Implementing a SharePoint XML Indexing Connector
Most organizations have several systems holding their data. Data from these systems must be indexable and made available for search on the common Internal Search portal. While most of the different data silos are able to dump or export their full dataset as XML, SharePoint does not include an OOTB general purpose XML indexing connector.
The SharePoint Server Search Connector Framework is known to be overly complex, and documentation out there about this subject is very limited. There are basically two types of custom search connectors for SharePoint 2010 that can be implemented; the .Net Assembly Connector and the Custom Connector. More details about the differences between them can be found here. Mainly, a Custom Connector is agnostic of external content types, whereas each .NET Assembly Connector is specific to one external content type, and whenever the external content type changes, the .Net Assembly Connector must be re-compiled and re-deployed. If the entity model of the external system is dynamic and is large scale a Custom Connector should be considered over the .Net Assembly Connector. Also, a Custom Connector provides administration user interface integration, but a .NET Assembly Connector does not.
The XML File Indexing Connector
The XML File Indexing Connector that is presented here is a custom search indexing connector that can be used to crawl and index XML files. In this series of posts I am going to first show you how to install, setup and configure the connector. In future posts I will go into more implementation details where we’ll look into code to see how the connector is implemented and how you can customize it to suit specific needs.
This post is divided into the following sections:
- Installing and deploying the connector
- Creating a new Content Source using the connector
- Using the Start Address of the Content Source to configure the connector
- Automatic and dynamic generation of Crawled Properties from XML elements
- Full Crawl vs. Incremental Crawl
- Optimizations and considerations when crawling large XML files
- Future plans
Installing and deploying the connector
The package that can be downloaded at the bottom of this post, includes the following components:
- model.xml: This is the BCS model file for the connector
- XmlFileConnector.dll: This is the DLL file of the connector
- The Folder XmlFileConnector: This includes the Visual Studio Solution of the connector
Follow these steps to install the connector:
1. Install the XmlFileConnector.dll in the Global Assembly Cache on the SharePoint application server(s)
gacutil -i "XmlFileConnector.dll"
2. Open the SharePoint 2010 Management Shell on the application server.
3. At the command prompt, type the following command to get a reference to your FAST Content SSA.
$fastContentSSA = Get-SPEnterpriseSearchServiceApplication -Identity "FASTContent SSA"
4. Add the following registry key to the application server
[HKEY_LOCAL_MACHINE]\SOFTWARE\Microsoft\OfficeServer\14.0\Search\Setup\ProtocolHandlers\xmldoc
Set the value of the registry key to “OSearch14.ConnectorProtocolHandler.1”
5. Add the new Search Crawl Custom Connector
New-SPEnterpriseSearchCrawlCustomConnector -SearchApplication $fastContentSSA –Protocol xmldoc -Name xmldoc -ModelFilePath "XmlFileConnector\Model.xml"
7. Restart the SharePoint Server Search 14 service. At the command prompt run:
net stop osearch14
net start osearch14
8. Create a new Crawled Property Category for the XML File Connector. Open the FAST Search Server 2010 for SharePoint Management Shell and run the following command:
New-FASTSearchMetadataCategory -Name "Custom XML Connector" -Propset "BCC9619B-BFBD-4BD6-8E51-466F9241A27A"
Note that the Propset GUID must be the one specified above, since this GUID is hardcoded in the Connector code as the Crawled Properties Category which will receive discovered Crawled Properties.
Creating a new Content Source using the XML File Connector
1. Using the Central Administration UI, on the Search Administration Page of the FAST Content SSA, click Content Sources, then New Content Source.
2. Type a name for the content source, and in Content Source Type, select Custom Repository.
3. In Type of Repository select xmldoc.
4. In Start Addresses, type the URLs for the folders that contain the XML files you want to index. The URL should be inserted in the following format:
xmldoc://hostname/folder_path/#x=:doc:id;;urielm=url;;titleelm=title#
The following section describes the different parts of the Start Address.
Using the Start Address of the Content Source to configure the connector
The Start Address specified for the Content Source must be of the following format. The XML File Connector will read this Start Address and use them when crawling the XML content.
xmldoc://hostname/folder_path/#x=:doc:id;;urielm=url;;titleelm=title#
xmldoc
xmldoc is the protocol corresponding to the registry key we added when installing the connector.
//hostname/folder_path/
//hostname/folder_path/ is the full path to the folder conaining the XML files to crawl.
Exmaple: //demo2010a/c$/enwiki
#x=doc:id;;urielm=url;;titleelm=title#
#x=doc:id;;urielm=url;;titleelm=title# is the special part of the Start Address that is used as configuration values by the connector:
x=:doc:id
Defines which elements in the XML file to use as document and identifier elements. This configuration parameter is mandatory.
For example, say a we have an XML file as follows:
<feed> <document> <id>Some id</id> <title></title> <url>some url</id> <field1>Content for field1</field1> <field2>Content for field2</field2> </document> <document> ... </document> </feed>
Here the value for the x configuration parameter would be x=:document:id
urielm=url
urielm=url defines which element in the XML file to use as the URL. This will end up as the URL of the document used by the FS4SP processing pipeline and will go into the ”url” managed property. This configuration parameter can be left out. In this case, the default URL of the document will be as follows: xmldoc://id/[id value]
titleelm=title
titleelm=title defines which element in the XML file to use as the Title. This will end up as the Title of the document, and the value of this element will go into the title managed property. This configuration parameter can be left out. If the parameter is left out, then the title of the document will be set to ”notitle”.
Automatic and dynamic generation of Crawled Properties from XML elements
The XML File Connector uses advanced BCS techniques to automatically Discover crawled properties from the content of the XML files.
All elements in the XML docuemt will be created as crawled properties. This provides the ability to dynamically crawl any XML file, without the need to pre-define the properties of the entities in the BCS Model file, and re-deploy the model file for each change.
This is defined in the BCS Model file on the XML Document entity. The TypeDescriptor element named DocumentProperties, defines an list of dynamic property names and values. The property names in this list will automatically be discovered by the BCS framework and corresponding crawled properties will automatically be created for each property.
The following snippet from the BCS Model file shows how this is configured:
<!-- Dynamic Properties -->
<TypeDescriptor Name="DocumentProperties" TypeName="XmlFileConnector.DocumentProperty[], XmlFileConnector, Version=1.0.0.0, Culture=neutral, PublicKeyToken=109e5afacbc0fbe2" IsCollection="true">
<TypeDescriptors>
<TypeDescriptor Name="Item" TypeName="XmlFileConnector.DocumentProperty, XmlFileConnector, Version=1.0.0.0, Culture=neutral, PublicKeyToken=109e5afacbc0fbe2">
<Properties>
<Property Name="Property" Type="System.String">xxxxx</Property>
</Properties>
<TypeDescriptors>
<TypeDescriptor Name="PropertyName" TypeName="System.String, mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
<Properties>
<Property Name="PropertyName" Type="System.String">xxxx</Property>
</Properties>
</TypeDescriptor>
<TypeDescriptor Name="PropertyValue" TypeName="System.Object, mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
<Properties>
<Property Name="PropertyValue" Type="System.String">xxxxxx</Property>
</Properties>
</TypeDescriptor>
</TypeDescriptors>
</TypeDescriptor>
</TypeDescriptors>
</TypeDescriptor>
<!-- End of Dynamic Properties -->
In addition to the ability to discover crawled properties automatically from the XML content, the XMl File Connector also creates a default property with the name “XMLContent”. This property contains the raw XML of the document being processed. This enables the use of the XML content in a custom Pipeline extensibility stage for further processing.
Example
Say that we have the following XML file to index.
<feed>
<doc>
<title>Wikipedia: Nobel Charitable Trust</title>
<url>https://en.wikipedia.org/wiki/Nobel_Charitable_Trust</url>
<abstract>The Nobel Charitable Trust (NCT) is a charity set up by members of the Swedish Nobel family, i.e.</abstract>
<links>
<sublink linktype="nav"><anchor>Michael Nobel Energy Award</anchor><link>https://en.wikipedia.org/wiki/Nobel_Charitable_Trust#Michael_Nobel_Energy_Award</link></sublink>
<sublink linktype="nav"><anchor>References</anchor><link>https://en.wikipedia.org/wiki/Nobel_Charitable_Trust#References</link></sublink>
</links>
</doc>
<doc>
...
</doc>
</feed>
When running the connector the first time; we see the following Crawled Properties discovered in the Custom XML Connector Crawled Properties Category.
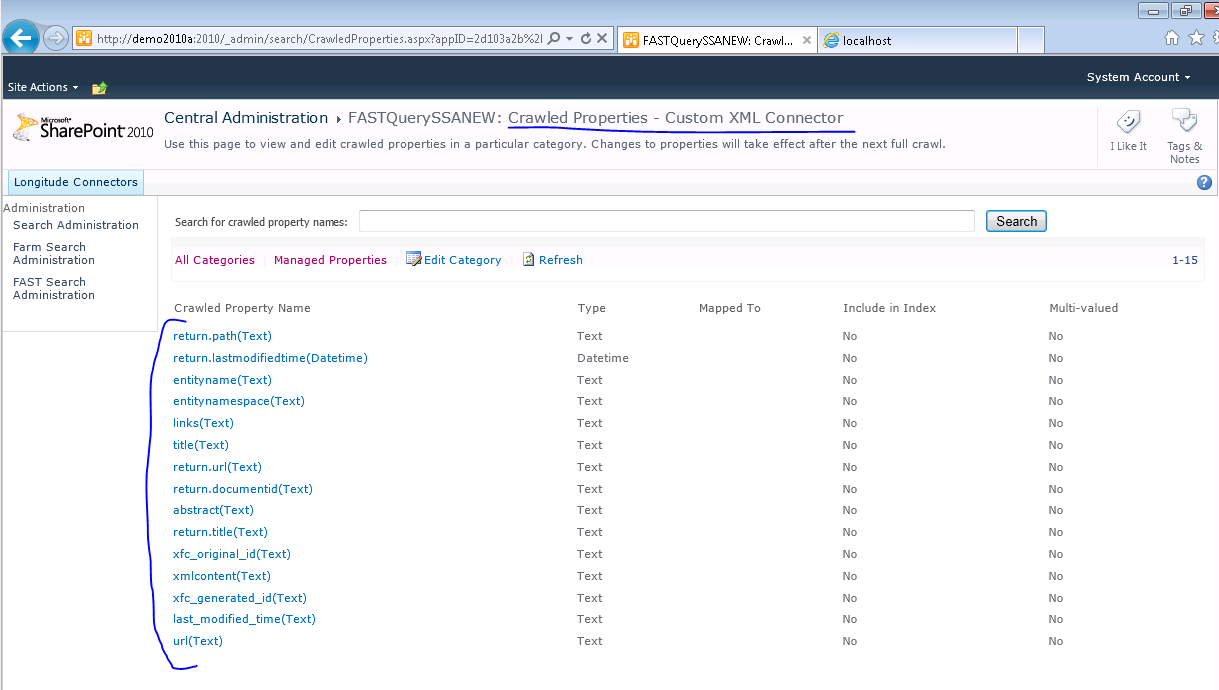
Full Crawl vs. Incremental Crawl
The BCS Search Connector Framework is implemented in such a way that keeps track of all crawled content in the Crawl Log Database. For each search Content Source, a log of all document ids that have been crawled is stored. This log is used when running subsequent crawls of the content source, be it either a full or an incremental crawl.
When running an incremental crawl, the BCS framework compares the list of document ids it received from the connector against the list of ids stored in the crawl log database. If there are any document ids within the crawl log database that have not not been received from the connector, the BCS framework assumes that these documents have been deleted, and will attemp to issue deletion operations to the search system. This will cause many inconsistencies, and will make it very difficult to keep both the actual dataset and the BCS crawl log in sync.
So, when running either a Full Crawl or an Incremental Crawl of the Content Source, the full dataset of the XML files must be available for traversal. If there are any items missing in subsequent crawls, the SharePoint crawler will consider those as subject for deletion, and og ahead and delete those from the search index.
One possible work around to tackle this limitation and try to avoid (re)-generating the full data set each time something minor changes, would be to split the XML content into files of different known update frequences, where content that is known to have higher update rates is placed in separate input folders with separate configured Conetent Sources within the FAST Content SSA.
Optimizations and considerations when crawling large XML files
When the XML File Connector starts crawling content, it will load and parse found XML files one at the time. So, for each XML file found in the input directory, the whole XML file is read into memory and cached for all subsequent operations by the crawler until all items found in the XML file have been submitted to the indexing subsystem. In that case, the memory cache is cleared, and the next file is loaded and parsed until all files have been processed.
For the reason just described, it is recommended not to have large single XML files, but split the content across multiple XML files, each consisting of a number of items the is reasonable and can be easily parsed and cached in memory.
Future plans
- Generalize the connector and build a framework around it.
- Add document Processing capabilities to this connector and framework.
- Upgrade the connector to work with the next version of SharePoint.
Feedback is welcomed!
Enjoy.
Comments
Anonymous
March 18, 2013
The comment has been removedAnonymous
March 18, 2013
Tip: Use the following query to return all the content you fed using the XML File Connector: path:xmldocAnonymous
April 24, 2013
Hi , Thanks for sharing above code pointers ...it was very useful for me to understand how to register a connector ..but when i register the connector as explained above ...i have below error while crawling can you please let me know if am missing anything. "Item not crawled due to one of the following reasons: Preventive crawl rule; Specified content source hops/depth exceeded; URL has query string parameter; Required protocol handler not found; Preventive robots directive. ( This item was deleted because it was excluded by a crawl rule. )"Anonymous
April 24, 2013
Hi , I have specific requirement where i need to index db records and frame a url such that each indexed record of db should have url i.e. http:support/id here id is db record column value ..can we achieve that using custom connector or do default bcs connector to rewrite that using existing protocol handler??Anonymous
June 03, 2013
Thank you ...finally i was able to figure it out....while indexing content using BCS url which is formed by default is of no use for end user but for that work around solution is as below: <MethodInstance Type="IdEnumerator" Name="GetCustomerS" ReturnParameterName="CustomerReadIDS" Default="true" DefaultDisplayName="Customer List Items"> <Properties> <Property Name="DisplayUriField" Type="System.String">uri</Property> </Properties> </MethodInstance> where uri url pulled from your source. Regards, RK