Creating AI that can respond to questions in mixed languages like humans
“Do Bigha Zameen movie lo protagonist evaru?” Indian readers who speak any combination of Hindi, English, or Tamil, could translate this question with ease - “Who is the protagonist of the movie Do Bigha Zameen?”
The ability to communicate using complex and nuanced languages is one of the most special facets of being human. It is a unique skill that sets us apart as a species and weaves our communities together. However, in multilingual parts of the world, communities are held together by more than just one language.
In India speakers rarely communicate in a single language. Hindi speakers could borrow English words while English speakers could use Tamil phrases to fill the gaps and convey their message more clearly. This form of code-mixing is both common and effortless for people who live in multilingual communities. In fact, the tendency to mix code spills over into digital and social media platforms.
Code-mixing may be natural for multilingual people, but it presents a challenge for current artificial intelligence technologies. Artificial Intelligence (AI)-enabled assistants that are programmed to detect, interpret, and generative responses in natural language are programmed in a single language. The inability to work with several different languages simultaneously makes working with these AI-enabled tools less convenient for multilingual users. To make machines sound more human, this ability to interpret and output mixed code is essential.
The challenge of code-mixing
Teaching machines to splice together multiple languages is challenging. The underlying framework of any AI-based model is created using a single language, mostly English. Code mixed phrases and sentences don’t have a clearly defined structure, syntax, or a universally accepted phonetic protocol. These sentences are more free-flowing and casual, relying on the common heritage of the two speakers. Recreating this through algorithms is a challenge.
Moreover, for code-mixed languages, what further compounds the problem, is the severe paucity of annotated sentences and other important language analysis tools, such as parts of speech taggers, sentence parsers which are required for training AI algorithms to comprehend and understand the semantic meaning.
Solving the lack of appropriate code-mixed data
In collaboration with researchers Khyati Raghavi, Prof. Alan Black from Carnegie Mellon University (CMU), Pittsburg, USA and Prof. Manish Shrivastava from IIIT Hyderabad, we decided to build a QA system for code-mixed languages with minimal language resources. The essence of this approach lies in performing a simple word level translation of the given question into English, which is a resource rich language, and then leveraging the resources available in English for better understanding the intent. Of course, we were aware that word level translations may not be accurate but we still decided to pursue this idea since this might be a good starting point and may also seed the process of collecting some real user question data in code-mixed language which is useful in further tuning and improving our system.
Building WebShodh
Working through this idea, we built an end-to-end web-based Factoid QA system for code mixed languages called WebShodh. WebShodh employs machine learning and deep learning techniques to understand the intent of the question and type of the expected answer which has been expressed in code-mixed language. It currently supports Hinglish and Tenglish translations of questions and is hosted at https://tts.speech.cs.cmu.edu/webshodh/cmqa.php.
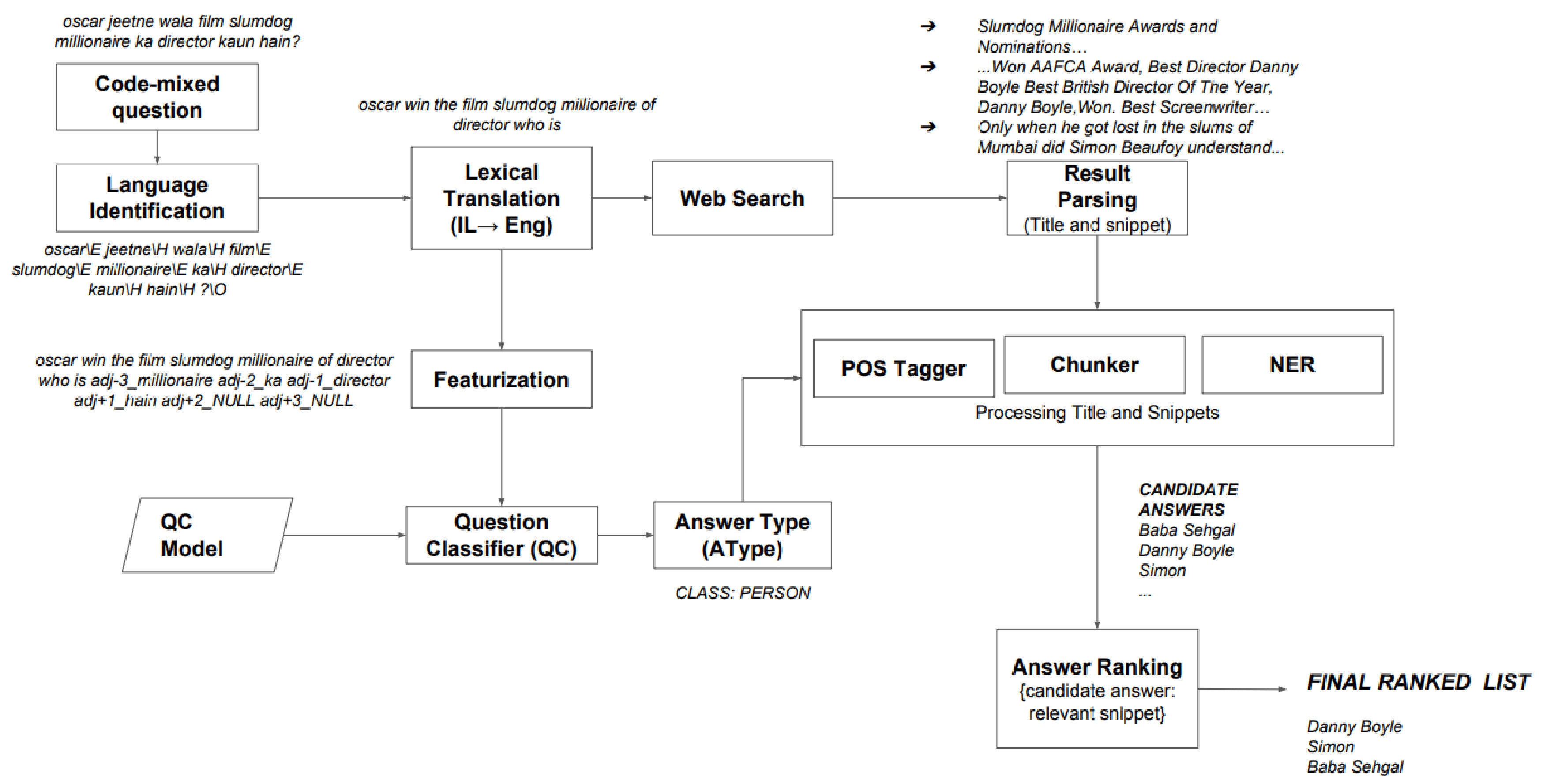
Given a code-mixed question as an input, WebShodh translates all the words into English and runs the translated query through four layers of processing to generate an appropriate response:
- Question Classification: WebShodh applies a Sector Vector Machine (SVM) based QuestionClassifier (QC) which classifies the code-mixed question into one of the given types such as – human, location, entity, abbreviation, description and numeric. Going further, the model runs pre-trained vectors from web news for every word, an analysis of words on either side of ‘wh-’ questions to detect word2vec embedding, and modified parameters in SVM. All these changes lead to a boost in classification accuracy from 63% to 71.96%.
- Web Search: The translated queries are also used as an input in a web search API. The titles, snippets, and URLs of the top ten results are then used as fodder for the answer generation process.
- Answer Generation: To generate candidates for answers, the model runs the titles and snippets generated from the search API through POS tagging, Chunking and Named Entity Recognizer tools. This helps the model narrow down the list of potential answers into a shorter list of most appropriate answers for a given query.
- Answer Ranking: In order to offer only the most relevant answers, the model runs the final list of answer candidates through a ranking process. Each potential response is assigned a relevance score based on its similarity to the translated code-mixed question and all collected search data where the candidate answer occurs.

The WebShodh model was evaluated using 100 questions from Hinglish (a blend of Hindi and English) and Tenglish (a blend of Telugu and English) each. Each dataset was two-thirds native language and one-third English. The evaluation questions were collected from 10 native Hindi and Telugu bi-lingual speakers. The model achieved a Mean Reciprocal Rank (MRR) of 0.37 for Hinglish and 0.32 for Tenglish, which translates to the fact that most of the times, it is able to find the correct answer within the top 3 results.
Creating multilingual digital assistants
Today’s multilingual societies require software tools which support interaction in CM languages. This increases the reach and impact of many product features which are limited today to the users of a few resource-rich languages. WebShodh is a testament that despite severe constraint on resources, AI based systems could still be built for CM languages. WebShodh currently uses very few resources such as bi-lingual dictionaries for the supported languages. Through more online user interactions, WebShodh has the potential to collect more user data using which the system could be re-trained to further boost accuracy of results.
As part of future work, we are contemplating how we can extend this work to support multi-turn and casual conversations. This could pave the way for AI-enabled chatbots and virtual assistants who can interact with human users in a more natural manner. This technology could substantially improve the digital experience of multilingual users who instinctively code-mix their communication. By eliminating the language barrier, these improved models could unlock the potential of AI for millions of users and hundreds of multilingual communities across the world.
Comments
- Anonymous
October 12, 2018
Nice article. MRR of 0.37 is indeed impressive for Hinglish. Keep up the good work.