Making Ruuh, our AI-powered desi chatbot, see and respond to photos like humans
Co-authored by Sonam Damani
Work done in collaboration with Microsoft Research Redmond
![]()
A picture is worth a thousand words, at least to human beings. Machines often struggle to interpret and respond to images the way humans do.
In recent years, Artificial Intelligence (AI)-powered algorithms have combined image recognition with Natural Language Processing (NLP) to caption images presented to them by users. However, these are basic responses with literal descriptions of images and lack the depth or empathy found in human conversations.
With the growing adoption of AI agents and the ubiquitous use of images in communication, it is now essential for machines to interpret and respond to images naturally. To bridge this gap in communication, our team developed a new model for generating natural, human-like comments to images. Integrated with our desi Artificial Intelligence (AI)-based chatbot Ruuh, the model helps her respond to images like a human and hold a free-flowing conversation.
Essentially, this technology can help unlock the potential of AI-enabled assistive tools and facilitate increased user engagement by adding an emotional dimension to image comments. Images across the internet can be made more accessible by providing an emotion-aware description for alternative text (ALT text). Developers can leverage this new technology to create video games that provide players with witty observations on their gameplay, kiosks that provide users comments on their images and artificially-generated cricket commentary. Incorporating image commenting with emotional depth in AI-led interactions could thus add a whole new dimension to user experiences.
The challenge of emotion-aware image commenting
Caption generation is a core element of the AI image(video)-to-text domain. Much of the research in this field has focused on enabling machines to detect and characterize objects in images. Existing deep learning-based image captioning methods extract visual features and recognizable objects from an image and use a language model to create basic sentences or captions for the image. Applying a Recurrent Neural Network (RNN) to these existing models can enable a machine to interpret a series of images and generate a story from them.
However, the existing models do not go any deeper. They describe the objects in the image, any numbers or text, and even recognize human faces or animals. They cannot create a sentence that evokes emotions or differentiate between positive or negative experiences captured by the image.
There have been some attempts towards this direction in the past, like StyleNet (stylized captions), SentiCap (captions with sentiments), VQG (Visual Question Generation), etc. In this work, we extended these models to be able to generate human-like questions or comments based on the style and emotion detected.
The Image Commenting model is a benchmark for human-like comments on images. The comments go beyond descriptive machine-generated responses to express opinions, sentiments and emotions. The objective is to capture the user’s attention and drive engagement in a machine-generated conversation.
How the Image Commenting model works
The datasets for most studies of this nature involve human annotators who apply captions to images. However, such a controlled data generation environment was unsuitable for our model. To collect natural responses to images we extracted more than one million anonymized image-comment pairs from the internet. These pairs were filtered for sensitive material, political statements and adult content. The data was further processed to standardize the content - remove capitalizations, abbreviations and special characters to arrive at the final dataset.
Comparing Image Commenting data to the traditional Microsoft COCO data was a crucial step in ensuring the data was as natural as possible. Our analysis revealed that Image Commenting data was more sentimental and emotional, while the COCO data was more factual. The top word in the Image Commenting dataset was “like” whereas the top word in the COCO set was “sitting”. In fact, many of the most frequently used words in the Image Commenting data were sentimental, such as “love”, “great” and “pretty”. The variation in the length of sentences was more in the Image Commenting dataset, implying that these sentences were less structured and more natural. The conclusion was that Image Commenting data was far more expressive and emotional than COCO.
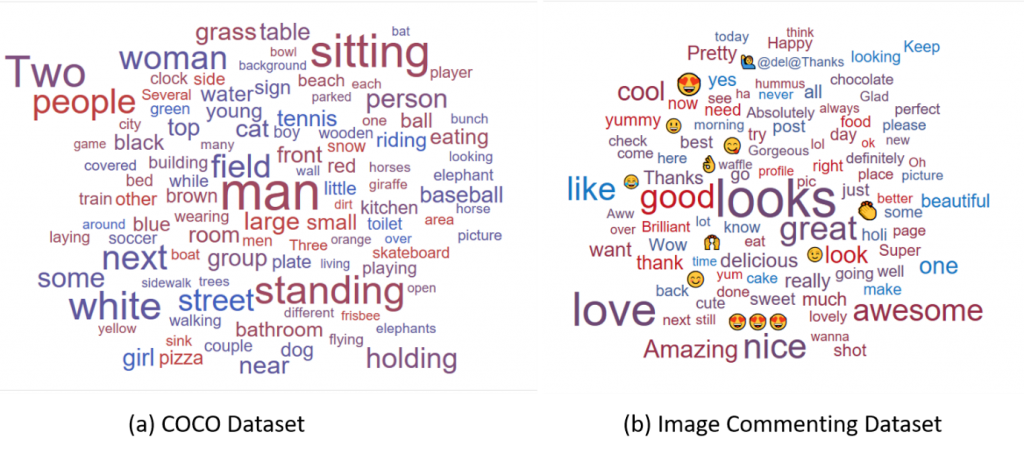
Figure 1. (a) Word cloud of the top words in the COCO dataset, (b) Word cloud of top words in the Image Commenting dataset.
Architecture : The first component is image featurization, where we use ResNet for creating vector representation of images. We use this feature representation along with information from Microsoft Vision API for face recognition, celebrity recognition etc. to extract candidate set of comments from the image-comment index. In the last stage, we used Deep Structured Semantic Model (DSSM) model trained on our dataset for ranking the candidate comments.
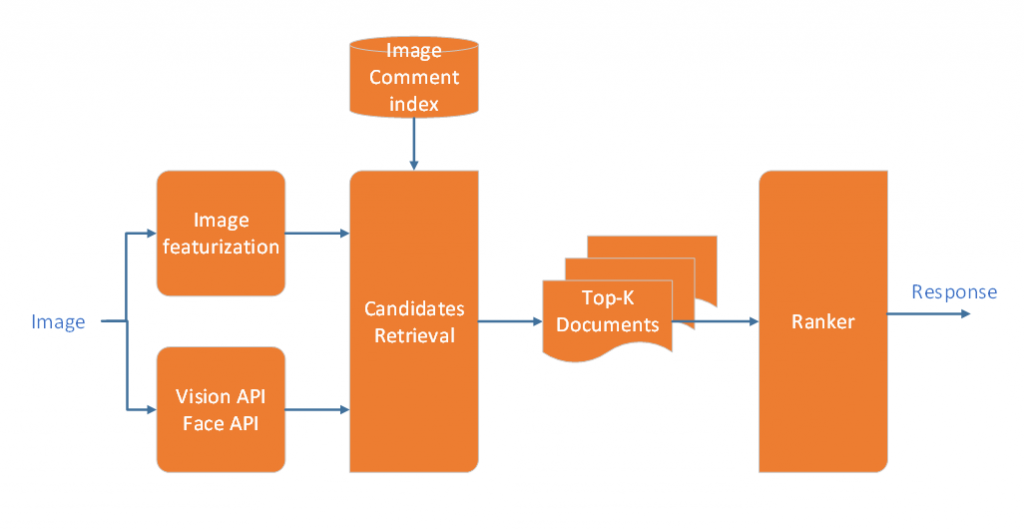
Figure 2. Architecture of the Image Commenting model
Examples: 
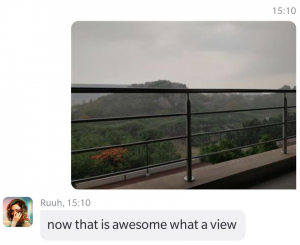
Figure 3. Examples of Image Commenting
Building emotional experiences and engagement with Image Commenting
With Image Commenting, machines can generate comments on images that are not just factual, but also emotive and socially relevant. The key aspect of Image Commenting is that the social language captured in the dataset is critical for making machines converse in a human-like manner.
Integrating the Image Commenting model with commercial conversational systems can enable more engaging applications. Be it visual dialog systems, visual question-answering systems, social chatbots, intelligent personal assistants and other AI-powered assistive tools, it can expand the possibilities of machine engagement with humans.
The ability to respond with an emotional and sentimental understanding and use images to convey meaning, instructions or provide reasoning can enhance the quality of conversations humans have with machines. It can add a new dimension of emotion-driven visual communication to the human-machine relationship and make the experience of using AI more engaging for users.