of C, thus macro-partitioning the problem by rows. Whilst there are definitely better partitioning rules, this is not an awful start, or rather it would not have been one had it worked. Alas, the compiler tells us that we are breaking one of its rules, and decoding the error message (link to the auto-par message list) we find out that it is only fond of signed integral quantities when it comes to induction variables and loop bounds. OK mister compiler, have it your way:
for (int i = 0; i != M; ++i) {
…
}
// info C5012: loop not parallelized due to reason '1000'
We appear to have stumbled upon a case of nanny-ism gone wrong: it appears that our loop contains data dependencies. While that is an interesting assertion, and frequently correct, this time it is wrong: each iteration of the loop writes to a different row of C, with no overlap. Fortunately, we can convey our knowledge by way of another pragma, which turns off dependency checking, and perhaps now we can get this show on the road:
#pragma loop(hint_parallel(0))
#pragma loop(ivdep)
for (auto i = 0u; i != M; ++i) {
const auto row_A = i * N;
const auto row_C = i * W;
for (auto k = 0u; k != N; ++k) {
const auto row_B = k * W;
const auto r = A[row_A + k];
for (auto j = 0u; j != W; ++j) {
C[row_C + j] = C[row_C + j] + r * B[row_B + j];
}
}
}
// info C5011: loop parallelized
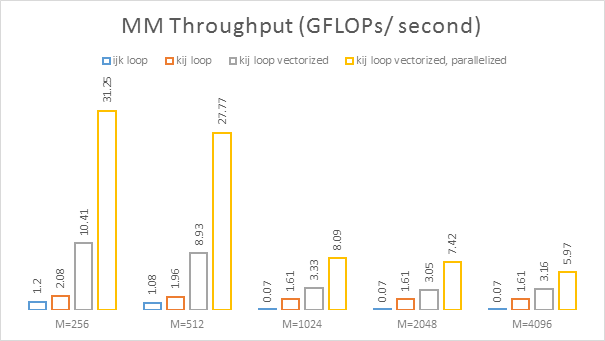 Note that at the upper end of the range the performance decay is more pronounced for the parallelized case. This exposes one of the potential perils of parallel execution (with shared resources, as is the case for the L2 cache – across 2 "cores" - and the memory interface – across the entire chip):
Note that at the upper end of the range the performance decay is more pronounced for the parallelized case. This exposes one of the potential perils of parallel execution (with shared resources, as is the case for the L2 cache – across 2 "cores" - and the memory interface – across the entire chip):
Counter |
M = 4096 |
L2 Cache-misses |
18665 |
Considering the limited amount of effort (a line swapped there, a few variables here etc.), we dare say that the bottom-line up to this point is not terrible, getting an order of magnitude improvement versus the base case. Are we done yet? Almost!
Un-cuffing ever so slightly (AKA a taste of things to come in part 2)
If you have been around these parts in the past, or elsewhere, you might have heard about C++ AMP, Microsoft's solution for exploiting the notable parallel throughput offered by modern GPUs. If you have not, at this point you are probably terrified, thinking about all sorts of verbose C-isms invading the text, with alien APIs attacking you. Have no fear and peek below to see that programming GPUs does not have to be a scary affair (although it is admittedly a smidgeon more challenging that sprinkling pragmas):
using namespace concurrency;
// Wrap data for implicit copying to / from the accelerator.
array_view<const T, 2> av_a(M, N, va);
array_view<const T, 2> av_b(N, W, vb);
array_view<T, 2> av_c(M, W, vc);
av_c.discard_data(); // Do not copy C in, as we're overwriting it.
// Compute – outer 2 for loops of CPU is replaced by a parallel_for_each.
parallel_for_each(av_c.extent, [=](const index<2>& idx) restrict(amp) {
T result = 0;
const auto row_A = idx[0];
const auto col_B = idx[1];
for (int i = 0; i != av_a.extent[1]; ++i) {
result += av_a(idx[0], i) * av_b(i, idx[1]);
}
av_c[idx] = result; // See what we did here:)?
});
 We shall not delve into the C++ AMP code too much, as there are thorough explanations of what is what in AMP land and retaining variable naming makes it easy to follow what is happening. What you should be aware of is that this is the equivalent of the rather terrible ijk loop as far as C++ AMP MM goes, and we are showing it mostly so that we criticise it in the next instalment. This bites us in the M = 4096 case, where execution takes too long and triggers a TDR. Even so, it is interesting to see that it manages to end up faster than all our other (simple) attempts. For some workloads, you would be wise to investigate that parallel grunt – it is not that hard!
We shall not delve into the C++ AMP code too much, as there are thorough explanations of what is what in AMP land and retaining variable naming makes it easy to follow what is happening. What you should be aware of is that this is the equivalent of the rather terrible ijk loop as far as C++ AMP MM goes, and we are showing it mostly so that we criticise it in the next instalment. This bites us in the M = 4096 case, where execution takes too long and triggers a TDR. Even so, it is interesting to see that it manages to end up faster than all our other (simple) attempts. For some workloads, you would be wise to investigate that parallel grunt – it is not that hard!
A cold shower
Before closing off this first instalment, we do need to establish some context. Up to now, we have been operating in a void, ignoring the fact that there are quite a few BLAS level-3 libraries around that offer fast implementations of their own. It would not be bad to see how our feeble efforts fare when compared to the professionals. For the sake of comparison, we chose two libraries: the vendor neutral Eigen 3.2.2 and AMD's ACML 6:
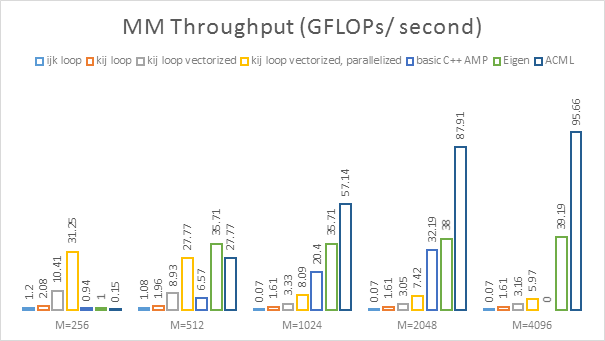 It does appear that as nice as it is to keep sleeves where they belong, that does not allow one to properly play with the "big-boys". Otherwise stated, if you have a feasible library solution on hand, and for some reason are unwilling to get your hands dirty in the slightest, use the library and do not look back! If you do not have a library available, try some of the handy, easy to use tools we have presented today (after you have made sure your algorithm is not terrible). If you are actually serious about putting forth your own high-flying parallel implementation of an algorithm or another, come back for the subsequent instalments, in which we will attempt to put the pedal closer to the metal.
It does appear that as nice as it is to keep sleeves where they belong, that does not allow one to properly play with the "big-boys". Otherwise stated, if you have a feasible library solution on hand, and for some reason are unwilling to get your hands dirty in the slightest, use the library and do not look back! If you do not have a library available, try some of the handy, easy to use tools we have presented today (after you have made sure your algorithm is not terrible). If you are actually serious about putting forth your own high-flying parallel implementation of an algorithm or another, come back for the subsequent instalments, in which we will attempt to put the pedal closer to the metal.
Comments
Anonymous
September 12, 2014
Eagerly awaiting part two... though it is a little alarming how poorly Eigen and ACML appear to perform for small matrices. I'd expect a well tuned blas library to at least perform on par with the vectorized (grey) code if not closer to the parallel (yellow) code.Anonymous
September 22, 2014
I second Adam's response. Eagerly awaiting part two and likewise bewildered by the poor performance of the 'big boys' when it comes to small M values.Anonymous
September 25, 2014
That's probably because they use Strassen multiplication at the larger matrix sizes: en.wikipedia.org/.../Strassen_algorithmAnonymous
September 25, 2014
The comment has been removed