Detecting Overlapping Indexes in SQL Server 2005
When SQL Server has an optimal index that satisfies the search predicates of a query the optimizer performs an index SEEK operation as opposed to an index (or table) scan to retrieve the required rows; this is desirable. Based on this, one may be led to believe that having an index for every possible query predicate set would result in all the queries executing optimally. While true, one has to keep in mind that the indexes need to be maintained when the underlying table data in the column included in the index changes, which amounts to overhead for the database engine. So as you may guess, there are advantages of having indexes, but having too many can result in excessive overhead. This implies that you need to carefully evaluate the pros and cons before creating indexes.
In your first evaluation scenario you clearly want to avoid the case of having overlapping indexes as there is no additional value that an overlapping index provides. For example, consider a table ‘TabA’ and its three associated indexes created with the following definitions.
CREATE TABLE TabA
( Col1 INT, Col2 INT, Col3 INT, Col4 INT );
GO
CREATE INDEX idx1 ON TabA ( Col1, Col2, Col3 );
CREATE INDEX idx2 ON TabA ( Col1, Col2 );
CREATE INDEX idx3 ON TabA ( Col1 DESC, Col2 DESC );
GO
In the table structure above, the index idx1 is a superset (overlap) of the index idx2 and therefore redundant. As can be expected any query that needs to perform a search on Col1 and Col2 could use index idx1 just as well as the index idx2 as seen in the graphical query plan below.
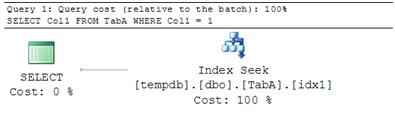
Such overlapping indexes are often a result of multiple developers working on the same product and not evaluating and understanding the existing schema before making additions. Once created, detecting such overlapping indexes in a database can often be a laborious task requiring detailed analysis. More importantly, most DBAs do not like to disable or drop indexes because they are not certain of the queries they were created to help with and fear the side effects the action may have.
The script below uses the new system catalog introduced in SQL Server 2005 to report all duplicate indexes in the current database context.
CREATE FUNCTION dbo.INDEX_COL_PROPERTIES (@TabName nvarchar(128), @IndexId INT, @ColId INT)
RETURNS INT
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @IsDescending INT;
SELECT @IsDescending = is_descending_key
FROM sys.index_columns SYSIDXCOLS
WHERE OBJECT_ID(@TabName) = SYSIDXCOLS.object_id
AND @IndexId = SYSIDXCOLS.index_id
AND @ColId = SYSIDXCOLS.key_ordinal;
-- Return the value of @IsDescending as the property
RETURN(@IsDescending);
END;
GO
-- Find Duplicate Indexes in SQL Server Database
CREATE VIEW IndexList_VW AS
SELECT
SYSSCH.[name] AS SchemaName,
SYSOBJ.[name] AS TableName,
SYSIDX.[name] AS IndexName,
SYSIDX.[is_unique] AS IndexIsUnique,
SYSIDX.[type_desc] AS IndexType,
SYSIDX.[is_disabled] AS IsDisabled,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 1 ) AS Column1,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 2 ) AS Column2,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 3 ) AS Column3,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 4 ) AS Column4,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 5 ) AS Column5,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 6 ) AS Column6,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 7 ) AS Column7,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 8 ) AS Column8,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 9 ) AS Column9,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 10 ) AS Column10,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 11 ) AS Column11,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 12 ) AS Column12,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 13 ) AS Column13,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 14 ) AS Column14,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 15 ) AS Column15,
INDEX_COL( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 16 ) AS Column16,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 1 ) AS Column1_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 2 ) AS Column2_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 3 ) AS Column3_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 4 ) AS Column4_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 5 ) AS Column5_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 6 ) AS Column6_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 7 ) AS Column7_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 8 ) AS Column8_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 9 ) AS Column9_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 10 ) AS Column10_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 11 ) AS Column11_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 12 ) AS Column12_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 13 ) AS Column13_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 14 ) AS Column14_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 15 ) AS Column15_Prop,
dbo.INDEX_COL_PROPERTIES( SCHEMA_NAME(SYSOBJ.SCHEMA_ID)+'.'+SYSOBJ.[name], SYSIDX.index_id, 16 ) AS Column16_Prop
FROM sys.indexes SYSIDX INNER JOIN sys.objects SYSOBJ ON SYSIDX.[object_id] = SYSOBJ.[object_id]
INNER JOIN sys.schemas SYSSCH ON SYSOBJ.schema_id = SYSSCH.schema_id
WHERE SYSIDX.index_id > 0
AND INDEXPROPERTY(SYSOBJ.[object_id], SYSIDX.[name], 'IsStatistics') = 0
GO
SELECT
vwA.SchemaName,
vwA.TableName,
vwA.IndexIsUnique,
vwA.IndexType,
vwA.IndexName,
vwB.IndexName AS OverlappingIndex,
vwA.Column1, vwA.Column2, vwA.Column3, vwA.Column4, vwA.Column5, vwA.Column6, vwA.Column7, vwA.Column8,
vwA.Column9, vwA.Column10, vwA.Column11, vwA.Column12, vwA.Column13, vwA.Column14, vwA.Column15, vwA.Column16
FROM IndexList_VW vwA INNER JOIN IndexList_VW vwB ON vwA.TableName=vwB.TableName
AND vwA.IndexName <> vwB.IndexName
AND vwA.IsDisabled = 0
AND vwB.IsDisabled = 0
AND (vwA.Column1=vwB.Column1 AND vwA.Column1_Prop=vwB.Column1_Prop)
AND ((vwA.Column2=vwB.Column2 AND vwA.Column2_Prop=vwB.Column2_Prop) OR vwA.Column2 IS NULL OR vwB.Column2 IS NULL)
AND ((vwA.Column3=vwB.Column3 AND vwA.Column3_Prop=vwB.Column3_Prop) OR vwA.Column3 IS NULL OR vwB.Column3 IS NULL)
AND ((vwA.Column4=vwB.Column4 AND vwA.Column4_Prop=vwB.Column4_Prop) OR vwA.Column4 IS NULL OR vwB.Column4 IS NULL)
AND ((vwA.Column5=vwB.Column5 AND vwA.Column5_Prop=vwB.Column5_Prop) OR vwA.Column5 IS NULL OR vwB.Column5 IS NULL)
AND ((vwA.Column6=vwB.Column6 AND vwA.Column6_Prop=vwB.Column6_Prop) OR vwA.Column6 IS NULL OR vwB.Column6 IS NULL)
AND ((vwA.Column7=vwB.Column7 AND vwA.Column7_Prop=vwB.Column7_Prop) OR vwA.Column7 IS NULL OR vwB.Column7 IS NULL)
AND ((vwA.Column8=vwB.Column8 AND vwA.Column8_Prop=vwB.Column8_Prop) OR vwA.Column8 IS NULL OR vwB.Column8 IS NULL)
AND ((vwA.Column9=vwB.Column9 AND vwA.Column9_Prop=vwB.Column9_Prop) OR vwA.Column9 IS NULL OR vwB.Column9 IS NULL)
AND ((vwA.Column10=vwB.Column10 AND vwA.Column10_Prop=vwB.Column10_Prop) OR vwA.Column10 IS NULL OR vwB.Column10 IS NULL)
AND ((vwA.Column11=vwB.Column11 AND vwA.Column11_Prop=vwB.Column11_Prop) OR vwA.Column11 IS NULL OR vwB.Column11 IS NULL)
AND ((vwA.Column12=vwB.Column12 AND vwA.Column12_Prop=vwB.Column12_Prop) OR vwA.Column12 IS NULL OR vwB.Column12 IS NULL)
AND ((vwA.Column13=vwB.Column13 AND vwA.Column13_Prop=vwB.Column13_Prop) OR vwA.Column13 IS NULL OR vwB.Column13 IS NULL)
AND ((vwA.Column14=vwB.Column14 AND vwA.Column14_Prop=vwB.Column14_Prop) OR vwA.Column14 IS NULL OR vwB.Column14 IS NULL)
AND ((vwA.Column15=vwB.Column15 AND vwA.Column15_Prop=vwB.Column15_Prop) OR vwA.Column15 IS NULL OR vwB.Column15 IS NULL)
AND ((vwA.Column16=vwB.Column16 AND vwA.Column16_Prop=vwB.Column16_Prop) OR vwA.Column16 IS NULL OR vwB.Column16 IS NULL)
ORDER BY
vwA.TableName, vwA.IndexName
GO
-- Drop function and view created above.
DROP FUNCTION dbo.INDEX_COL_PROPERTIES
GO
DROP VIEW IndexList_VW
GO
Executing the script in a test database with the table (TabA) mentioned above produces output similar to the following.

Indexes idx1 and idx2 are reported to have an overlap, and in this case the subset index that has fewer columns (idx2) can be disabled without any negative side-effects (provided there are no Index hints pointing to this index. This is explained in more detail below). This will result in the same performance for select statements but eliminate the overhead of the database engine having to maintain 2 indexes that serve the same general purpose. This is particularly important if the underlying columns (Col1 and Col2) are highly volatile.
A couple of additional points to keep in mind when using this script:
- Overlapping indexes are only those that have the columns in the same order. For example an index created on Col1, Col2, Col3 (in that order) does not overlap with an index created on Col2, Col1, Col3, even though the columns included are the same
- Indexes created on the same set of columns with the same column order, but with different sort order specifications (ASC, DESC) are distinct indexes and are not overlapping
- Indexes with included columns introduced in SQL Server 2005 are correctly reported as overlapping by the above script. For example, an index created as Col1, Col2 and Col3 as an included column overlaps with the index created on Col1, Col2, Col3. For overlapping indexes that involve included columns it is imperative to disable or drop the index with the higher number of included columns (refer to: https://msdn2.microsoft.com/en-us/library/ms188783(SQL.90).aspx for more information about indexes with included columns)
- Clustered indexes and non-clustered indexes are clearly marked in the script output. If a clustered index is reported as overlapped and you plan to drop it, you may want to take some additional steps to make sure that the overlapping index, or some other index, is created as clustered, because it is a SQL Server best practice to have a clustered index on every table (refer to: https://www.microsoft.com/technet/prodtechnol/sql/bestpractice/clusivsh.mspx for more information)
- It is recommended to either disable a duplicate index or save its definition before dropping it, in order to be able to recreate it if necessary
- Before disabling or dropping an index you should make sure that there are no index hints in your application that explicitly use the index being disabled, for example: SELECT * FROM TabA WITH (INDEX (idx2)) WHERE col1 = 28. Disabling or dropping an index that is explicitly used via an index hint will result in the query execution failing with an error message 308 or 315.
Comments
Anonymous
August 21, 2007
There are a lot of tools in SQL Server 2005 that will help you with indexes, from enhanced plan diagramsAnonymous
May 26, 2008
I’ve noticed that of late I’ve become a bit more critical of a well known publication that I suspectAnonymous
May 05, 2015
The comment has been removed