Sentiment Analysis with a pre-trained model
Harnessing decades of work on cognitive computing in the context of Bing, Office 365 and Xbox, we are delivering the first installment of pre-trained cognitive models that accelerate time to value in Microsoft R Server 9.1. We now offer a Sentiment Analysis pre-trained cognitive model, using which you can assess the sentiment of an English sentence/paragraph with just a few lines of code.
We give a code example using the Stanford Large Movie Review Dataset. The movie reviews are labeled with sentiment and classified as either positive or negative. Our code example demonstrates how to use the getSentiment machine learning transform. Under the cover, getSentiment uses a pre-trained deep neural network model to featurize text and calculate sentiment score. You can then use the calculated sentiment score either directly or as an additional feature to feed to your own sentiment model as demonstrated in our code example.
The code example is run in a local compute context.
We trained two models, rxLogisticRegression and rxFastForest, using their default parameters. Each model has two versions, one includes the preSentiment (sentiment score calculated by getSentiment) as a feature and the other does not. We embedded the featurizeText machine learning transform in each model to extract n-gram features from the text data and directly feed the n-gram features to the model. But alternatively, you can also use the rxFeaturize function to save the n-gram features for reuse.
At the end of the example, ROC curves are produced which shows adding the sentiment score calculated by getSentiment gives you just that much performance gain.
On the validation set: 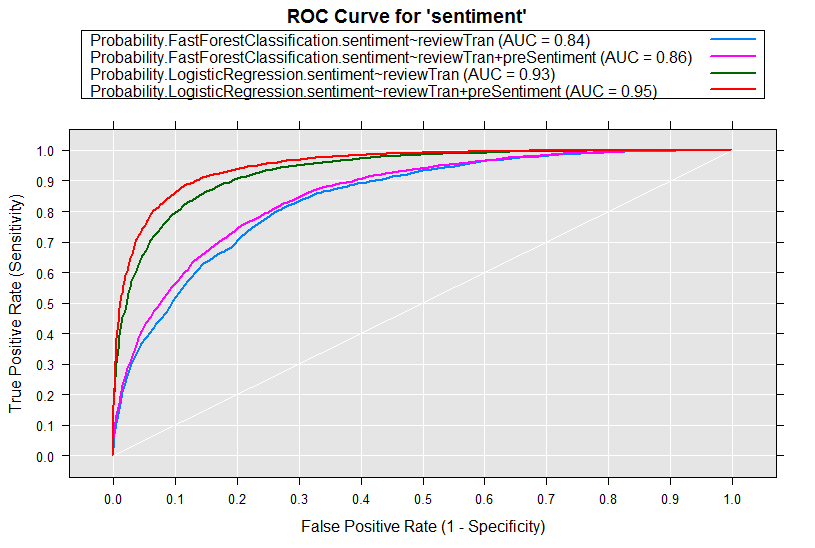
On the test set: 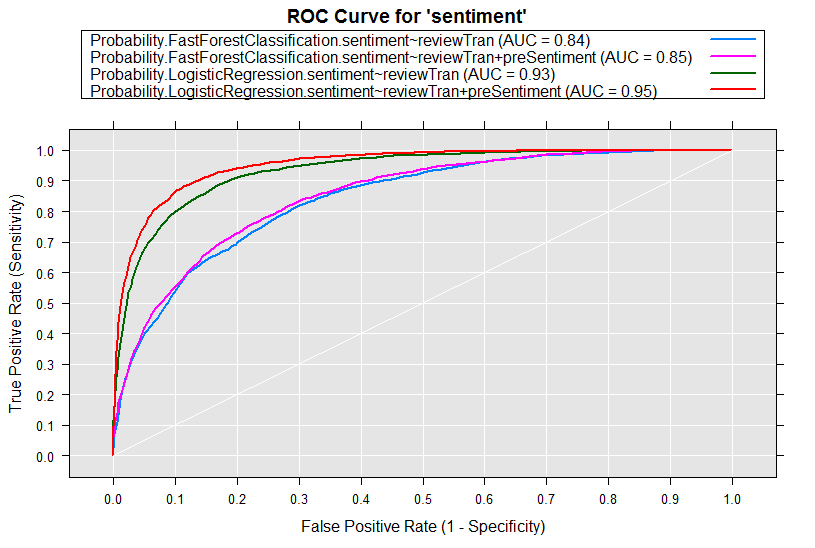
For a comprehensive view of all the capabilities in Microsoft R Server 9.1, refer to this blog.
References Learning Word Vectors for Sentiment Analysis
Authored by Te Zhang and Premal Shah
Comments
- Anonymous
June 06, 2017
The comment has been removed - Anonymous
June 19, 2017
thanks for the post, I am just wondering when is this going to work on Chinese language?