Running Pleasingly Parallel workloads using rxExecBy on Spark, SQL, Local and Localpar compute contexts
RevoScaleR function rxExec(), allows you to run arbitrary R functions in a distributed fashion, using available nodes (computers) or available cores (the maximum of which is the sum over all available nodes of the processing cores on each node). The rxExec approach exemplifies the traditional high-performance computing approach: when using rxExec, you largely control how the computational tasks are distributed and you are responsible for any aggregation and final processing of results.
In order to achieve coarse grain parallelism using foreach and rxExec(), you would have to split the data using rxSplit() and provide each data-part to each parallel instance of rxExec. Here are some articles to help you do this manually : Coarse Grain Parallelism with foreach and rxExec, Distributed and parallel computing with ScaleR in Microsoft R. This makes rxExec() inefficient to use.
With the release of Microsoft R Server 9.1, we have a new function called rxExecBy()
rxExecBy(inData, keys, func, funcParams = NULL, filterFunc = NULL)
which can be used to partition input data source by keys and apply user defined function on individual partitions. If input data source is already partitioned, we can apply user defined function on partitions directly. A typical family of use cases that is a good fit for this implementation is building a customized machine learning model or models per data partition. rxExecBy() is currently supported in local, localpar, SQL Server and Spark Compute Contexts. The data source objects that can be passed to rxExecBy() using the inData parameter is dependent on the currently active compute context and its supported data source objects. Here is a quick Compute Context Data Source flowchart to understand the different supported scenarios for rxExecBy() :
[caption id="attachment_1005" align="aligncenter" width="861"]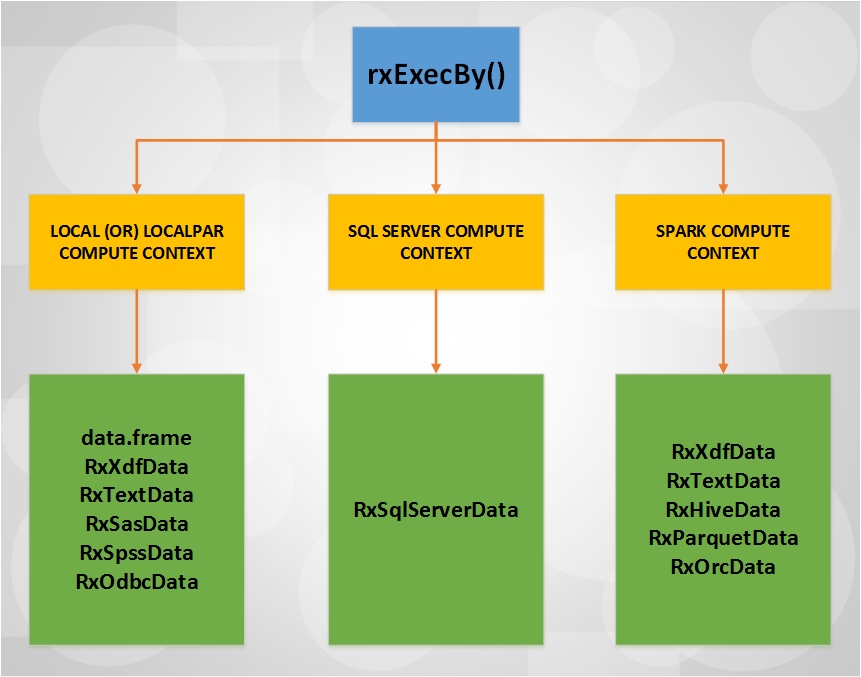 rxExecBy() ComputeContext - DataSource Support FlowChart[/caption]
rxExecBy() ComputeContext - DataSource Support FlowChart[/caption]
Now let us look at code samples for all possible scenarios in the above chart:
SPARK COMPUTE CONTEXT
In this example, we will build a linear model on AirlineDemoSmall Data using lm() function, groupby key DayOfWeek.
NOTE: 'filterFunc' parameter is currently not supported in RxSpark compute context and is ignored for computation.
OUTPUT: 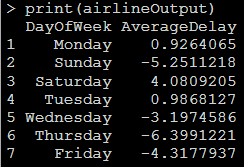
SQL COMPUTE CONTEXT
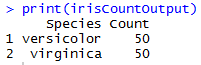
In this example, we will use airlinedemosmall table data, groupby key DayOfWeek and count the number of rows.
OUTPUT: 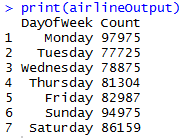
LOCAL (OR) LOCAL PARALLEL COMPUTE CONTEXT
In this example, we will build a linear model on Claims Data using rxLinMod() function, groupby multiple keys (age, type) and filtering out 60+ age and type A.
OUTPUT: 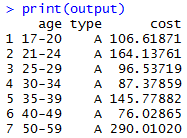
Post co-authored by Premal Shah and Ramkumar Chandrasekaran
For a comprehensive view of all the capabilities in Microsoft R Server 9.1, refer to this blog
Comments
- Anonymous
April 26, 2017
I Have just tested on spark compute context and got the following:Warning message:In rxExecBy(orcData, keys = c("DayOfWeek"), func = .linMod, filterFunc = .dayOfWeekFilter) : 'filterFunc' currently is not supported in RxHadoopMR/RxSpark compute contexts and is ignored for computation in these contexts. - Anonymous
April 26, 2017
Hi Lorea, Thanks for pointing it out. I have updated the code snippet and also included a NOTE.